爬虫Larbin解析(二)——sequencer()
分析的函数: void sequencer()
//位置:larbin-2.6.3/src/fetch/sequencer.cc
void sequencer() { bool testPriority = true; if (space == 0) //unit space = 0 { space = global::inter->putAll(); } int still = space; if (still > maxPerCall) //#define maxPerCall 100 still = maxPerCall; while (still) { if (canGetUrl(&testPriority)) { --space; --still; } else { still = 0; } } }
所在的文件
larbin-2.6.3/src/fetch/sequencer.h、larbin-2.6.3/src/fetch/sequencer.cc


// Larbin // Sebastien Ailleret // 15-11-99 -> 15-11-99 #ifndef SEQUENCER_H #define SEQUENCER_H /** only for debugging, handle with care */ extern uint space; /** Call the sequencer */ void sequencer (); #endif
// Larbin // Sebastien Ailleret // 15-11-99 -> 04-01-02 #include <iostream.h> #include "options.h" #include "global.h" #include "types.h" #include "utils/url.h" #include "utils/debug.h" #include "fetch/site.h" static bool canGetUrl (bool *testPriority); uint space = 0; #define maxPerCall 100 /** start the sequencer*/ //按优先度将URL放到代爬站点 void sequencer() { bool testPriority = true; if (space == 0) { space = global::inter->putAll(); } int still = space; if (still > maxPerCall) //#define maxPerCall 100 still = maxPerCall; while (still) { if (canGetUrl(&testPriority)) { space--; still--; } else { still = 0; } } } /* Get the next url * here is defined how priorities are handled 按优先级从各个URL队列 (比如URLsDisk,URLsDiskWait或URLsPriority,URLsPriorityWait) 获取url保存到某个NameSite(通过url的hash值) */ static bool canGetUrl (bool *testPriority) { url *u; if (global::readPriorityWait) // global.cc 赋值为0 { global::readPriorityWait--; u = global::URLsPriorityWait->get(); global::namedSiteList[u->hostHashCode()].putPriorityUrlWait(u); return true; } else if (*testPriority && (u=global::URLsPriority->tryGet()) != NULL) { // We've got one url (priority) global::namedSiteList[u->hostHashCode()].putPriorityUrl(u); return true; } else { *testPriority = false; // Try to get an ordinary url if (global::readWait) { global::readWait--; u = global::URLsDiskWait->get(); global::namedSiteList[u->hostHashCode()].putUrlWait(u); return true; } else { u = global::URLsDisk->tryGet(); if (u != NULL) { global::namedSiteList[u->hostHashCode()].putUrl(u); return true; } else { return false; } } } }
一、 对于space = global::inter->putAll();
1. interf在global.cc(位置:/larbin-2.6.3/src/global.cc)中的定义为
inter = new Interval(ramUrls); //#define ramUrls 100000 (位置:larbin-2.6.3/src/types.h)
批注:区别 inter = new Interval(ramUrls); 和 inter = new Interval[ramUrls]; 前一个()内是参数,要传入构造函数的;后一个[]内是开辟数组的个数。
2. 类 Interval定义(位置:/larbin-2.6.3/src/fetch/site.h)
/** This class is intended to make sure the sum of the * sizes of the fifo included in the different sites * are not too big */ class Interval { public: Interval (uint sizes) : size(sizes), pos(0) {} ~Interval () {} /** How many urls can we put. Answer 0: if no urls can be put */ inline uint putAll () { int res = size - pos; pos = size; return res; } /** Warn an url has been retrieved */ inline void getOne () { --pos; } /** only for debugging, handle with care */ inline uint getPos () { return pos; } private: /** Size of the interval */ uint size; /** Position in the interval */ uint pos; };
批注:类内的函数定义为inline。对内联函数的几点说明:
- 内联函数避免函数调用的开销。将函数指定为内联函数,(通常)就是将它在程序的每个调用点上“内联地”展开,消除调用函数进行的额外开销(调用前先保存寄存器,并在返回时回复)。内联说明(在函数返回值前加inline)对编译器来说只是一个建议,编译器可以选择忽略。一般内敛函数适用于优化小的、只有几行、经常被调用的函数。大多数编译器不支持递归函数的内敛。
- 把内联函数放在头文件。以便编译器能够在调用点展开同一个函数(保证编译器可见、所有的定义相同)。
- 编译器隐式地将在类内定义的成员函数当作为内联函数.
二、 对于canGetUrl(&testPriority)
函数定义(位置larbin-2.6.3/src/fetch/sequencer.cc)
/* Get the next url * here is defined how priorities are handled 按优先级从各个URL队列 (比如URLsDisk,URLsDiskWait或URLsPriority,URLsPriorityWait) 获取url保存到某个NameSite(通过url的hash值) at "global.cc" // FIFOs URLsDisk = new PersistentFifo(reload, fifoFile); URLsDiskWait = new PersistentFifo(reload, fifoFileWait); URLsPriority = new SyncFifo<url>; URLsPriorityWait = new SyncFifo<url>; */ static bool canGetUrl (bool *testPriority) { url *u; if (global::readPriorityWait != 0) // 在global.cc声明定义: uint global::readPriorityWait=0; { global::readPriorityWait--; u = global::URLsPriorityWait->get(); global::namedSiteList[u->hostHashCode()].putPriorityUrlWait(u); return true; } else if (*testPriority && (u=global::URLsPriority->tryGet()) != NULL) { // We've got one url (priority) global::namedSiteList[u->hostHashCode()].putPriorityUrl(u); return true; } else { *testPriority = false; // Try to get an ordinary url if (global::readWait) { global::readWait--; u = global::URLsDiskWait->get(); global::namedSiteList[u->hostHashCode()].putUrlWait(u); return true; } else { u = global::URLsDisk->tryGet(); if (u != NULL) { global::namedSiteList[u->hostHashCode()].putUrl(u); return true; } else { return false; } } } }
1. 为什么disk和priority的队列都是成对出现的,是因为可以认为每个site在namedSiteList当中都有一个小的队列来保存它的url,这个url的个数是有个数限制的,当超过这个限制的时候就不能再把该site下的url放入,但也不能丢弃,而是放入wait队列。Larbin会控制一段时间在disk队列中取url,一段时间在diskWait当中取url。disk和priority的区别只是优先级的区别。namedSiteList的作用是实现了DNS缓存。
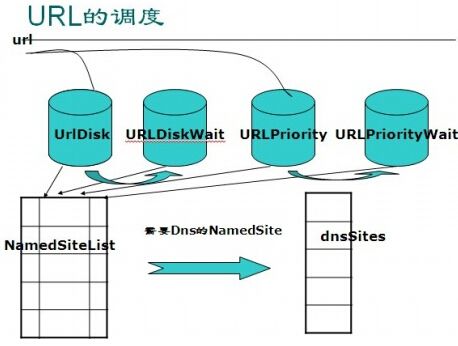
2. global::readPriorityWait 的值由main.cc的cron()函数中变化得知
// see if we should read again urls in fifowait if ((global::now % 300) == 0) { global::readPriorityWait = global::URLsPriorityWait->getLength(); global::readWait = global::URLsDiskWait->getLength(); } if ((global::now % 300) == 150) { global::readPriorityWait = 0; global::readWait = 0; }
这里global::now%300是判断这次是对wait里的url进行处理,还是对不是wait里的进行处理,这里的%300等于0和150的概率都是1/300,所以大约300次换一次。readPriorityWait是URLsPriorityWait中的长度(也就是url的数量);readWait是URLsDiskWait中url的个数。
3. 在canGetUrl中,在对于每个站点,将相应的url放进去。putPriorityUrlWait, putPriorityUrl, putUrlWait, putUrl在site.h的定义如下
/** Put an url in the fifo * If there are too much, put it back in UrlsInternal * Never fill totally the fifo => call at least with 1 */ void putGenericUrl(url *u, int limit, bool prio); inline void putUrl(url *u) { putGenericUrl(u, 15, false); } inline void putUrlWait(url *u) { putGenericUrl(u, 10, false); } inline void putPriorityUrl(url *u) { putGenericUrl(u, 5, true); } inline void putPriorityUrlWait(url *u) { putGenericUrl(u, 1, true); }
可以发现,每次都是调用函数putGenericUrl,其定义如下
/* Put an url in the fifo if their are not too many */ void NamedSite::putGenericUrl(url *u, int limit, bool prio)
{ if (nburls > maxUrlsBySite - limit)
{ // Already enough Urls in memory for this Site // first check if it can already be forgotten if (!strcmp(name, u->getHost()))
{ if (dnsState == errorDns)
{ nburls++; forgetUrl(u, noDNS); return; } if (dnsState == noConnDns)
{ nburls++; forgetUrl(u, noConnection); return; } if (u->getPort() == port && dnsState == doneDns && !testRobots(u->getFile()))
{ nburls++; forgetUrl(u, forbiddenRobots); return; } } // else put it back in URLsDisk refUrl(); global::inter->getOne(); if (prio)
{ global::URLsPriorityWait->put(u); }
else
{ global::URLsDiskWait->put(u); } }
如果已经有足够多的url在内存里,执行这里if中的代码,strcmp(name,u->getHost())是判断这个主机是不是已经就进行过dns方面的判断,也就是说对于一个站点,只做一次dns解析的判断,以后就按这个结果进行处理,dnsState有noDns,noConnDns,还有robots.txt不允许的情况,如果没有问题,就把它放到URLsDisk中。
else { nburls++; if (dnsState == waitDns || strcmp(name, u->getHost()) || port != u->getPort() || global::now > dnsTimeout) { // dns not done or other site putInFifo(u); addNamedUrl(); // Put Site in fifo if not yet in if (!isInFifo) { isInFifo = true; global::dnsSites->put(this); } } else switch (dnsState) { case doneDns: transfer(u); break; case errorDns: forgetUrl(u, noDNS); break; default: // noConnDns forgetUrl(u, noConnection); } }
如果需要判断dns能不能解析,就将它放到dnsSites里,这个会在fetchDns中判断。或是如果还能放到内存里,并且又是doneDns,表示可以解析,就调用transfer:
void NamedSite::transfer(url *u) { if (testRobots(u->getFile())) { if (global::proxyAddr == NULL) { memcpy(&u->addr, &addr, sizeof(struct in_addr)); } global::IPSiteList[ipHash].putUrl(u); } else { forgetUrl(u, forbiddenRobots); } }
这里是将url放入到IPSiteList的相应ipHash中。
附类的定义
类url定义(larbin-2.6.3/src/utils/url.h larbin-2.6.3/src/utils/url.cc)
// Larbin // Sebastien Ailleret // 15-11-99 -> 14-03-02 /* This class describes an URL */ #ifndef URL_H #define URL_H #include <netinet/in.h> #include <sys/types.h> #include <sys/socket.h> #include <stdlib.h> #include "types.h" bool fileNormalize (char *file); class url { private: char *host; char *file; uint16_t port; // the order of variables is important for physical size int8_t depth; /* parse the url */ void parse (char *s); /** parse a file with base */ void parseWithBase (char *u, url *base); /* normalize file name */ bool normalize (char *file); /* Does this url starts with a protocol name */ bool isProtocol (char *s); /* constructor used by giveBase */ url (char *host, uint port, char *file); public: /* Constructor : Parses an url (u is deleted) */ url (char *u, int8_t depth, url *base); /* constructor used by input */ url (char *line, int8_t depth); /* Constructor : read the url from a file (cf serialize) */ url (char *line); /* Destructor */ ~url (); /* inet addr (once calculated) */ struct in_addr addr; /* Is it a valid url ? */ bool isValid (); /* print an URL */ void print (); /* return the host */ inline char *getHost () { return host; } /* return the port */ inline uint getPort () { return port; } /* return the file */ inline char *getFile () { return file; } /** Depth in the Site */ inline int8_t getDepth () { return depth; } /* Set depth to max if we are at an entry point in the site * try to find the ip addr * answer false if forbidden by robots.txt, true otherwise */ bool initOK (url *from); /** return the base of the url * give means that you have to delete the string yourself */ url *giveBase (); /** return a char * representation of the url * give means that you have to delete the string yourself */ char *giveUrl (); /** write the url in a buffer * buf must be at least of size maxUrlSize * returns the size of what has been written (not including '\0') */ int writeUrl (char *buf); /* serialize the url for the Persistent Fifo */ char *serialize (); /* very thread unsafe serialisation in a static buffer */ char *getUrl(); /* return a hashcode for the host of this url */ uint hostHashCode (); /* return a hashcode for this url */ uint hashCode (); #ifdef URL_TAGS /* tag associated to this url */ uint tag; #endif // URL_TAGS #ifdef COOKIES /* cookies associated with this page */ char *cookie; void addCookie(char *header); #else // COOKIES inline void addCookie(char *header) {} #endif // COOKIES }; #endif // URL_H
// Larbin // Sebastien Ailleret // 15-11-99 -> 16-03-02 /* This class describes an URL */ #include <assert.h> #include <stdlib.h> #include <stdio.h> #include <string.h> #include <ctype.h> #include <sys/types.h> #include <sys/socket.h> #include "options.h" #include "types.h" #include "global.h" #include "utils/url.h" #include "utils/text.h" #include "utils/connexion.h" #include "utils/debug.h" #ifdef COOKIES #define initCookie() cookie=NULL #else // COOKIES #define initCookie() ((void) 0) #endif // COOKIES /* small functions used later */ static uint siteHashCode (char *host) { uint h=0; uint i=0; while (host[i] != 0) { h = 37*h + host[i]; i++; } return h % namedSiteListSize; } /* return the int with correspond to a char * -1 if not an hexa char */ static int int_of_hexa (char c) { if (c >= '0' && c <= '9') return (c - '0'); else if (c >= 'a' && c <= 'f') return (c - 'a' + 10); else if (c >= 'A' && c <= 'F') return (c - 'A' + 10); else return -1; } /* normalize a file name : also called by robots.txt parser * return true if it is ok, false otherwise (cgi-bin) */ bool fileNormalize (char *file) { int i=0; while (file[i] != 0 && file[i] != '#') { if (file[i] == '/') { if (file[i+1] == '.' && file[i+2] == '/') { // suppress /./ int j=i+3; while (file[j] != 0) { file[j-2] = file[j]; j++; } file[j-2] = 0; } else if (file[i+1] == '/') { // replace // by / int j=i+2; while (file[j] != 0) { file[j-1] = file[j]; j++; } file[j-1] = 0; } else if (file[i+1] == '.' && file[i+2] == '.' && file[i+3] == '/') { // suppress /../ if (i == 0) { // the file name starts with /../ : error return false; } else { int j = i+4, dec; i--; while (file[i] != '/') { i--; } dec = i+1-j; // dec < 0 while (file[j] != 0) { file[j+dec] = file[j]; j++; } file[j+dec] = 0; } } else if (file[i+1] == '.' && file[i+2] == 0) { // suppress /. file[i+1] = 0; return true; } else if (file[i+1] == '.' && file[i+2] == '.' && file[i+3] == 0) { // suppress /.. if (i == 0) { // the file name starts with /.. : error return false; } else { i--; while (file[i] != '/') { i--; } file[i+1] = 0; return true; } } else { // nothing special, go forward i++; } } else if (file[i] == '%') { int v1 = int_of_hexa(file[i+1]); int v2 = int_of_hexa(file[i+2]); if (v1 < 0 || v2 < 0) return false; char c = 16 * v1 + v2; if (isgraph(c)) { file[i] = c; int j = i+3; while (file[j] != 0) { file[j-2] = file[j]; j++; } file[j-2] = 0; i++; } else if (c == ' ' || c == '/') { // keep it with the % notation i += 3; } else { // bad url return false; } } else { // nothing special, go forward i++; } } file[i] = 0; return true; } /**************************************/ /* definition of methods of class url */ /**************************************/ /* Constructor : Parses an url */ url::url (char *u, int8_t depth, url *base) { newUrl(); this->depth = depth; host = NULL; port = 80; file = NULL; initCookie(); #ifdef URL_TAGS tag = 0; #endif // URL_TAGS if (startWith("http://", u)) { // absolute url parse (u + 7); // normalize file name if (file != NULL && !normalize(file)) { delete [] file; file = NULL; delete [] host; host = NULL; } } else if (base != NULL) { if (startWith("http:", u)) { parseWithBase(u+5, base); } else if (isProtocol(u)) { // Unknown protocol (mailto, ftp, news, file, gopher...) } else { parseWithBase(u, base); } } } /* constructor used by input */ url::url (char *line, int8_t depth) { newUrl(); this->depth = depth; host = NULL; port = 80; file = NULL; initCookie(); int i=0; #ifdef URL_TAGS tag = 0; while (line[i] >= '0' && line[i] <= '9') { tag = 10*tag + line[i] - '0'; i++; } i++; #endif // URL_TAGS if (startWith("http://", line+i)) { parse(line+i+7); // normalize file name if (file != NULL && !normalize(file)) { delete [] file; file = NULL; delete [] host; host = NULL; } } } /* Constructor : read the url from a file (cf serialize) */ url::url (char *line) { newUrl(); int i=0; // Read depth depth = 0; while (line[i] >= '0' && line[i] <= '9') { depth = 10*depth + line[i] - '0'; i++; } #ifdef URL_TAGS // read tag tag = 0; i++; while (line[i] >= '0' && line[i] <= '9') { tag = 10*tag + line[i] - '0'; i++; } #endif // URL_TAGS int deb = ++i; // Read host while (line[i] != ':') { i++; } line[i] = 0; host = newString(line+deb); i++; // Read port port = 0; while (line[i] >= '0' && line[i] <= '9') { port = 10*port + line[i] - '0'; i++; } #ifndef COOKIES // Read file name file = newString(line+i); #else // COOKIES char *cpos = strchr(line+i, ' '); if (cpos == NULL) { cookie = NULL; } else { *cpos = 0; // read cookies cookie = new char[maxCookieSize]; strcpy(cookie, cpos+1); } // Read file name file = newString(line+i); #endif // COOKIES } /* constructor used by giveBase */ url::url (char *host, uint port, char *file) { newUrl(); initCookie(); this->host = host; this->port = port; this->file = file; } /* Destructor */ url::~url () { delUrl(); delete [] host; delete [] file; #ifdef COOKIES delete [] cookie; #endif // COOKIES } /* Is it a valid url ? */ bool url::isValid () { if (host == NULL) return false; int lh = strlen(host); return file!=NULL && lh < maxSiteSize && lh + strlen(file) + 18 < maxUrlSize; } /* print an URL */ void url::print () { printf("http://%s:%u%s\n", host, port, file); } /* Set depth to max if necessary * try to find the ip addr * answer false if forbidden by robots.txt, true otherwise */ bool url::initOK (url *from) { #if defined(DEPTHBYSITE) || defined(COOKIES) if (strcmp(from->getHost(), host)) { // different site #ifdef DEPTHBYSITE depth = global::depthInSite; #endif // DEPTHBYSITE } else { // same site #ifdef COOKIES if (from->cookie != NULL) { cookie = new char[maxCookieSize]; strcpy(cookie, from->cookie); } #endif // COOKIES } #endif // defined(DEPTHBYSITE) || defined(COOKIES) if (depth < 0) { errno = tooDeep; return false; } NamedSite *ns = global::namedSiteList + (hostHashCode()); if (!strcmp(ns->name, host) && ns->port == port) { switch (ns->dnsState) { case errorDns: errno = fastNoDns; return false; case noConnDns: errno = fastNoConn; return false; case doneDns: if (!ns->testRobots(file)) { errno = fastRobots; return false; } } } return true; } /* return the base of the url */ url *url::giveBase () { int i = strlen(file); assert (file[0] == '/'); while (file[i] != '/') { i--; } char *newFile = new char[i+2]; memcpy(newFile, file, i+1); newFile[i+1] = 0; return new url(newString(host), port, newFile); } /** return a char * representation of the url * give means that you have to delete the string yourself */ char *url::giveUrl () { char *tmp; int i = strlen(file); int j = strlen(host); tmp = new char[18+i+j]; // 7 + j + 1 + 9 + i + 1 // http://(host):(port)(file)\0 strcpy(tmp, "http://"); strcpy (tmp+7, host); j += 7; if (port != 80) { j += sprintf(tmp + j, ":%u", port); } // Copy file name while (i >= 0) { tmp [j+i] = file[i]; i--; } return tmp; } /** write the url in a buffer * buf must be at least of size maxUrlSize * returns the size of what has been written (not including '\0') */ int url::writeUrl (char *buf) { if (port == 80) return sprintf(buf, "http://%s%s", host, file); else return sprintf(buf, "http://%s:%u%s", host, port, file); } /* serialize the url for the Persistent Fifo */ char *url::serialize () { // this buffer is protected by the lock of PersFifo static char statstr[maxUrlSize+40+maxCookieSize]; int pos = sprintf(statstr, "%u ", depth); #ifdef URL_TAGS pos += sprintf(statstr+pos, "%u ", tag); #endif // URL_TAGS pos += sprintf(statstr+pos, "%s:%u%s", host, port, file); #ifdef COOKIES if (cookie != NULL) { pos += sprintf(statstr+pos, " %s", cookie); } #endif // COOKIES statstr[pos] = '\n'; statstr[pos+1] = 0; return statstr; } /* very thread unsafe serialisation in a static buffer */ char *url::getUrl() { static char statstr[maxUrlSize+40]; sprintf(statstr, "http://%s:%u%s", host, port, file); return statstr; } /* return a hashcode for the host of this url */ uint url::hostHashCode () { return siteHashCode (host); } /* return a hashcode for this url */ uint url::hashCode () { unsigned int h=port; unsigned int i=0; while (host[i] != 0) { h = 31*h + host[i]; i++; } i=0; while (file[i] != 0) { h = 31*h + file[i]; i++; } return h % hashSize; } /* parses a url : * at the end, arg must have its initial state, * http:// has allready been suppressed */ void url::parse (char *arg) { int deb = 0, fin = deb; // Find the end of host name (put it into lowerCase) while (arg[fin] != '/' && arg[fin] != ':' && arg[fin] != 0) { fin++; } if (fin == 0) return; // get host name host = new char[fin+1]; for (int i=0; i<fin; i++) { host[i] = lowerCase(arg[i]); } host[fin] = 0; // get port number if (arg[fin] == ':') { port = 0; fin++; while (arg[fin] >= '0' && arg[fin] <= '9') { port = port*10 + arg[fin]-'0'; fin++; } } // get file name if (arg[fin] != '/') { // www.inria.fr => add the final / file = newString("/"); } else { file = newString(arg + fin); } } /** parse a file with base */ void url::parseWithBase (char *u, url *base) { // cat filebase and file if (u[0] == '/') { file = newString(u); } else { uint lenb = strlen(base->file); char *tmp = new char[lenb + strlen(u) + 1]; memcpy(tmp, base->file, lenb); strcpy(tmp + lenb, u); file = tmp; } if (!normalize(file)) { delete [] file; file = NULL; return; } host = newString(base->host); port = base->port; } /** normalize file name * return true if it is ok, false otherwise (cgi-bin) */ bool url::normalize (char *file) { return fileNormalize(file); } /* Does this url starts with a protocol name */ bool url::isProtocol (char *s) { uint i = 0; while (isalnum(s[i])) { i++; } return s[i] == ':'; } #ifdef COOKIES #define addToCookie(s) len = strlen(cookie); \ strncpy(cookie+len, s, maxCookieSize-len); \ cookie[maxCookieSize-1] = 0; /* see if a header contain a new cookie */ void url::addCookie(char *header) { if (startWithIgnoreCase("set-cookie: ", header)) { char *pos = strchr(header+12, ';'); if (pos != NULL) { int len; if (cookie == NULL) { cookie = new char[maxCookieSize]; cookie[0] = 0; } else { addToCookie("; "); } *pos = 0; addToCookie(header+12); *pos = ';'; } } } #endif // COOKIES
global::namedSiteList
NamedSite *global::namedSiteList; namedSiteList = new NamedSite[namedSiteListSize];
class NamedSite { private: /* string used for following CNAME chains (just one jump) */ char *cname; /** we've got a good dns answer * get the robots.txt */ void dnsOK (); /** Cannot get the inet addr * dnsState must have been set properly before the call */ void dnsErr (); /** Delete the old identity of the site */ void newId (); /** put this url in its IPSite */ void transfer (url *u); /** forget this url for this reason */ void forgetUrl (url *u, FetchError reason); public: /** Constructor */ NamedSite (); /** Destructor : never used */ ~NamedSite (); /* name of the site */ char name[maxSiteSize]; /* port of the site */ uint16_t port; /* numbers of urls in ram for this site */ uint16_t nburls; /* fifo of urls waiting to be fetched */ url *fifo[maxUrlsBySite]; uint8_t inFifo; uint8_t outFifo; void putInFifo(url *u); url *getInFifo(); short fifoLength(); /** Is this Site in a dnsSites */ bool isInFifo; /** internet addr of this server */ char dnsState; struct in_addr addr; uint ipHash; /* Date of expiration of dns call and robots.txt fetch */ time_t dnsTimeout; /** test if a file can be fetched thanks to the robots.txt */ bool testRobots(char *file); /* forbidden paths : given by robots.txt */ Vector<char> forbidden; /** Put an url in the fifo * If there are too much, put it back in UrlsInternal * Never fill totally the fifo => call at least with 1 */ void putGenericUrl(url *u, int limit, bool prio); inline void putUrl (url *u) { putGenericUrl(u, 15, false); } inline void putUrlWait (url *u) { putGenericUrl(u, 10, false); } inline void putPriorityUrl (url *u) { putGenericUrl(u, 5, true); } inline void putPriorityUrlWait (url *u) { putGenericUrl(u, 1, true); } /** Init a new dns query */ void newQuery (); /** The dns query ended with success */ void dnsAns (adns_answer *ans); /** we got the robots.txt, transfer what must be in IPSites */ void robotsResult (FetchError res); };
/////////////////////////////////////////////////////////// // class NamedSite /////////////////////////////////////////////////////////// /** Constructor : initiate fields used by the program */ NamedSite::NamedSite () { name[0] = 0; nburls = 0; inFifo = 0; outFifo = 0; isInFifo = false; dnsState = waitDns; cname = NULL; } /** Destructor : This one is never used */ NamedSite::~NamedSite () { assert(false); } /* Management of the Fifo */ void NamedSite::putInFifo(url *u) { fifo[inFifo] = u; inFifo = (inFifo + 1) % maxUrlsBySite; assert(inFifo!=outFifo); } url *NamedSite::getInFifo() { assert (inFifo != outFifo); url *tmp = fifo[outFifo]; outFifo = (outFifo + 1) % maxUrlsBySite; return tmp; } short NamedSite::fifoLength() { return (inFifo + maxUrlsBySite - outFifo) % maxUrlsBySite; } /* Put an url in the fifo if their are not too many */ void NamedSite::putGenericUrl(url *u, int limit, bool prio) { if (nburls > maxUrlsBySite-limit) { // Already enough Urls in memory for this Site // first check if it can already be forgotten if (!strcmp(name, u->getHost())) { if (dnsState == errorDns) { nburls++; forgetUrl(u, noDNS); return; } if (dnsState == noConnDns) { nburls++; forgetUrl(u, noConnection); return; } if (u->getPort() == port && dnsState == doneDns && !testRobots(u->getFile())) { nburls++; forgetUrl(u, forbiddenRobots); return; } } // else put it back in URLsDisk refUrl(); global::inter->getOne(); if (prio) { global::URLsPriorityWait->put(u); } else { global::URLsDiskWait->put(u); } } else { nburls++; if (dnsState == waitDns || strcmp(name, u->getHost()) || port != u->getPort() || global::now > dnsTimeout) { // dns not done or other site putInFifo(u); addNamedUrl(); // Put Site in fifo if not yet in if (!isInFifo) { isInFifo = true; global::dnsSites->put(this); } } else switch (dnsState) { case doneDns: transfer(u); break; case errorDns: forgetUrl(u, noDNS); break; default: // noConnDns forgetUrl(u, noConnection); } } } /** Init a new dns query */ void NamedSite::newQuery () { // Update our stats newId(); if (global::proxyAddr != NULL) { // we use a proxy, no need to get the sockaddr // give anything for going on siteSeen(); siteDNS(); // Get the robots.txt dnsOK(); } else if (isdigit(name[0])) { // the name already in numbers-and-dots notation siteSeen(); if (inet_aton(name, &addr)) { // Yes, it is in numbers-and-dots notation siteDNS(); // Get the robots.txt dnsOK(); } else { // No, it isn't : this site is a non sense dnsState = errorDns; dnsErr(); } } else { // submit an adns query global::nbDnsCalls++; adns_query quer = NULL; adns_submit(global::ads, name, (adns_rrtype) adns_r_addr, (adns_queryflags) 0, this, &quer); } } /** The dns query ended with success * assert there is a freeConn */ void NamedSite::dnsAns (adns_answer *ans) { if (ans->status == adns_s_prohibitedcname) { if (cname == NULL) { // try to find ip for cname of cname cname = newString(ans->cname); global::nbDnsCalls++; adns_query quer = NULL; adns_submit(global::ads, cname, (adns_rrtype) adns_r_addr, (adns_queryflags) 0, this, &quer); } else { // dns chains too long => dns error // cf nslookup or host for more information siteSeen(); delete [] cname; cname = NULL; dnsState = errorDns; dnsErr(); } } else { siteSeen(); if (cname != NULL) { delete [] cname; cname = NULL; } if (ans->status != adns_s_ok) { // No addr inet dnsState = errorDns; dnsErr(); } else { siteDNS(); // compute the new addr memcpy (&addr, &ans->rrs.addr->addr.inet.sin_addr, sizeof (struct in_addr)); // Get the robots.txt dnsOK(); } } } /** we've got a good dns answer * get the robots.txt * assert there is a freeConn */ void NamedSite::dnsOK () { Connexion *conn = global::freeConns->get(); char res = getFds(conn, &addr, port); if (res != emptyC) { conn->timeout = timeoutPage; if (global::proxyAddr != NULL) { // use a proxy conn->request.addString("GET http://"); conn->request.addString(name); char tmp[15]; sprintf(tmp, ":%u", port); conn->request.addString(tmp); conn->request.addString("/robots.txt HTTP/1.0\r\nHost: "); } else { // direct connection conn->request.addString("GET /robots.txt HTTP/1.0\r\nHost: "); } conn->request.addString(name); conn->request.addString(global::headersRobots); conn->parser = new robots(this, conn); conn->pos = 0; conn->err = success; conn->state = res; } else { // Unable to get a socket global::freeConns->put(conn); dnsState = noConnDns; dnsErr(); } } /** Cannot get the inet addr * dnsState must have been set properly before the call */ void NamedSite::dnsErr () { FetchError theErr; if (dnsState == errorDns) { theErr = noDNS; } else { theErr = noConnection; } int ss = fifoLength(); // scan the queue for (int i=0; i<ss; i++) { url *u = getInFifo(); if (!strcmp(name, u->getHost())) { delNamedUrl(); forgetUrl(u, theErr); } else { // different name putInFifo(u); } } // where should now lie this site if (inFifo==outFifo) { isInFifo = false; } else { global::dnsSites->put(this); } } /** test if a file can be fetched thanks to the robots.txt */ bool NamedSite::testRobots(char *file) { uint pos = forbidden.getLength(); for (uint i=0; i<pos; i++) { if (robotsMatch(forbidden[i], file)) return false; } return true; } /** Delete the old identity of the site */ void NamedSite::newId () { // ip expires or new name or just new port // Change the identity of this site #ifndef NDEBUG if (name[0] == 0) { addsite(); } #endif // NDEBUG url *u = fifo[outFifo]; strcpy(name, u->getHost()); port = u->getPort(); dnsTimeout = global::now + dnsValidTime; dnsState = waitDns; } /** we got the robots.txt, * compute ipHashCode * transfer what must be in IPSites */ void NamedSite::robotsResult (FetchError res) { bool ok = res != noConnection; if (ok) { dnsState = doneDns; // compute ip hashcode if (global::proxyAddr == NULL) { ipHash=0; char *s = (char *) &addr; for (uint i=0; i<sizeof(struct in_addr); i++) { ipHash = ipHash*31 + s[i]; } } else { // no ip and need to avoid rapidFire => use hostHashCode ipHash = this - global::namedSiteList; } ipHash %= IPSiteListSize; } else { dnsState = noConnDns; } int ss = fifoLength(); // scan the queue for (int i=0; i<ss; i++) { url *u = getInFifo(); if (!strcmp(name, u->getHost())) { delNamedUrl(); if (ok) { if (port == u->getPort()) { transfer(u); } else { putInFifo(u); } } else { forgetUrl(u, noConnection); } } else { putInFifo(u); } } // where should now lie this site if (inFifo==outFifo) { isInFifo = false; } else { global::dnsSites->put(this); } } void NamedSite::transfer (url *u) { if (testRobots(u->getFile())) { if (global::proxyAddr == NULL) { memcpy (&u->addr, &addr, sizeof (struct in_addr)); } global::IPSiteList[ipHash].putUrl(u); } else { forgetUrl(u, forbiddenRobots); } } void NamedSite::forgetUrl (url *u, FetchError reason) { urls(); fetchFail(u, reason); answers(reason); nburls--; delete u; global::inter->getOne(); }
其中两个类的定义
larbin-2.6.3/src/utils/PersistentFifo.h、larbin-2.6.3/src/utils/PersistentFifo.cc
// Larbin // Sebastien Ailleret // 06-01-00 -> 12-06-01 /* this fifo is stored on disk */ #ifndef PERSFIFO_H #define PERSFIFO_H #include <dirent.h> #include <unistd.h> #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> #include <errno.h> #include <string.h> #include "types.h" #include "utils/url.h" #include "utils/text.h" #include "utils/connexion.h" #include "utils/mypthread.h" class PersistentFifo { protected: uint in, out; #ifdef THREAD_OUTPUT pthread_mutex_t lock; #endif // number of the file used for reading uint fileNameLength; // name of files int fin, fout; char *fileName; protected: // Make fileName fit with this number void makeName(uint nb); // Give a file name for this int int getNumber(char *file); // Change the file used for reading void updateRead (); // Change the file used for writing void updateWrite (); protected: // buffer used for readLine char outbuf[BUF_SIZE]; // number of char used in this buffer uint outbufPos; // buffer used for readLine char buf[BUF_SIZE]; // number of char used in this buffer uint bufPos, bufEnd; // sockets for reading and writing int rfds, wfds; protected: // read a line on rfds char *readLine (); // write an url in the out file (buffered write) void writeUrl (char *s); // Flush the out Buffer in the outFile void flushOut (); public: PersistentFifo (bool reload, char *baseName); ~PersistentFifo (); /* get the first object (non totally blocking) * return NULL if there is none */ url *tryGet (); /* get the first object (non totally blocking) * probably crash if there is none */ url *get (); /* add an object in the fifo */ void put (url *obj); /* how many items are there inside ? */ int getLength (); }; #endif // PERSFIFO_H
// Larbin // Sebastien Ailleret // 27-05-01 -> 04-01-02 #include <string.h> #include <assert.h> #include <stdlib.h> #include <stdio.h> #include <string.h> #include <ctype.h> #include <iostream.h> #include "types.h" #include "global.h" #include "utils/mypthread.h" #include "utils/PersistentFifo.h" PersistentFifo::PersistentFifo (bool reload, char *baseName) { fileNameLength = strlen(baseName)+5; fileName = new char[fileNameLength+2]; strcpy(fileName, baseName); fileName[fileNameLength+1] = 0; outbufPos = 0; bufPos = 0; bufEnd = 0; mypthread_mutex_init(&lock, NULL); if (reload) { DIR *dir = opendir("."); struct dirent *name; fin = -1; fout = -1; name = readdir(dir); while (name != NULL) { if (startWith(fileName, name->d_name)) { int tmp = getNumber(name->d_name); if (fin == -1) { fin = tmp; fout = tmp; } else { if (tmp > fin) { fin = tmp; } if (tmp < fout) { fout = tmp; } } } name = readdir(dir); } if (fin == -1) { fin = 0; fout = 0; } if (fin == fout && fin != 0) { cerr << "previous crawl was too little, cannot reload state\n" << "please restart larbin with -scratch option\n"; exit(1); } closedir(dir); in = (fin - fout) * urlByFile; out = 0; makeName(fin); wfds = creat (fileName, S_IRUSR | S_IWUSR); makeName(fout); rfds = open (fileName, O_RDONLY); } else { // Delete old fifos DIR *dir = opendir("."); struct dirent *name; name = readdir(dir); while (name != NULL) { if (startWith(fileName, name->d_name)) { unlink(name->d_name); } name = readdir(dir); } closedir(dir); fin = 0; fout = 0; in = 0; out = 0; makeName(0); wfds = creat (fileName, S_IRUSR | S_IWUSR); rfds = open (fileName, O_RDONLY); } } PersistentFifo::~PersistentFifo () { mypthread_mutex_destroy (&lock); close(rfds); close(wfds); } url *PersistentFifo::tryGet () { url *tmp = NULL; mypthread_mutex_lock(&lock); if (in != out) { // The stack is not empty char *line = readLine(); tmp = new url(line); out++; updateRead(); } mypthread_mutex_unlock(&lock); return tmp; } url *PersistentFifo::get () { mypthread_mutex_lock(&lock); char *line = readLine(); url *res = new url(line); out++; updateRead(); mypthread_mutex_unlock(&lock); return res; } /** Put something in the fifo * The objet is then deleted */ void PersistentFifo::put (url *obj) { mypthread_mutex_lock(&lock); char *s = obj->serialize(); // statically allocated string writeUrl(s); in++; updateWrite(); mypthread_mutex_unlock(&lock); delete obj; } int PersistentFifo::getLength () { return in - out; } void PersistentFifo::makeName (uint nb) { for (uint i=fileNameLength; i>=fileNameLength-5; i--) { fileName[i] = (nb % 10) + '0'; nb /= 10; } } int PersistentFifo::getNumber (char *file) { uint len = strlen(file); int res = 0; for (uint i=len-6; i<=len-1; i++) { res = (res * 10) + file[i] - '0'; } return res; } void PersistentFifo::updateRead () { if ((out % urlByFile) == 0) { close(rfds); makeName(fout); unlink(fileName); makeName(++fout); rfds = open(fileName, O_RDONLY); in -= out; out = 0; assert(bufPos == bufEnd); } } void PersistentFifo::updateWrite () { if ((in % urlByFile) == 0) { flushOut(); close(wfds); makeName(++fin); wfds = creat(fileName, S_IRUSR | S_IWUSR); #ifdef RELOAD global::seen->save(); #ifdef NO_DUP global::hDuplicate->save(); #endif #endif } } /* read a line from the file * uses a buffer */ char *PersistentFifo::readLine () { if (bufPos == bufEnd) { bufPos = 0; bufEnd = 0; buf[0] = 0; } char *posn = strchr(buf + bufPos, '\n'); while (posn == NULL) { if (!(bufEnd - bufPos < maxUrlSize + 40 + maxCookieSize)) { printf(fileName); printf(buf+bufPos); } if (bufPos*2 > BUF_SIZE) { bufEnd -= bufPos; memmove(buf, buf+bufPos, bufEnd); bufPos = 0; } int postmp = bufEnd; bool noRead = true; while (noRead) { int rd = read(rfds, buf+bufEnd, BUF_SIZE-1-bufEnd); switch (rd) { case 0 : // We need to flush the output in order to read it flushOut(); break; case -1 : // We have a trouble here if (errno != EINTR) { cerr << "Big Problem while reading (persistentFifo.h)\n"; perror("reason"); assert(false); } else { perror("Warning in PersistentFifo: "); } break; default: noRead = false; bufEnd += rd; buf[bufEnd] = 0; break; } } posn = strchr(buf + postmp, '\n'); } *posn = 0; char *res = buf + bufPos; bufPos = posn + 1 - buf; return res; } // write an url in the out file (buffered write) void PersistentFifo::writeUrl (char *s) { size_t len = strlen(s); assert(len < maxUrlSize + 40 + maxCookieSize); if (outbufPos + len < BUF_SIZE) { memcpy(outbuf + outbufPos, s, len); outbufPos += len; } else { // The buffer is full flushOut (); memcpy(outbuf + outbufPos, s, len); outbufPos = len; } } // Flush the out Buffer in the outFile void PersistentFifo::flushOut () { ecrireBuff (wfds, outbuf, outbufPos); outbufPos = 0; }
Larbin-2.6.3/src/utils/syncFifo.h
// Larbin // Sebastien Ailleret // 09-11-99 -> 07-12-01 /* fifo in RAM with synchronisations */ #ifndef SYNCFIFO_H #define SYNCFIFO_H #define std_size 100 #include "utils/mypthread.h" template <class T> class SyncFifo { protected: uint in, out; uint size; T **tab; #ifdef THREAD_OUTPUT pthread_mutex_t lock; pthread_cond_t nonEmpty; #endif public: /* Specific constructor */ SyncFifo (uint size = std_size); /* Destructor */ ~SyncFifo (); /* get the first object */ T *get (); /* get the first object (non totally blocking) * return NULL if there is none */ T *tryGet (); /* add an object in the Fifo */ void put (T *obj); /* how many itmes are there inside ? */ int getLength (); }; template <class T> SyncFifo<T>::SyncFifo (uint size) { tab = new T*[size]; this->size = size; in = 0; out = 0; mypthread_mutex_init (&lock, NULL); mypthread_cond_init (&nonEmpty, NULL); } template <class T> SyncFifo<T>::~SyncFifo () { delete [] tab; mypthread_mutex_destroy (&lock); mypthread_cond_destroy (&nonEmpty); } template <class T> T *SyncFifo<T>::get () { T *tmp; mypthread_mutex_lock(&lock); mypthread_cond_wait(in == out, &nonEmpty, &lock); tmp = tab[out]; out = (out + 1) % size; mypthread_mutex_unlock(&lock); return tmp; } template <class T> T *SyncFifo<T>::tryGet () { T *tmp = NULL; mypthread_mutex_lock(&lock); if (in != out) { // The stack is not empty tmp = tab[out]; out = (out + 1) % size; } mypthread_mutex_unlock(&lock); return tmp; } template <class T> void SyncFifo<T>::put (T *obj) { mypthread_mutex_lock(&lock); tab[in] = obj; if (in == out) { mypthread_cond_broadcast(&nonEmpty); } in = (in + 1) % size; if (in == out) { T **tmp; tmp = new T*[2*size]; for (uint i=out; i<size; i++) { tmp[i] = tab[i]; } for (uint i=0; i<in; i++) { tmp[i+size] = tab[i]; } in += size; size *= 2; delete [] tab; tab = tmp; } mypthread_mutex_unlock(&lock); } template <class T> int SyncFifo<T>::getLength () { int tmp; mypthread_mutex_lock(&lock); tmp = (in + size - out) % size; mypthread_mutex_unlock(&lock); return tmp; } #endif // SYNCFIFO_H