项目目标:根据乳腺癌患者的病理信息,挖掘患者的症状与中医证型之间的关联关系,特别是各中医证素与乳腺癌TNM分期之间的关系。
原始数据是根据问卷调查得到,基本挖掘流程为:
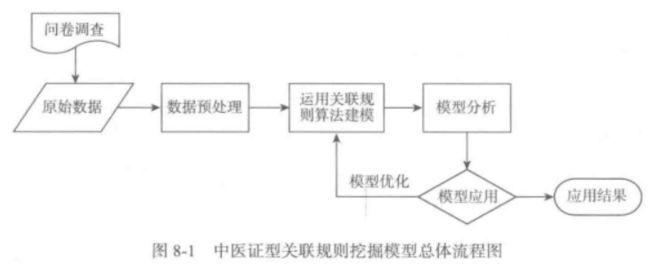
image.png
1. 数据预处理
属性归约:收集到的数据集案由73个属性,但为了更有效的挖掘,此处仅仅选择6种证型得分,TNM分期的属性值构成数据集。如下:

image.png
1.1 数据变换
主要采用属性构造和数据离散化两种方法来处理。首先通过属性构造,获得证型系数,然后通过聚类算法对数据进行离散化处理,形成建模数据。
本案例提供的数据集是已经经过属性构造得到了证型系数,故而只需要离散化处理即可。
由于Apriori关联规则算法无法处理连续型数值变量,为了将原始数据格式转换为适合建模的格式,需要对数据进行离散化处理。此处采用聚类算法对各证型系数进行离散化处理,将每个属性聚成4类。
比如:

image.png
from sklearn.cluster import KMeans #导入K均值聚类算法
k=4
result = pd.DataFrame()
for col in list('ABCDEF'):
print('正在进行{}列的聚类'.format(col))
kmodel=KMeans(n_clusters = k, n_jobs = 4)
kmodel.fit(data[col].values.reshape(-1,1)) #训练模型
r1=pd.DataFrame(kmodel.cluster_centers_,columns=[col]) # 聚类中心
r2=pd.Series(kmodel.labels_).value_counts() # 分类统计
r2=pd.DataFrame(r2,columns=[col+'n']) # 记录各个类别的数目
r=pd.concat([r1,r2],axis=1).sort_values(col)
# 匹配聚类中心和类别数目
r.index=[1,2,3,4]
r[col]=r[col].rolling(2).mean()
#rolling mean()用来计算相邻2列的均值,以此作为边界点。
r[col][1]=0.0
# 这两句代码将原来的聚类中心改为边界点。
result=result.append(r.T)
得到的result结果为:
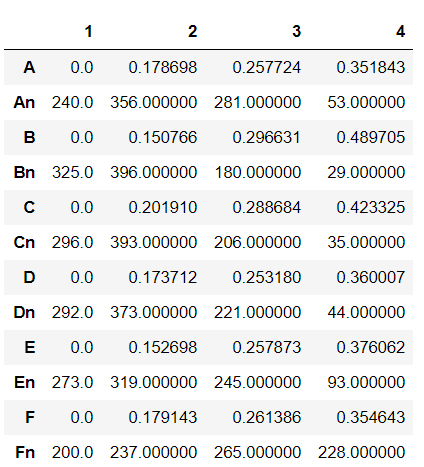
image.png
for col in 'ABCDEF':
bins=np.append(result.loc[col,:].values,1000)
data[col+'_cls']=pd.cut(data[col],bins=bins,labels=[col+str(i) for i in range(k)],include_lowest=True)
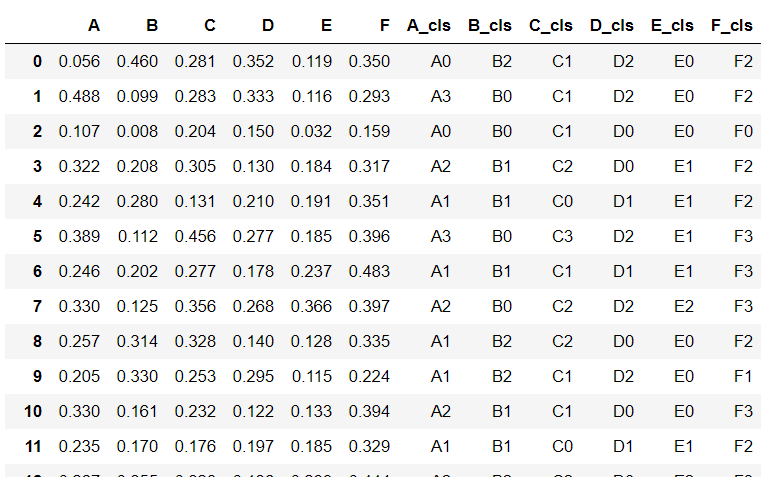
image.png
2. 关联规则挖掘
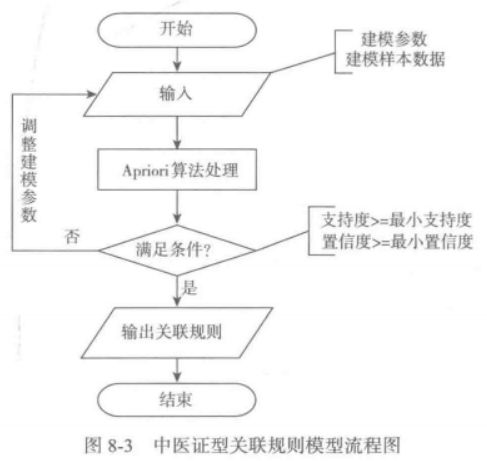
image.png
关联规则挖掘的一个难点是设置合理的最小支持度,最小置信度,目前并没有统一的标准,大部分都是根据业务经验设置初始值,经过多次调整,获取与业务相符的关联规则结果。
此处根据多次调整,结果实际业务分析,选取的输入参数为:最小支持度6%,最小置信度75%。
首先要对上面的数据进行one-hot编码,可以用pd.get_dummies来完成
data2=pd.get_dummies(data)
print(data2.shape)
print(data2.head(10))
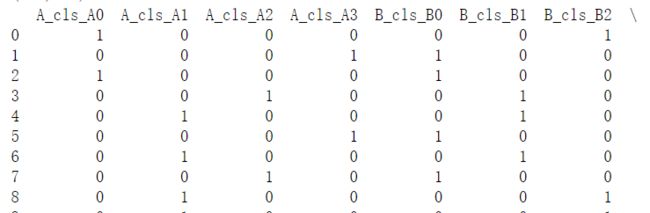
image.png
然后使用关联规则挖掘,代码为:
#自定义连接函数,用于实现L_{k-1}到C_k的连接
def connect_string(x, ms):
x = list(map(lambda i:sorted(i.split(ms)), x))
l = len(x[0])
r = []
for i in range(len(x)):
for j in range(i,len(x)):
if x[i][:l-1] == x[j][:l-1] and x[i][l-1] != x[j][l-1]:
r.append(x[i][:l-1]+sorted([x[j][l-1],x[i][l-1]]))
return r
#寻找关联规则的函数
def find_rule(d, support, confidence, ms = u'--'):
result = pd.DataFrame(index=['support', 'confidence']) #定义输出结果
support_series = 1.0*d.sum()/len(d) #支持度序列
column = list(support_series[support_series > support].index) #初步根据支持度筛选
k = 0
while len(column) > 1:
k = k+1
print(u'\n正在进行第%s次搜索...' %k)
column = connect_string(column, ms)
print(u'数目:%s...' %len(column))
sf = lambda i: d[i].prod(axis=1, numeric_only = True) #新一批支持度的计算函数
#创建连接数据,这一步耗时、耗内存最严重。当数据集较大时,可以考虑并行运算优化。
d_2 = pd.DataFrame(list(map(sf,column)), index = [ms.join(i) for i in column]).T
support_series_2 = 1.0*d_2[[ms.join(i) for i in column]].sum()/len(d) #计算连接后的支持度
column = list(support_series_2[support_series_2 > support].index) #新一轮支持度筛选
support_series = support_series.append(support_series_2)
column2 = []
for i in column: #遍历可能的推理,如{A,B,C}究竟是A+B-->C还是B+C-->A还是C+A-->B?
i = i.split(ms)
for j in range(len(i)):
column2.append(i[:j]+i[j+1:]+i[j:j+1])
cofidence_series = pd.Series(index=[ms.join(i) for i in column2]) #定义置信度序列
for i in column2: #计算置信度序列
cofidence_series[ms.join(i)] = support_series[ms.join(sorted(i))]/support_series[ms.join(i[:len(i)-1])]
for i in cofidence_series[cofidence_series > confidence].index: #置信度筛选
result[i] = 0.0
result[i]['confidence'] = cofidence_series[i]
result[i]['support'] = support_series[ms.join(sorted(i.split(ms)))]
result = result.T.sort_values(['confidence','support'], ascending = False) #结果整理,输出
print(u'\n结果为:')
print(result)
return result
support = 0.06 #最小支持度
confidence = 0.75 #最小置信度
ms = '---' #连接符,默认'--',用来区分不同元素,如A--B。需要保证原始表格中不含有该字符
find_rule(data2, support, confidence, ms)
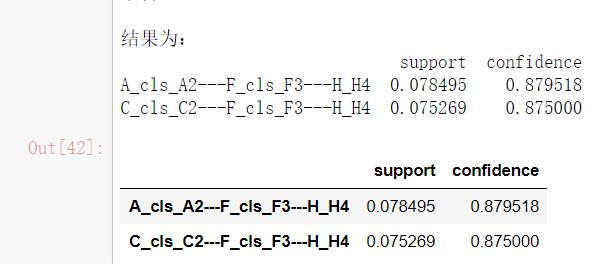
image.png
上面的关联规则表示的含义是:A2和F3可以推导出H4证型。且C2和F3也可以推导出H4证型。
需要注意的是:并非所有关联规则都有意义,所以需要根据实际情况来筛选最终的规则。
参考资料:
《Python数据分析和挖掘实战》张良均等