在多核CPU在今天和不久的将来,计算机将拥有更多的内核,Microsoft为了利用这个硬件特性,于是在Visual Studio 2010 和 .NET Framework 4的发布及以上版本中,添加了并行编程这个新特性,我想它以后势必会改变我们的开发方式。
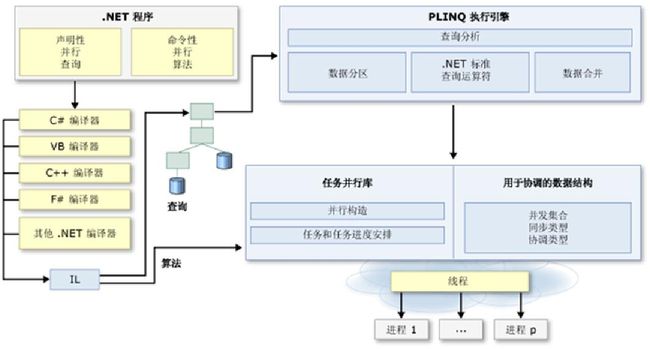
在以前或者说现在,我们在并行开发的时候可能会想到利用多线程和锁技术来做,充分利用多CPU的特性,但是当我们了解并掌握了并行编程技术之后,我们可以不必担心在多线程中的资源死锁和繁琐的DEBUG查找等低级操作。新的并行编程简单了并行开发,使我们可以用新的方法来编程并行运算的代码,从而不必直接去处理线程或者线程池。下图从较高层面上概述了 .NET Framework 4 中的并行编程体系结构。
园子里已经有很多关于LINQ的博客(如一线码农的《8天玩转并行开发》系列,非常感谢这些分享的人。:)),本来是不想再写的,但是想了一下还是写一下吧,算是作为自己的学习笔记了。
下面为并行编程所用到的数据,摘自MSDN。
| 技术 |
说明 |
|---|---|
| 任务并行库 (TPL) |
提供针对 System.Threading.Tasks.Parallel 类的文档(包括 For 和 ForEach 循环的并行版本),还提供了针对 System.Threading.Tasks.Task 类的文档(描绘了表示异步操作的首选方式)。 |
| 并行 LINQ (PLINQ) |
LINQ to Objects 的并行实现,该实现显著提高了许多情况下的性能。 |
| 用于并行编程的数据结构 |
提供一些链接,这些链接指向有关线程安全集合类、轻量同步类型以及延迟初始化类型的文档。 |
| 并行诊断工具 |
提供一些链接,这些链接指向有关 Visual Studio 任务和并行堆栈调试器窗口以及并发可视化工具的文档,其中包含 Visual Studio Application Lifecycle Management 探查器中的一组视图,您可以使用这些视图来调试和调整并行代码的性能。 |
| PLINQ 和 TPL 的自定义分区程序 |
描述分区程序的工作方式,以及如何配置默认分区程序或创建新的分区程序。 |
| 任务工厂 |
描述 System.Threading.Tasks.TaskFactory 类的作用。 |
| 任务计划程序 |
描述计划程序的工作方式,以及如何配置默认计划程序。 |
| 在 PLINQ 和 TPL 中的 Lambda 表达式 |
简要概述 C# 和 Visual Basic 中的 lambda 表达式,并演示如何在 PLINQ 和任务并行库中使用这些表达式。 |
| 其他阅读材料(并行编程) |
提供一些链接,这些链接指向其他文档以及在 .NET Framework 中进行并行编程的示例资源。 |
| .NET Framework 高级读物 |
高级主题(例如线程处理和并行编程)的顶级节点。 |
.Net framework并行编程相关为我们提供了一个新的命名空间:System.Threading.Tasks。
| 类 | 说明 | |
|---|---|---|
| Parallel | 提供对并行循环和区域的支持。 | |
| ParallelLoopState | 可用来使 Parallel 循环的迭代与其他迭代交互。此类的实例由 Parallel 类提供给每个循环;不能在您的用户代码中创建实例。 | |
| ParallelOptions | 存储用于配置 Parallel 类的方法的操作的选项。 | |
| Task | 表示一个异步操作。 | |
| Task |
表示一个可以返回值的异步操作。 | |
| TaskCanceledException | 表示一个用于告知任务取消的异常。 | |
| TaskCompletionSource |
表示未绑定到委托的 Task<TResult> 的制造者方,并通过 Task 属性提供对使用者方的访问。 | |
| TaskExtensions | 提供一组用于处理特定类型的 Task 实例的静态方法(在 Visual Basic 中为共享方法)。 | |
| TaskFactory | 提供对创建和计划 Task 对象的支持。 | |
| TaskFactory |
提供对创建和计划 Task |
|
| TaskScheduler | 表示一个处理将任务排队到线程中的低级工作的对象。 | |
| TaskSchedulerException | 表示一个用于告知由 TaskScheduler 计划的某个操作无效的异常。 | |
| UnobservedTaskExceptionEventArgs | 为在出错的 Task 的异常未观察到时引发的事件提供数据。 |
首先介绍一下并行编程为我们提供的拓展方法
System.Linq.ParallelEnumerable 类为LINQ所能查询的集合IEnumerable提供了拓展方法,让我们更加容易的使用并行查询。如下:
static void Main(string[] args)
{
Random random = new Random();
List<int> intList = new List<int>();
for (int i = 0; i < 100; i++)
{
intList.Add(random.Next(100));
}
//查询大于50的数
var queryResult = from varable in intList.AsParallel()
where varable > 50
select varable;
queryResult.ForAll<int>(tmp => Console.WriteLine(tmp));
}
默认PLINQ使用主机上的所有处理器,若要指定并行处理的最大任务数,可以用拓展方法WithDegreeOfParallelism(int degreeOfParallelism),其中degreeOfParallelism为设置的最大任务数量。degreeOfParallelism默认为CPU的核心数,如果CPU多余64核,而没有手动指定,则为64。
有必要提一下上面用到的ForAll运算符,在普通的LINQ查询中,执行被延迟到Foreach循环中,或通过调用方法ToList(),ToArray()等。在 PLINQ 中,还可以使用 foreach 执行查询和循环访问结果。但是,foreach 本身不会并行运行,因此,它需要将所有并行任务的输出合并回到该循环正在其上运行的线程中。在 PLINQ 中,当必须保留查询结果的最终排序时,以顺序方式处理结果时,以及例如当为每个语句调用 Console.WriteLine 时,必须使用 foreach。为了使不需要保留排序时以及结果的处理可自己并行化时更快地执行查询,请使用 ForAll
PLINQ为我们的查询进行了加速,在编写PLINQ查询需要注意的事项。影响PLINQ查询的因素有下面这些:
1.总体工作的计算开销。
为了实现加速,PLINQ 查询必须具有足够的适合并行工作来弥补开销。工作可表示为每个委托的计算开销与源集合中元素数量的乘积。假定某个操作可并行化,则它的计算开销越高,加速的可能性就越大。例如,如果某个函数执行花费的时间为 1 毫秒,则针对 1000 个元素进行的顺序查询将花费 1 秒来执行该操作,而在四核计算机上进行的并行查询可能只花费 250 毫秒。这样就产生了 750 毫秒的加速。如果该函数对于每个元素需要花费 1 秒来执行,则加速将为 750 秒。如果委托的开销很大,则对于源集合中的很少几个项,PLINQ 可能会提供明显的加速。相反,包含无关紧要委托的小型源集合通常不适合于 PLINQ。
在下面的示例中,queryA 可能适合于 PLINQ(假定其 Select 函数涉及大量工作)。queryB 可能不适合,原因是 Select 语句中没有足够的工作,并且并行化的开销将抵销大部分或全部加速。
var queryA = from num in numberList.AsParallel()
select ExpensiveFunction(num); //good for PLINQ
var queryB = from num in numberList.AsParallel()
where num % 2 > 0
select num; //not as good for PLINQ
总而言之,就是当我们的Select函数有很少的时候,就不要用PLINQ查询了。
2.系统上的逻辑内核数(并行度)。
适合并行的查询在具有更多内核的计算机上运行更快,原因是可以在更多并行线程之间分担工作。加速的总量取决于查询的总体工作中可并行化的百分比。但是,请不要假定所有查询在八核计算机上的运行速度都比在四核计算机的运行速度快两倍。在调整查询以实现最佳性能时,衡量具有多个内核的计算机上的实际结果十分重要。这一点与第一点相关:更大的数据集需要消耗更多的计算资源。
3.操作的数量和种类。
对于必须要保持元素在源序列中的顺序的情况,PLINQ 提供了 AsOrdered 运算符。排序会产生开销,但此开销通常是适度的。GroupBy 和 Join 操作同样也会产生开销。如果允许按任意顺序处理源集合中的元素,并在这些元素就绪时立即将它们传递到下一个运算符,则 PLINQ 的性能最佳。
4.查询的执行形式。
如果要通过调用 ToArray 或 ToList 存储查询的结果,则必须将来自所有并行线程的结果合并为单个数据结构。这会涉及到不可避免的计算开销。同样,如果您使用 foreach循环对结果进行迭代,则需要将来自工作线程的结果序列化到枚举器线程上。但是,如果只需要基于来自每个线程的结果执行某个操作,您可以使用 ForAll 方法在多个线程上执行此工作。
5.合并选项的类型。
可将 PLINQ 配置为将其输出放入缓冲区,并以区块方式或在整个结果集完成后同时生成输出,或者在个别结果生成时流式传送这些结果。前者可缩短总体执行时间,而后者可缩短生成的元素之间的延迟。尽管合并选项并不总是对总体查询性能有很大影响,但是,由于它们控制用户必须等待多长时间才能看到结果,因此可能会对感觉到的性能产生影响。
6.分区的种类。
在某些情况下,针对可建立索引的源集合进行的 PLINQ 查询可能会产生不平衡的工作负载。如果发生这种情况,您也许能够通过创建自定义分区程序来提高查询性能。
下一节,将写一下PLINQ中的分区和自定义分区。