原文链接: https://blog.thinkeridea.com/201902/go/string_ye_shi_yin_yong_lei_xing.html
本文原标题为 《string 也是引用类型》,经过 郝林 大佬指点原标题存在诱导性,这里解释一下 "引用类型" 有两个特征:1、多个变量引用一块内存数据,不创建变量的副本,2、修改任意变量的数据,其它变量可见。显然字符串只满足了 "引用类型" 的第一个特点,不能满足第二个特点,顾不能说字符串是引用类型,感谢大佬指正。
初学 Go 语言的朋友总会在传 []byte 和 string 之间有着很多纠结,实际上是没有了解 string 与 slice 的本质,而且读了一些程序源码,也发现很多与之相关的问题,下面类似的代码估计很多初学者都写过,也充分说明了作者当时内心的纠结:
package main
import "bytes"
func xx(s []byte) []byte{
....
return s
}
func main(){
s := "xxx"
s = string(xx([]byte(s)))
s = string(bytes.Replace([]byte(s), []byte("x"), []byte(""), -1))
}虽然这样的代码并不是来自真实的项目,但是确实有人这样设计,单从设计上看就很糟糕了,这样设计的原因很多人说:“slice 是引用类型,传递引用类型效率高呀”,主要原因不了解两者的本质。
上面这个例子如果觉得有点基础和可爱,下面这个例子貌似并不那么容易说明其存在的问题了吧。
package main
func xx(s *string) *string{
....
return s
}
func main(){
s := "xx"
s = *xx(&s)
ss :=[]*string{}
ss = append(ss, &s)
}指针效率高,我就用指针多好,可以减少内存分配呀,设计函数都接收指针变量,程序性能会有很大提升,在实际的项目中这种例子也不少见,我想通过这篇文档来帮助初学者走出误区,减少适得其反的优化技巧。
slice 的定义
在之前 “【Go】深入剖析slice和array” 一文中说了 slice 在内存中的存储模式,slice 本身包含一个指向底层数组的指针,一个 int 类型的长度和一个 int 类型的容量, 这就是 slice 的本质, []byte 本身也是一个 slice,只是底层数组存储的元素是 byte。下面这个图就是 slice 的在内存中的状态:
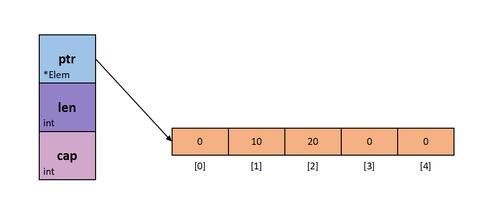
看一下 reflect.SliceHeader 如何定义 slice 在内存中的结构吧:
type SliceHeader struct {
Data uintptr
Len int
Cap int
}slice 是引用类型是 slice 本身会包含一个地址,在传递 slice 时只需要分配 SliceHeader 就好了, 而 SliceHeader 只包含了三个 int 类型,相当于传递一个 slice 就只需要拷贝 SliceHeader,而不用拷贝整个底层数组,所以才说 slice 是引用类型的。
那么字符串呢,计算机中我们处理的大多数问题都和字符串有关,难道传递字符串真的需要那么高的成本,需要借助 slice 和指针来减少内存开销吗。
string 的定义
reflect 包里面也定义了一个 StringHeader 看一下吧:
type StringHeader struct {
Data uintptr
Len int
}字符串只包含了两个 int 类型的数据,其中一个是指针,一个是字符串的长度,从 StringHeader 定义来看 string 并不会发生拷贝的,传递 string 只会拷贝 StringHeader 而已。
借助 unsafe 来分析一下情况是不是这样吧:
package main
import (
"reflect"
"unsafe"
"github.com/davecgh/go-spew/spew"
)
func xx(s string) {
sh := *(*reflect.StringHeader)(unsafe.Pointer(&s))
spew.Dump(sh)
}
func main() {
s := "xx"
sh := *(*reflect.StringHeader)(unsafe.Pointer(&s))
spew.Dump(sh)
xx(s)
xx(s[:1])
xx(s[1:])
}上面这段代码的输出如下:
(reflect.StringHeader) {
Data: (uintptr) 0x10f5ee0,
Len: (int) 2
}
(reflect.StringHeader) {
Data: (uintptr) 0x10f5ee0,
Len: (int) 2
}
(reflect.StringHeader) {
Data: (uintptr) 0x10f5ee0,
Len: (int) 1
}
(reflect.StringHeader) {
Data: (uintptr) 0x10f5ee1,
Len: (int) 1
}可以发现前三个输出的指针都是同一个地址,第四个的地址发生了一个字节的偏移,分析来看传递字符串确实没有分配新的内存,同时和 slice 一样即使传递字符串的子串也不会分配新的内存空间,而是指向原字符串的中的一个位置。
这样说来把 string 转成 []byte 还浪费的一个 int 的空间呢,需要分配更多的内存,真是适得其反呀,而且类型转换会发生内存拷贝,从 string 转为 []byte 才是真的把 string 底层数据全部拷贝一遍呢,真是得不偿失呀。
string 的两个小特性
字符串还有两个小特性,针对字面量(就是直接写在程序中的字符串),会创建在只读空间上,并且被复用,看一下下面的一个小例子:
package main
import (
"reflect"
"unsafe"
"github.com/davecgh/go-spew/spew"
)
func main() {
a := "xx"
b := "xx"
c := "xxx"
spew.Dump(*(*reflect.StringHeader)(unsafe.Pointer(&a)))
spew.Dump(*(*reflect.StringHeader)(unsafe.Pointer(&b)))
spew.Dump(*(*reflect.StringHeader)(unsafe.Pointer(&c)))
}从输出可以了解到,相同的字面量会被复用,但是子串是不会复用空间的,这就是编译器给我们带来的福利了,可以减少字面量字符串占用的内存空间。
(reflect.StringHeader) {
Data: (uintptr) 0x10f5ea0,
Len: (int) 2
}
(reflect.StringHeader) {
Data: (uintptr) 0x10f5ea0,
Len: (int) 2
}
(reflect.StringHeader) {
Data: (uintptr) 0x10f5f2e,
Len: (int) 3
}另一个小特性大家都知道,就是字符串是不能修改的,如果我们不希望调用函数修改我们的数据,最好传递字符串,高效有安全。
不过有了 unsafe 这个黑魔法,字符串的这一个特性也就不那么可靠了。
package main
import (
"fmt"
"reflect"
"strings"
"unsafe"
)
func main() {
a := strings.Repeat("x", 10)
fmt.Println(a)
strHeader := *(*reflect.StringHeader)(unsafe.Pointer(&a))
sliceHeader := reflect.SliceHeader{
Data: strHeader.Data,
Len: strHeader.Len,
Cap: strHeader.Len,
}
b := *(*[]byte)(unsafe.Pointer(&sliceHeader))
b[1] = 'a'
fmt.Println(a)
}从输出里面居然发现字符串被修改了, 我们没有办法直接修改字符串,但是可以利用 slice 和 string 本身结构的特性,创建一个 slice 让它的指针指向 string 的指针位置,然后借助 unsafe 把这个 SliceHeader 转成 []byte 来修改字符串,字符串确实被修改了。
xxxxxxxxxx
xaxxxxxxxx看了上面的例子是不是开始担心把字符串传给其它函数真的不会更改吗?感觉很不放心的样子,难道使用任何函数都要了解它的内部实现吗,其实这种情况极少发生,还记得之前说的那个字符串特性吗,字面量字符串会放到只读空间中,这个很重要,可以保证不是任何函数想修改我们的字符串就可以修改的。
package main
import (
"reflect"
"unsafe"
)
func main() {
defer func() {
recover()
}()
a := "xx"
strHeader := *(*reflect.StringHeader)(unsafe.Pointer(&a))
sliceHeader := reflect.SliceHeader{
Data: strHeader.Data,
Len: strHeader.Len,
Cap: strHeader.Len,
}
b := *(*[]byte)(unsafe.Pointer(&sliceHeader))
b[1] = 'a'
}运行上面的代码发生了一个运行时不可修复的错误,就是这个特性其它函数不能确保输入字符串是否是字面量,也是不会恶意修改我们字符串的了。
unexpected fault address 0x1095dd5
fatal error: fault
[signal SIGBUS: bus error code=0x2 addr=0x1095dd5 pc=0x106c804]
goroutine 1 [running]:
runtime.throw(0x1095fde, 0x5)
/usr/local/go/src/runtime/panic.go:608 +0x72 fp=0xc000040700 sp=0xc0000406d0 pc=0x10248d2
runtime.sigpanic()
/usr/local/go/src/runtime/signal_unix.go:387 +0x2d7 fp=0xc000040750 sp=0xc000040700 pc=0x1037677
main.main()
/Users/qiyin/project/go/src/github.com/yumimobi/test/a.go:22 +0x84 fp=0xc000040798 sp=0xc000040750 pc=0x106c804
runtime.main()
/usr/local/go/src/runtime/proc.go:201 +0x207 fp=0xc0000407e0 sp=0xc000040798 pc=0x1026247
runtime.goexit()
/usr/local/go/src/runtime/asm_amd64.s:1333 +0x1 fp=0xc0000407e8 sp=0xc0000407e0 pc=0x104da51关于字符串转 []byte 在 go-extend 扩展包中有直接的实现,这种用法在 go-extend 内部方法实现中也有大量使用, 实际上因为原数据类型和处理数据的函数类型不一致,使用这种方法转换字符串和 []byte 可以极大的提升程序性能
- exbytes.ToString 零成本的把
[]byte转为string。 - exstrings.UnsafeToBytes 零成本的把
[]byte转为string。
上面这两个函数用的好,可以极大的提升我们程序的性能,关于 exstrings.UnsafeToBytes 我们转换不确定是否是字面量的字符串时就需要确保调用的函数不会修改我们的数据,这往常在调用 bytes 里面的方法十分有效。
传字符串和字符串指针的区别
之前分析了传递 slice 并没有 string 高效,何况转换数据类型本身就会发生数据拷贝。
那么在这篇文章的第二个例子,为什么说传递字符串指针也不好呢,要了解指针在底层就是一个 int 类型的数据,而我们字符串只是两个 int 而已,另外如果了解 GC 的话,GC 只处理堆上的数据,传递指针字符串会导致数据逃逸到堆上,阅读标准库的代码会有很多注释说明避免逃逸到堆上,这样会极大的增加 GC 的开销,GC 的成本可谓是很高的呀。
疑惑
这篇文章说 “传递 slice 并没有 string 高效”,为什么还会有 bytes 包的存在呢,其中很多函数的功能和 strings 包的功能一致,只是把 string 换成了 []byte, 既然传递 []byte 没有 string 效率好,这个包存在的意义是什么呢。
我们想一下转换数据类型是会发生数据拷贝,这个成本可是大的多呀,如果我们数据本身就是 []byte 类型,使用 strings 包就需要转换数据类型了。
另外我们对比两个函数来看下一下即使传递 []byte 没有 string 效率好,但是标准库实现上却会导致两个函数有很大的性能差异的。
strings.Repeat 函数:
func Repeat(s string, count int) string {
// Since we cannot return an error on overflow,
// we should panic if the repeat will generate
// an overflow.
// See Issue golang.org/issue/16237
if count < 0 {
panic("strings: negative Repeat count")
} else if count > 0 && len(s)*count/count != len(s) {
panic("strings: Repeat count causes overflow")
}
b := make([]byte, len(s)*count)
bp := copy(b, s)
for bp < len(b) {
copy(b[bp:], b[:bp])
bp *= 2
}
return string(b)
}bytes.Repeat 函数:
func Repeat(b []byte, count int) []byte {
// Since we cannot return an error on overflow,
// we should panic if the repeat will generate
// an overflow.
// See Issue golang.org/issue/16237.
if count < 0 {
panic("bytes: negative Repeat count")
} else if count > 0 && len(b)*count/count != len(b) {
panic("bytes: Repeat count causes overflow")
}
nb := make([]byte, len(b)*count)
bp := copy(nb, b)
for bp < len(nb) {
copy(nb[bp:], nb[:bp])
bp *= 2
}
return nb
}上面两个函数的实现非常相似,除了类型不同 strings 包在处理完数据发生了一次类型转换,使用 bytes 只有一次内存分配,而 strings 是两次。
我们可以借助 exbytes.ToString 函数把 bytes.Repeat 的返回没有任何成本的转换会我们需要的字符串,如果我们输入也是一个字符串的话,还可以借助 exstrings.UnsafeToBytes 来转换输入的数据类型。
例如:
s := exbytes.ToString(bytes.Repeat(exstrings.UnsafeToBytes("x"), 10))不过这样写有点太麻烦了,实际上 exstrings 包里面正在修改 strings 里面一些类似函数的问题,所有的实现基本和标准库一致,只是把其中类型转换的部分用 exbytes.ToString 优化了一下,可以提升性能,也能提升开发效率。
exstrings.UnsafeRepeat 函数:
func UnsafeRepeat(s string, count int) string {
// Since we cannot return an error on overflow,
// we should panic if the repeat will generate
// an overflow.
// See Issue golang.org/issue/16237
if count < 0 {
panic("strings: negative Repeat count")
} else if count > 0 && len(s)*count/count != len(s) {
panic("strings: Repeat count causes overflow")
}
b := make([]byte, len(s)*count)
bp := copy(b, s)
for bp < len(b) {
copy(b[bp:], b[:bp])
bp *= 2
}
return exbytes.ToString(b)
}如果用上面的函数只需要下面这样写就可以了:
s:=exstrings.UnsafeRepeat("x", 10)go-extend 里面还收录了很多实用的方法,大家也可以多关注。
总结
- 千万不要为了使用
[]byte来优化string传递,类型转换成本很高,且slice本身也比string更大一些。 - 程序中是使用
string还是[]byte需要根据数据来源和处理数据的函数来决定,一定要减少类型转换。 - 关于使用
strings还是bytes包的问题,主要关注点是数据原始类型以及想获得的数据类型来选择。 - 减少使用字符串指针来优化字符串,这会增加
GC的开销,具体可以参考 大堆中避免大量的GC开销 一文。
转载:
本文作者: 戚银(thinkeridea)
本文链接: https://blog.thinkeridea.com/201902/go/string_ye_shi_yin_yong_lei_xing.html
版权声明: 本博客所有文章除特别声明外,均采用 CC BY 4.0 CN协议 许可协议。转载请注明出处!