运用python将前一节爬取的赶集网数据进行分析了解北京城区二手物品发帖量
效果是这样的:
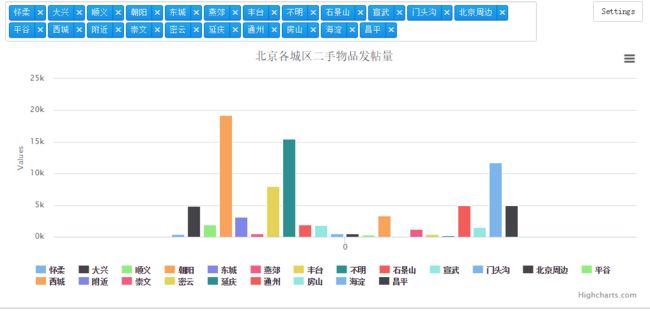
图表展示
我的代码:
from pymongo import MongoClient
from string import punctuation
import charts
client=MongoClient('localhost',27017)#链接数据库
ganjiDB=client['ganjiDB']
detail_info=ganjiDB['detail_info']
以下为过程调试查看信息,非代码部分
'''
print(detail_info.find().count())#查看collection有多少条document
-----------------------------------------------------------------------------------------------
输出信息:
86850
-----------------------------------------------------------------------------------------------
for i in detail_info.find().limit(1): #过程查看
print(i)
-----------------------------------------------------------------------------------------------
输出信息:
{'area': ['朝阳', '-', '高碑店'], '_id': ObjectId('5698f524a98063dbe9e91ca8'), 'look': '-', 'url': 'http://bj.58.com/jiadian/24541664530488x.shtml', 'price': '450 元', 'pub_date': '2016.01.12', 'cates': ['北京58同城', '北京二手市场', '北京二手家电', '北京二手冰柜'], 'title': '【图】95成新小冰柜转让 - 朝阳高碑店二手家电 - 北京58同城'}
-----------------------------------------------------------------------------------------------
for i in detail_info.find().limit(7):#过程查看
print(i['area'])
-----------------------------------------------------------------------------------------------
输出信息:
['朝阳', '-', '高碑店']
['朝阳', '-', '定福庄']
['西城', '-', '西单']
['朝阳', '-', '望京']
['丰台']
['朝阳', '-', '定福庄']
None
-----------------------------------------------------------------------------------------------
for i in detail_info.find().limit(7):#过程处理,将区域中的标点符号删除
if i['area']:
area=[i for i in i['area'] if i not in punctuation]#去除标点符号
else:
area=['不明']#将地区为‘None’调整为‘不明’
print(area)
-----------------------------------------------------------------------------------------------
输出信息:
['朝阳', '高碑店']
['朝阳', '定福庄']
['西城', '西单']
['朝阳', '望京']
['丰台']
['朝阳', '定福庄']
['不明']
-----------------------------------------------------------------------------------------------
'''
调试查看完毕,继续代码
for i in detail_info.find():
if i['area']:
area=[i for i in i['area'] if i not in punctuation]#去除标点符号
else:
area=['不明']#将地区为‘None’调整为‘不明’
detail_info.update_one({'_id':i['_id']},{'$set':{'area':area}})
#将修改的条目更新到collection,注意此之前做好原collection的备份db.collection.copyTo('newcollection')
area_list=[]#通过find条目信息查看,每个发帖条目都关联一个区域,那么可统一区域的数量进而推算当前区域的发帖量
for i in detail_info.find():
area_list.append(i['area'][0])
area_index=list(set(area_list))#将区域列表转换为集合剔除重复区域,运用集合的特点:无重复元素
#print(area_index,len(area_index))
post_times=[]
for index in area_index:
post_times.append(area_list.count(index))#以index为索引,查找每个index在原始区域表area_list中出现过多少次
#print(post_times)
def get_gen(types):#建议函数,运用生成器每次生成一条表象
length=0
if length<=len(area_index):
for area,times in zip(area_index,post_times):
info={
'name':area,
'data':[times],
'type':types
}
yield info
length+=1
series=[data for data in get_gen('column')]#生成图标所需参数
#print(series)
charts.plot(series, show='inline', options=dict(title=dict(text='七日内北京城区二手物品')))#图标生成
总结:
- 数据分析为了更好的图形化展示这里使用jupyter notebook;
- 图标分析查看使用charts模块;
- 引入string模块中的punctuation方法去除目标元素的标点符号;
- 函数中引入生成器,此函数需通过for循环依次迭代输出,或是next()方法;
- 集合与列表的灵活运用,借助列表元素的不重复性清理列表内容,使其作为列表索引;
- charts模块数据格式需遵循标准严格执行,‘data’:[times]。
- 数据库update方法的使用,db.collection.update({条件},{更新信息})