1. Abstract
Accelerating the Super-Resolution Convolutional Neural Network
Chao Dong et. al. ECCV 2016, CUHK
这篇paper和SRCNN同出一个作者, 主打的就是对SRCNN的加速, 要加速到CPU real-time水平(>24fps)
所以分析这篇paper的关键, 就是看SRCNN有些什么问题, FSRCNN又是用哪些方法去做出改进
FSRCNN的改进主要在以下三个方面
First, we introduce a deconvolution layer at the end of the network, then the mapping is learned directly from the original low-resolution image (without interpolation) to the high-resolution one.
SRCNN因为输入的是cheap interpolated LR image, 所以有很多冗余计算, 改进这个问题, FSRCNN用了deconvolution layer, 前面都在LR的分辨率上进行, 最后用deconvolution upscale, 这样不管upscale的倍数是多少, 前面的层都可以复用, 不同的scale只要在最后一层fine-tune就可以
Second, we reformulate the mapping layer by shrinking the input feature dimension before mapping and expanding back afterwards.
SRCNN的Non-linear Mapping的参数量比较大, 效果最好的是SRCNN(9-5-5), Non-linear这层就是一64x32x5x5的卷积大小, 为了减少Non-linear Mapping的参数量, FSRCNN参考MobileNet的做法, 将通道的卷积和空间的卷积分开做, Shringking只做1x1卷积, 将提取的LR的特征降维, 然后做3x3卷积, 最后提高HR Feature的维度Expaning
Third, we adopt smaller filter sizes but more mapping layers. The proposed model achieves a speed up of more than 40 times with even superior restoration quality.
最后, FSRCNN缩小了卷积核的大小, 但是增加了网络的深度, 总体上降低了计算量
2. Algorithm
FSRCNN和SRCNN的结构对比
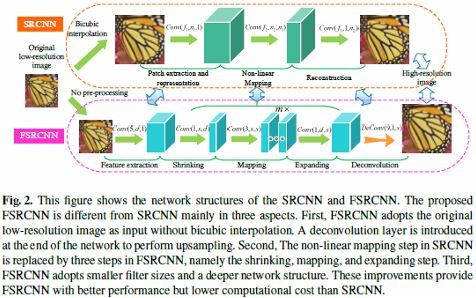
首先, 要问一个问题, SRCNN为什么慢, 主要是两方面的原因
- Interpolated LR输入网络, 这里面就有冗余计算, 假设要放大n倍, 那么计算复杂度就是用LR image计算的n^2倍
For the upscaling factor n, the computational cost of convolution with the interpolated LR image will be n^2 times of that for the original LR one - 非线性映射, 在SRCNN中, 作者发现用一个更大的卷积核能够提高最后的重建效果(开始的时候用1x1来mapping LR feature -> HR feature), 这样的问题就是Non-linear Mapping的参数太多
Dong et al. [2] show that the mapping accuracy can be substantially improved by adopting a wider mapping layer, but at the cost of the running time
解决方式就是
① 取消ILR输入, 采用LR输入, 在最后引用Deconv来恢复成HR图像尺寸
② 改进Mapping Layer
具体的改进主要包括以下几个方面
① Feature Extraction
在SRCNN中, feature extraction选的kernel size为9, 然而SRCNN是针对ILR进行操作的, 在LR做input时, 要获取相同的感受野实际上用不上这么大的kernel size, FSRCNN选取的kernel size为5x5
② Shrinking
在Mapping过程中, 一般是将LR feature进行map到HR feature中, 因此LR feature maps的维数一般非常高, 这里作者先用1x1通道卷积对LR feature降维, 减少后面的计算量
③ Non-linear Mapping
在SRCNN中, 作者选取了5x5的map layer, 5x5会带来较大的计算量, 作者换成了m个3x3卷积串联(实现中是4个)
④ Expanding
因为Shrinking中对LR feature进行的降维然后才做的mapping, 但是作者发现低纬度的HR feature的重建效果不好, 所以在mapping之后, 又用1x1 conv将HR feature升维, 类似Shrinking的反操作
⑤ Deconvolution
转置卷积完成了upsample操作, 这个操作可以看作是conv的逆操作, 因为stride=k的conv卷积会将feature map缩小k倍, 所以stride为k的tranpose conv会将feature map放大k倍
Deconvolution是FSRCNN减小运算量的一个关键点, 因为同样是放大n倍, 在LR上操作和HR上操作要差n^2倍, 但是在芯片实现上, 要考虑SR这个IP在什么位置, LR in HR out这样的数据流并不能保证在任何芯片上都适用, HR in HR out反而是更实际的一种做法, 所以FSRCNN这个cost down的方法实际上对我们用处不大
⑥ PReLU
PReLU是带可学习的泄露参数的ReLU的变体, 用它是为了防止出现ReLU训练时出现的神经元go die的现象
从SRCNN到FSRCNN的结构演进
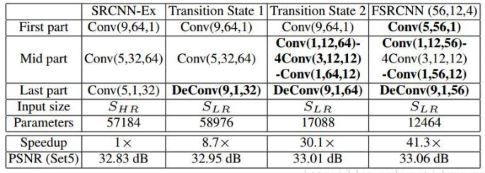
注意,
之前的SRCNN是在Set91上训练, 但对CNN来说, Set91并不够去训练大的网络结构, 由于BSD500是jpeg结构, 存在压缩也不适合做训练dataset, 本文提出用general-100+Set91充当Train Dataset, 并且加入Data Augmentation
- downscale 0.9/0.8/0.7 and 0.6
- Rotation 90/180/270, 因此会得到20倍的训练数据
3. Discussion
FSRCNN和SRCNN的结构对比
优点
FSRCNN最大的优点就是快, 这个快还不是一般的快, 偶尔找到的一篇2018年以fast开头的Super Resolution的paper

Fast, Accurate, and, Lightweight Super-Resolution with Cascading Residual Network
Namhyuk Ahn et. al. arXiv Mar 2018
Note:
我觉得这篇paper这张表格的数据有问题
- FSRCNN从LR开始Convolution, 按照paper中的说法The numbers of operations is computed by assuming that the HR image size is 300x300, 那2/3/4倍的SR应该是不一样的Mult-Adds才对, 因为输入的图像尺寸大小是不一样的FSRCNN输入的尺寸应该分别是150x150/100x100/75x75, 即便是一样的输入尺寸, 要放大不同的scale, 因为最后Decovolution那级的stride不一样, 所以计算量也是不同的, 所以无论怎么解释, FSRCNN的计算量在不同的SR scale也应该是不同的
- 在这个表中LapSRN最小的计算量是x2 scale的2,297M, 大FSRCNN将近20倍, 这个数据不知道是怎么得到的, 因为在LapSRN的paper中LapSRN和FSRCNN是同一个运算量级的, 也有可能是选取的版本不同, 同样的一个网络, 也有可能会有好几个不同的版本, 所以这个除非自己算过, 否则只能做参考
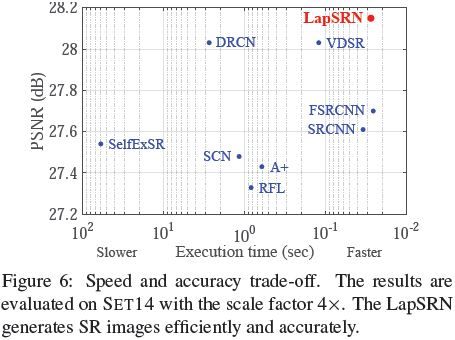
结合我们之前看的分析小网络的这篇
https://zhuanlan.zhihu.com/p/37074222
别人的paper给的比较数据并不一定准确, 而且不同的人拿你的模型去跑benchmark选取的版本和大小可能都不一样, 给我们的经验就是对于low-cost DL SR来说, 如果paper中有提到针对速度的优化, 或者是自己说和FSRCNN在同一个量级, 那就有看的价值, 如果自己都没说, 或者是自己给的benchmark就和FSRCNN的计算量级差的比较远, 那就没有什么看的必要了
这篇paper主推自己的方面的快速, 确实在包括LapSRN, VDSR等今年众多算法在内的这个benchmark中, 以1000M这个运算量级达到的PSNR/SSIM确实是最高的, 但是我们看到的亮点却是FSRCNN
100M运算量级基本上只有这一个算法, 100M的Mult-Adds是什么概念呢?
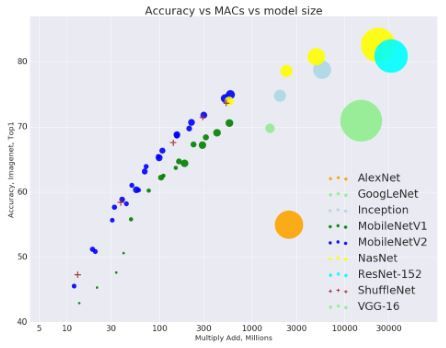
这张图, 圆圈大小是Para的数量, 横轴是运算量(Multi-Adds), 纵轴是Accuracy
以70%这个并不高的准确率来看, 只有MobileNetV2/V1能在100M级的运算量上能达到, MobileNetV2是CVPR 2018的论文, 就是说, 这个基本是已知的计算量和准确率balance的极限了
所以, FSRCNN可能是离我们能最近的能在Chip上实现的方案了
那100M的Multi-Adds是什么概念呢?
如果还算到4K的SR IP, 要做到60fps, 大概需要两颗寒武纪以极限的运算速度来跑, 就是说就算是用FSRCNN这个方案, 我们要把DL SR做到chip上, 基本上也只能做个单芯片的SR IP, 因为这个芯片已经没有多余算力分给别的IP了
所以, 100M这个量级就是黄线, 我们从上面那个表上看到, 实际上在最近两年发表的SR的paper都在提高评价指标上做出了更多努力, 100M计算量的算法再也没有出现过
从这个结论来看, 我们目前Survey的方向需要稍微调整一下
① Survey有没有和FSRCNN一个计算量级的(至少不能到1000M级别)有效的SR算法
② Network Compression, 延续之前的Presentation的内容, 将近两年的有用的干货丰富进去
缺点
缺点就是效果比SRCNN没什么长进, SRCNN是14年的paper了, 相信会有新的paper能达到FSRCNN的运算量并且在SRCNN的效果上有比较明显的改善