1.准备测试数据
使用如下建表语句,并插入测试数据:
CREATE TABLE IF NOT EXISTS test_decimal(
md5 string,
id int,
ty int,
amount decimal(38, 12)
) stored as orc ;
insert into table test_decimal values
('9F99855A44BD41FE592B69E0D36BF3E8', 4591, 2, 188593.210890000000),
('9F99855A44BD41FE592B69E0D36BF3E8', 4592, 2, 177918.123481132049),
('9F99855A44BD41FE592B69E0D36BF3E8', 4593, 2, 10675.087408867951);
2.使用测试sql测试(在2.3.x版本中执行的)
使用测试sql,发现测试的结果有精度损失:
hive> select id, sum(amount) from test_decimal group by id;
OK
4591 188593.210890000000
4592 177918.123481132049
4593 10675.087408867951
Time taken: 28.013 seconds, Fetched: 3 row(s)
hive> select id, sum(amount) * -1 from test_decimal group by id;
OK
4591 -188593.2108900000
4592 -177918.1234811320
4593 -10675.0874088680
Time taken: 26.016 seconds, Fetched: 3 row(s)
通过比较测试结果发现,在sum函数之后乘以 -1 导致精度损失了2位。
3.通过分析执行计划查找两条sql的执行计划的区别,查找原因(在2.3.x版本中执行的)
直接输出sum的sql的执行计划:
hive> explain select id, sum(amount) from test_decimal group by id;
OK
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: test_decimal
Statistics: Num rows: 3 Data size: 708 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: int), amount (type: decimal(38,12))
outputColumnNames: id, amount
Statistics: Num rows: 3 Data size: 708 Basic stats: COMPLETE Column stats: NONE
Group By Operator
aggregations: sum(amount)
keys: id (type: int)
mode: hash
outputColumnNames: _col0, _col1
Statistics: Num rows: 3 Data size: 708 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: int)
sort order: +
Map-reduce partition columns: _col0 (type: int)
Statistics: Num rows: 3 Data size: 708 Basic stats: COMPLETE Column stats: NONE
value expressions: _col1 (type: decimal(38,12))
Reduce Operator Tree:
Group By Operator
aggregations: sum(VALUE._col0)
keys: KEY._col0 (type: int)
mode: mergepartial
outputColumnNames: _col0, _col1
Statistics: Num rows: 1 Data size: 236 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 1 Data size: 236 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
Time taken: 0.16 seconds, Fetched: 48 row(s)
sum后乘以 -1 的sql的执行计划:
hive> explain select id, sum(amount)*-1 from test_decimal group by id;
OK
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: test_decimal
Statistics: Num rows: 3 Data size: 708 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: int), amount (type: decimal(38,12))
outputColumnNames: id, amount
Statistics: Num rows: 3 Data size: 708 Basic stats: COMPLETE Column stats: NONE
Group By Operator
aggregations: sum(amount)
keys: id (type: int)
mode: hash
outputColumnNames: _col0, _col1
Statistics: Num rows: 3 Data size: 708 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: int)
sort order: +
Map-reduce partition columns: _col0 (type: int)
Statistics: Num rows: 3 Data size: 708 Basic stats: COMPLETE Column stats: NONE
value expressions: _col1 (type: decimal(38,12))
Reduce Operator Tree:
Group By Operator
aggregations: sum(VALUE._col0)
keys: KEY._col0 (type: int)
mode: mergepartial
outputColumnNames: _col0, _col1
Statistics: Num rows: 1 Data size: 236 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: int), (_col1 * -1) (type: decimal(38,10))
outputColumnNames: _col0, _col1
Statistics: Num rows: 1 Data size: 236 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 1 Data size: 236 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
Time taken: 4.656 seconds, Fetched: 52 row(s)
通过查看两条sql(两条sql的差别是在sum函数后面有没有乘以 -1)的执行计划发现,直接输出sum的结果是 (value expressions: _col1 (type:decimal(38,12)))类型,输出乘以 -1 的结果是 ( expressions: _col0 (type: int), (_col1 * -1) (type:decimal(38,10)) )类型,说明乘以 -1 之后,精度损失了2位。
4.分析源码,找原因
通过分析sum后乘以 -1 的代码,其中关键的代码如下:
2.3.x 版本的GenericUDFOPMultiply 类的关键代码

prec1 和 scale1 代表的是 decimal(38,12)
prec2 和 scale2 代表的是 -1被转换成decimal后的类型为 decimal(1, 0)
其中 adjustPrecScale()方法的代码在其父类GenericUDFBaseNumeric中,代码如下:

decimal支持的最大精度为38,而通过上面的计算,发现精度precision字段的值已经达到了40,超过的最大精度,因此,需要重新计算精度,计算后的结果是,将小数的精度减少了2位为10,精度使用最大精度值38。
在hive2.3.x中,算术运算的精度的计算公式如下:
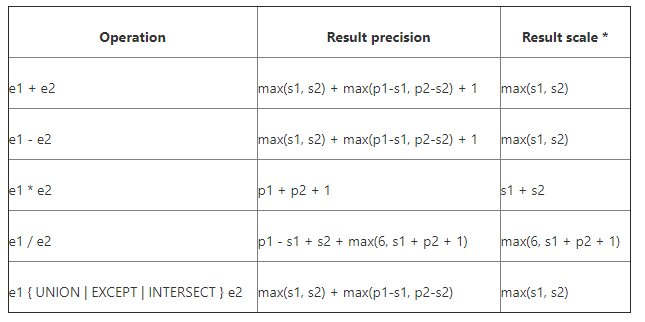
至此,精度损失的原因已经找到,是因为乘法运算,将两个精度进行相加后再加1,超出了最大精度,重新计算精度时,将小数位的精度改成了10导致的。
5.解决方案
1)针对这个乘以 -1 的操作,可以改成使用单目运算负号 - 的方式,将负号 - 加到sum前即可。
2)降低建表语句中decimal类型的精度字段的值,根据上面计算精度的表算出一个满足需要的最小精度值。
6.为啥相同的sql在1.2.x版本中结果就没有损失精度
1.2.x 版本的GenericUDFOPMultiply 类的关键代码
public class GenericUDFOPMultiply extends GenericUDFBaseNumeric {
.....
@Override
protected DecimalTypeInfo deriveResultDecimalTypeInfo(int prec1, int scale1, int prec2, int scale2) {
int scale = Math.min(HiveDecimal.MAX_SCALE, scale1 + scale2 );
int prec = Math.min(HiveDecimal.MAX_PRECISION, prec1 + prec2 + 1);
return TypeInfoFactory.getDecimalTypeInfo(prec, scale);
}
}
其中 HiveDecimal.MAX_SCALE 和 HiveDecimal.MAX_PRECISION 的值都是38。
从上面的关键代码中可以看到,在1.2.x中,没有重新校准精度的地方,而是使用简单粗暴的方式,各自计算precision和scale的精度,这就会导致在真实数据很大的时候,计算出来的值的精度达不到预期,也就是会不准确。,