相应论文是“NetVALD: CNN architecture for weakly supervised place recognition”。
首先要明白VLAD是干什么的——VLAD(Vector of Locally Aggregated Descriptors)是一种用聚合后的局部特征来表示全局特征的编码方法。编码算法的具体公式是。是输入信息(比如图像经过CNN处理后的多层特征图),C是聚类后的中心点(共有k个簇),而是判断属于第k个簇的可能性。由公式可知,与k,i都有关,因此可以这样理解,如果将CNN提取的H*W*D的特征看作是H*W个D维特征,这H*W个特征都有着子集对应的簇中心,而簇有k个,所以a有(H*W)*k个取值,但是a只能取1或者0(和相距最近则取1,否则取0)。公式中x与i,j有关,其实就是说明了x是(H*W)个D维向量,而C是与k,j有关,就是说C是k个D维向量。
所以,就是说,对于每一张feature map上的每个点,分别求其余对应的簇中心点的差值和。所以结果V是一个k*D的矩阵,也就是每一张feature map都要与所有的簇中心计算一个差值,但只保留与最近的簇计算的差值。VLAD保存的是每个特征点与离它最近的聚类中心的距离,并将其作为新的编码特征,用于后接的分类器中。
我的理解就是VLAD其实就是找个k个簇,使得这k个簇可以尽可能的表征原feature map。V就体现了二者的差异性,值越小,说明原feature与对应的簇越接近。训练阶段就是利用V和BP算法不断修正簇中心对应的向量,为每个簇学习到一个更好的anchor,使得新的差值更小。
这里我理解错了,V是对原始特征编码后的新特征,还需要在V后面接上一个分类器就可以组成一个完整的模型并开始训练了。
那么NetVALD做了一个什么改进呢?其实就是对a做了改进。a表示的是某一个feature与所有的簇的关系,传统VLAD中的a是硬分配方式,就是说将feature强制性分给一个簇,此时a可以表示为[0,0,...,1,0,0,...,0]。这种一刀切的做法肯定不是很好,会造成一定的信息丢失。更好的方式是软分配方式,也就是将feature与每个簇的关系用一个概率值表示(最终所有的概率值之和为1),此时a可以表示为[0.1,0.7,...,0.08,...,0.01]。此时的a就不再是固定的1和0了,而是可以看成是一个神经网络的输出,此时模型的损失函数V就变成。相比于VLAD,NetVLAD包含更多的参数(a由固定的1、0表示变成神经网络表示),因此有着更好的适应性和学习性。原论文中的图更加直观地体现了这种适应性。

具体的实现流程图我就截取另一篇论文NeXtVLAD: An Efficient Neural Network to Aggregate Frame-level Features for Large-scale Video Classification中的图:
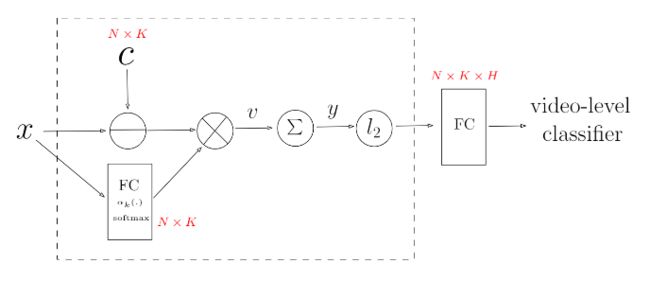
编码过程其实就是虚线框中的内容,要学习的参数主要有两类,一类是下面生成的FC层中的参数,共有个,一类是上面簇中心向量,也是有个。