什么是分库分表
顾名思义,分库分表就是按照一定的规则,对原有的数据库和表进行拆分,把原本存储于一个库的数据分块存储到多个库上,把原本存储于一个表的数据分块存储到多个表上。
为什么需要分库分表
随着时间和业务的发展,数据库中的数据量增长是不可控的,库和表中的数据会越来越大,随之带来的是更高的磁盘、IO、系统开销,甚至性能上的瓶颈,而一台服务的资源终究是有限的,因此需要对数据库和表进行拆分,从而更好的提供数据服务。
分库分表的方式
垂直分库/分表
垂直划分数据库是根据业务进行划分,例如将shop库中涉及商品、订单、用户的表分别划分出成一个库,通过降低单库(表)的大小来提高性能,但这种方式并没有解决高数据量带来的性能损耗。同样的,分表的情况就是将一个大表根据业务功能拆分成一个个子表,例如用户表可根据业务分成基本信息表和详细信息表等。
垂直分库/分表的优缺点
优点:
- 拆分后业务清晰,达到专库专用。
- 可以实现热数据和冷数据的分离,将不经常变化的数据和变动较大的数据分散再不同的库/表中。
- 便于维护
缺点:
- 不解决数据量大带来的性能损耗,读写压力依旧很大
- 不同的业务无法跨库关联(join),只能通过业务来关联
水平分库/分表
水平划分是根据一定规则,例如时间或id序列值等进行数据的拆分。比如根据年份来拆分不同的数据库。每个数据库结构一致,但是数据得以拆分,从而提升性能。又比如根据用户id的值,根据规则分成若干个表。每个表结构一致,(这点与垂直分库分表相反)。
水平分库/分表的优缺点
优点:
- 单库(表)的数据量得以减少,提高性能
- 提高了系统的稳定性和负载能力
- 切分出的表结构相同,程序改动较少
缺点:
- 拆分规则较难抽象
- 数据分片在扩容时需要迁移
- 维护量增大
- 依然存在跨库无法join等问题,同时涉及分布式事务,数据一致性等问题。
使用Sharding-JDBC进行分库分表
简介:
Sharding-JDBC是一个开源的分布式数据库中间件,它无需额外部署和依赖,完全兼容JDBC和各种ORM框架。Sharding-JDBC作为面向开发的微服务云原生基础类库,完整的实现了分库分表、读写分离和分布式主键功能,并初步实现了柔性事务。关于sj的详细配置和使用方法请参见官方文档
配置
Sharing-JDBC的springboot starter对springboot 2.0还不支持。我也是配置完项目启动失败才发现这个issue,懒得切换版本就暂且不使用starter pom吧,直接使用编程式配置。
准备
本Demo中使用的两个数据源是db0和db1,每个数据源之中包含了两组表t_order_0和t_order_1,t_order_item_0和t_order_item_1 。和官方文档的demo一致,这两组表的建表语句为:
CREATE TABLE IF NOT EXISTS t_order_x (
order_id INT NOT NULL,
user_id INT NOT NULL,
PRIMARY KEY (order_id)
);
CREATE TABLE IF NOT EXISTS t_order_item_x (
item_id INT NOT NULL,
order_id INT NOT NULL,
user_id INT NOT NULL,
PRIMARY KEY (item_id)
);
逻辑结构如下:
db0
├── t_order_0
└── t_order_1
db1
├── t_order_0
└── t_order_1
- 首先引入依赖
io.shardingjdbc
sharding-jdbc-core
2.0.3
- 配置表分片策略
@Bean
TableRuleConfiguration getOrderTableRuleConfiguration() {
TableRuleConfiguration orderTableRuleConfig = new TableRuleConfiguration();
//配置逻辑表名,并非数据库中真实存在的表名,而是sql中使用的那个,不受分片策略而改变.
//例如:select * frpm t_order where user_id = xxx
orderTableRuleConfig.setLogicTable("t_order");
//配置真实的数据节点,即数据库中真实存在的节点,由数据源名 + 表名组成
//${} 是一个groovy表达式,[]表示枚举,{...}表示一个范围。
//整个inline表达式最终会是一个笛卡尔积,表示ds_0.t_order_0. ds_0.t_order_1
// ds_1.t_order_0. ds_1.t_order_0
orderTableRuleConfig.setActualDataNodes("ds_${0..1}.t_order_${0..1}");
//主键生成列,默认的主键生成算法是snowflake
orderTableRuleConfig.setKeyGeneratorColumnName("order_id");
//设置分片策略,这里简单起见直接取模,也可以使用自定义算法来实现分片规则
orderTableRuleConfig.setTableShardingStrategyConfig(new InlineShardingStrategyConfiguration("order_id","t_order_${order_id % 2}"));
return orderTableRuleConfig;
}
@Bean
TableRuleConfiguration getOrderItemTableRuleConfiguration() {
TableRuleConfiguration orderItemTableRuleConfig = new TableRuleConfiguration();
orderItemTableRuleConfig.setLogicTable("t_order_item");
orderItemTableRuleConfig.setActualDataNodes("ds_${0..1}.t_order_item_${0..1}");
orderItemTableRuleConfig.setTableShardingStrategyConfig(new InlineShardingStrategyConfiguration("order_item_id","t_order_item_${order_id % 2}"));
return orderItemTableRuleConfig;
}
- 配置数据源
private Map createDataSourceMap() {
Map result = new HashMap<>(2, 1);
result.put("ds_0", createDataSource("ds_0"));
result.put("ds_1", createDataSource("ds_1"));
return result;
}
private DataSource createDataSource(final String dataSourceName) {
DruidDataSource result = new DruidDataSource();
result.setInitialSize(10);
result.setMinIdle(10);
result.setMaxActive(50);
result.setDriverClassName(com.mysql.jdbc.Driver.class.getName());
result.setUrl(String.format("jdbc:mysql://localhost:3306/%s?useSSL=false", dataSourceName));
result.setUsername("root");
result.setPassword("");
return result;
}
@Bean
DataSource getShardingDataSource() throws SQLException {
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTableRuleConfigs().add(getOrderTableRuleConfiguration());
shardingRuleConfig.getTableRuleConfigs().add(getOrderItemTableRuleConfiguration());
shardingRuleConfig.getBindingTableGroups().add("t_order, t_order_item");
shardingRuleConfig.setDefaultDatabaseShardingStrategyConfig(
new InlineShardingStrategyConfiguration("user_id", "ds_${user_id % 2}"));
shardingRuleConfig.setDefaultTableShardingStrategyConfig(
new InlineShardingStrategyConfiguration("order_id", "t_order_${order_id % 2}"));
return ShardingDataSourceFactory.createDataSource(createDataSourceMap(),
shardingRuleConfig, new HashMap<>(), null);
}
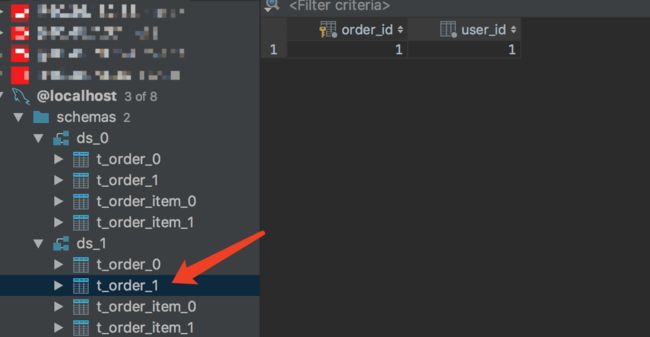
- 结果
使用junittest插入一条记录,查看分片结果:
@SpringBootTest
@RunWith(SpringRunner.class)
public class OrderDaoTest {
@Autowired private OrderDao orderDao;
@Test
public void addOrder() {
Order order = new Order();
order.setUserId(1);
order.setOrderId(1);
//insert into t_order (order_id, user_id) values(#{orderId}, #{userId})
orderDao.addOrder(order);
}
}
t_order这张表配置的分片策略是按照order_id与2取模,分库策略则是按照user_id与2取模,
所以最终的结果应该是插入在ds_1中的t_order_1中。