关于CPU缓存: 点击跳转
Java内存模型简介及其避免入坑提示: 点击跳转
CPU缓存与Java内存模型: 点击跳转
jsr133: 点击跳转
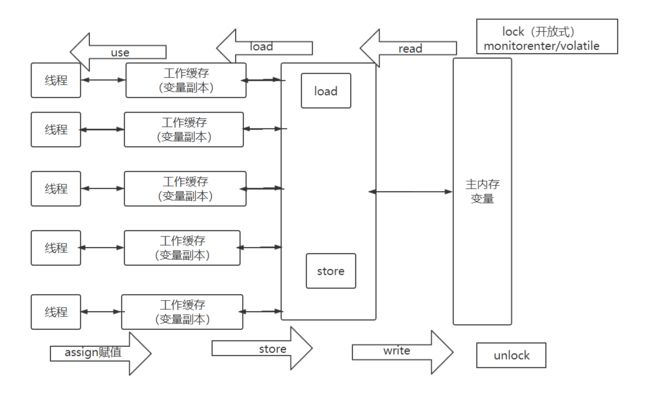
根据JMM我们有如下结论:
每条线程都有自己的工作内存(可与处理器的高速缓存类比)。
线程的工作内存中会保存该线程使用到的变量的主内存副本拷贝,线程对变量的所有操作都在工作内存中进行。
只有当线程运行结束后才会将数据刷到主存中。
引用《深入了解Java虚拟机 第3版》中的原话
对于Sun JDK来说, 它的Windows版与Linux版都是使用一对一的线程模型实现的,
一条Java线程就映射到一条轻量级进程之中,因为Windows和Linux系统提供的线程模型就是一对一的。
所谓的轻量级进程就是内核线程的一种高级接口...线程的工作内存其实是CPU寄存器和高速缓存的抽象
其实根据上面的结论中,就能得出对多线程常见问题的认知。
在一个线程中写入变量,另一个线程读取相同的变量,并且不通过同步对写入和读取进行顺序限制, 这就叫数据竞争(data race)。
(对于使用volatile关键字修饰变量也是如此)
当通过同步处理时, 就确保了不同线程对于该变量的访问顺序(也确保了可见性)
在jsr133中关于先行发生关系的描述中,有如下一句:
An unlock on a monitor happens-before every subsequent lock on that monitor.
我们来谈论下volatile
boolean initialized = false;
// 假设如下线程A的内容
线程A {
// ... (这里有进行一些数据初始化)
initialized = true;
}
// 假设如下线程B的内容
线程B {
while(!initialized) {
//...
}
// ... (这里有进行一些操作)
}
我们"原本"是想,让线程A先初始化线程B要使用的数据,初始化完成后修改信号变量,让线程B开始"正式执行"...
但是正式执行时,逻辑可能不会按照我们预计的执行。
线程B一直在循环,因为线程B的工作内存一直是false,线程A的操作对于B不可见。
但是当我们给initialized这个状态加上volatile时,程序正确的运行了。
这就是volatile的保证可见性。
那么它到底怎么实现的? => CPU缓存一致性协议MESI
通过查汇编代码,可以看到在写volatile时,会有一个lock addl $0x0, (%esp)操作(该指令取自《深入了解Java虚拟机》中)。
看后面的addl $0x0, (%esp)指令 (%esp是个寄存器 => 双字 这里使用addl指令操作) (把esp寄存器的值加0),这个都能知道是什么意思。
那这lock前缀是什么玩意?。
然后根据上面的文章发现...emm 这是个总线锁(手动黑人问号脸)
书上说: 在IA32手册中,它的作用是使得本CPU的Cache写入内存同时引起别的CPU无效化其Cache
(由于没去看过手册..不好确认 只能不断找点帖子看见但的解释)
然后经过一番寻找我在stackoverflow找到了关于lock prefix的解释: Can num++ be atomic for 'int num'?
(那个票数最多的回答)
So lock add dword [num], 1 is atomic. A CPU core running that instruction would keep the cache line pinned in Modified state in its private L1 cache from when the load reads data from cache until the store commits its result back into cache. This prevents any other cache in the system from having a copy of the cache line at any point from load to store, according to the rules of the MESI cache coherency protocol (or the MOESI/MESIF versions of it used by multi-core AMD/Intel CPUs, respectively). Thus, operations by other cores appear to happen either before or after, not during.
(If a locked instruction operates on memory that spans two cache lines, it takes a lot more work to make sure the changes to both parts of the object stay atomic as they propagate to all observers, so no observer can see tearing. The CPU might have to lock the whole memory bus until the data hits memory. Don't misalign your atomic variables!)
Note that the lock prefix also turns an instruction into a full memory barrier (like MFENCE), stopping all run-time reordering and thus giving sequential consistency. (See Jeff Preshing's excellent blog post. His other posts are all excellent, too, and clearly explain a lot of good stuff about lock-free programming, from x86 and other hardware details to C++ rules.)
(更多关于lock prefix的问题可以去看下IA-32架构软件开发人员手册)
上面stackoverflow帖子中的回答里提到了
MESI cache coherency protocol 和 memory barrier
(经过对这2个点的搜索,就能明白了volatile的关键点,关于MESI的帖子中就有2者.)
任何带有lock前缀的指令都有内存屏障的作用。
我们看到上文中的lock addl $0x0, (%esp)操作就是volatile的真面目...核心点就是MESI、lock prefix、内存屏障这几个点。
下面还是看看指令重排序的影响到底是什么吧...
在jsr133中,有如下
The semantics of the Java programming language allow compilers and microprocessors to perform optimizations(允许指令重排序优化)
Java指令重排序一个有名的案例就是JDK 1.5之前使用volatile后DCL(双重检查锁定)仍然无法安全的使用
public class Singleton {
private volatile static Singleton instance;
private Singleton() {}
public static Singleton getInstance() {
if (instance == null) {
synchronzied(Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
参考双重检查锁定中的内容
问题出在instance = new Singleton()这一句,当实例化的时候,其实分为三个步骤
memory = allocate(); // 1
ctorInstance(memory); // 2
instance = memory; // 3
上面是真实发生的实例化过程,在某些编译器上在发生指令重排序之后,可能变成下面这样
memory = allocate(); // 1
instance = memory; // 3
ctorInstance(memory); // 2
1.分配对象的内存空间
2.初始化对象
3.设置instance指向刚分配的内存地址
JDK 1.5中修复了该问题. 这就是volatile的指令重排序
这里来一个jsr133中关于Happens-Before关系的内容可以辅助理解:
Each action in a thread happens-before every subsequent action in that thread. // thread
An unlock on a monitor happens-before every subsequent lock on that monitor. // 阻塞同步
A write to a volatile field happens-before every subsequent read of that volatile. // volatile
A call to start() on a thread happens-before any actions in the started thread.
All actions in a thread happen-before any other thread successfully returns from a join() on that thread.
If an action a happens-before an action b, and b happens before an action c, then a happensbefore c. // 传递性
谈下ReentrantReadWriteLock中的锁降级
(假设是在了解读写锁的情况下进行的)

锁降级的时候 要求当前已经获取到写锁的线程把持住写锁,然后获取读锁,随后释放写锁, 最后释放读锁。
// 代码获取自 https://www.jianshu.com/p/0f4a1995f57d
class CachedData {
Object data;
volatile boolean cacheValid;
final ReentrantReadWriteLock rwl = new ReentrantReadWriteLock();
void processCachedData() {
rwl.readLock().lock();
if (!cacheValid) {
// Must release read lock before acquiring write lock
rwl.readLock().unlock();
rwl.writeLock().lock();
try {
// Recheck state because another thread might have
// acquired write lock and changed state before we did.
if (!cacheValid) {
data = ...
cacheValid = true;
}
// Downgrade by acquiring read lock before releasing write lock
rwl.readLock().lock();
} finally {
rwl.writeLock().unlock(); // Unlock write, still hold read
}
}
try {
use(data);
} finally {
rwl.readLock().unlock();
}
}
}
那么如果是 获取写锁 => 释放写锁 => 获取读锁 => 释放读锁 会怎样呢?
在线程A释放写锁到获取读锁的间隔中,可能有其他线程(B)获取到了写锁,如果在其中有对要操作的目标进行的写入数据操作时,根据上述的JMM。
我们可得知在线程B中对目标数据的修改,线程A可能感知不到(还是使用的自己的工作内存)。
在此情况下,程序可能会出现意想不到的问题。而遵循锁降级规则,则能避免出现该情况。
这就是锁降级的必要性与其工作意义。
其他相关内容