矩阵连乘
1.两个矩阵乘积所需要的计算量
首先需要考虑计算两个矩阵的乘积所需要的计算量。
矩阵A和矩阵B可乘的条件是A的列数等于B的行数。如果A是一个p*q矩阵,B是一个q*r矩阵,那么AB的乘积C则是一个p*r矩阵。
大致代码如下:
#include
using namespace std;
/*两个矩阵乘法的标准算法*/
void matrixMultiply(int matrixA[][3], int matrixB[][2], int result[2][2], int rowA, int colA, int rowB, int colB) {
if (colA != rowB) {
cout << "矩阵不可乘" << endl;
return ;
}
for (int i = 0; i < rowA; i++) {
for (int j = 0; j < colB; j++) {
int sum = matrixA[i][0] * matrixB[0][j];
for(int k = 1; k < colA; k++) {
sum += matrixA[i][k] * matrixB[k][j];
}
result[i][j] = sum;
}
}
}
int main() {
int a[][3] = {
{1, 2, 3},
{3, 2, 1}
};
int b[][2] = {
{1, 2},
{3, 4},
{5, 6}
};
int result[2][2] = {};
//计算
//a == &a[0];
matrixMultiply(a, b, result, 2, 3, 3, 2);
return 0;
} 从上面的代码可知,主要的计算量在于三重循环。也就是说,对于C=AB来说,需要p*q*r次数乘。
关于matrixMultiply()的形参为int [][2],请参看:C语言中如何将二维数组作为函数的参数传递
按照上面帖子,关于数组传递的较好的办法就是使用一维数组来代替二维数组,比如一个二维数组M p * q,那么获取m[i][j]表示获取第i行的第j个,那么转为一维数组则变为了m[i * q + j]。
2.矩阵连乘问题
假设当前有三个矩阵{A1, A2, A3},那么共有2种计算方式。设这三个矩阵的维数分别为10*100, 100*5,和5*50。
- 如果按照((A1A2)A3)进行计算的话,这三个矩阵的数乘次数为10*100*5 + 10*5*50=7500。
- 如果按照(A1(A2A3))进行计算的话,这三个矩阵的数乘次数为100*5*50 + 10*100*50=75000。
由此可见,矩阵连乘的计算次序对计算量有着很大影响。那么问题就在于如何确定计算矩阵连乘积A1A2...An的计算次序,使得依次计算矩阵连乘需要的数乘次数最少?
3.穷举法
比较容易想到的就是使用穷举法。
对于n个矩阵的连乘积,设有不同的计算次序P(n)。由于可以先在第k个和第k+1个矩阵之间将原矩阵分为两个矩阵子序列,k=1,2,3....n,得到P(k)* P(n-k)然后分别对这两个矩阵子序列完全加括号;最后对所得的结果加括号,得到了原矩阵序列的一种完全加括号方式。由此,可以知道关于P(n)的递归式如下:
P(n)实际上是Catalan数,即P(n)=C(n-1) 。也就是说,P(n)是随着n的增长呈指数增长的,此方法不是一个有效的算法。
- 当n=1时,P(n)=1
- 当n>1时,
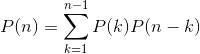
4.动态规划
使用动态规划的一个明显的特征就是问题的最优解包含了子问题的最优解。其次则是重叠子问题。
- 当问题具有最优子结构,即问题的最优解包含子问题的最优解时,我们则可以通过自底向上的方式递归地从子问题的最优解得到原问题的最优解。
- 当问题具有重叠子问题时,在用递归自顶向下解此问题的时候,每次产生的问题并不总是新问题,有些子问题被反复计算多次,此时可以考虑使用备忘录方法(动态规划的一个变形)。
4.1 分析最优解的结构
将A[i:j]记为矩阵连乘积![]() 。那么要求解的就是A[1:n]的最优计算次序。假设这个计算次序在矩阵
。那么要求解的就是A[1:n]的最优计算次序。假设这个计算次序在矩阵 和
和![]() 之间将矩阵断开(1<=k
之间将矩阵断开(1<=k![]() 。然后将计算结果相乘后得到A[1:n]的一个解。
。然后将计算结果相乘后得到A[1:n]的一个解。
计算A[1:n]的最优次序所包含的计算矩阵子链A[1:k]和A[k+1:n]的次序也是最优的。
4.2 建立递归关系
设计算A[i:j] (1 <= i <= j <= n) 所需要的最少数乘次数为m[i][j],那么m[1][n]的值就是原问题的最优值。
- 当i=j时,A[i:j] 表示的为单一矩阵,此时不需要计算,因此m[i][j] = 0
- 当i < j时,可以利用最优子结构的性质来计算m[i][j]。若计算A[i:j]的最优次序在和
 之间断开,i <= k < j。那么有
之间断开,i <= k < j。那么有![m[i][j] = m[i][k] + m[k+1][j] + p_{i-1}p_{k}p_{j}](http://img.e-com-net.com/image/info8/4a364fbc37054ad099b8cc2926e6b7b5.gif)
k值有j-i种可能。k应该取这j-i个位置中使得m[i][j]计算量达到最小的那个位置。
注:![]() 表示数乘的次数,这里令数组p保存着可连乘矩阵的行列,那么第一个矩阵
表示数乘的次数,这里令数组p保存着可连乘矩阵的行列,那么第一个矩阵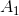 的行列为p[0] * p[1]。第二个矩阵
的行列为p[0] * p[1]。第二个矩阵 的行列为p[1] * p[2],的行列为p[k-1] * p[k]。那么
的行列为p[1] * p[2],的行列为p[k-1] * p[k]。那么![]() 。
。
4.3 计算最优值
根据m[i][j]的递归式,可以很容易地计算m[1][n]。用动态规划解决此类问题的时候,可以依据其递归式自底向上的方式进行计算。另外,在计算过程种,记录每个子问题的答案,以使得每个子问题只计算一次,在之后只需要简单查一下即可。
代码如下:
/**
* 矩阵连乘的最优计算次序
* @param p: 矩阵的行列数数组
* @param n: p的长度, n-1表示矩阵的个数
* @param m: 最优值二维数组 m[n+1][n+1]
* @param s: 最优解二维数组 s[n+1][n+1]
*/
void matrixChain(int* p, int n, int*** m, int*** s) {
//最优值
int** answer = new int* [n + 1];
//n维数组
for (int i = 1; i <= n; i++) {
answer[i] = new int[n + 1];
memset(answer[i], 0, sizeof(int) * (n + 1));
}
//最优解
int** path = new int* [n + 1];
for (int i = 1; i <= n; i++) {
path[i] = new int[n + 1];
memset(path[i], 0, sizeof(int) * (n + 1));
}
//初始化 answer[0][0] = 0
for (int i = 1; i <= n; i++)
answer[i][i] = 0;
for (int r = 2; r <= n; r++) {
for (int i = 1; i <= n - r + 1; i++) {
int j = i + r - 1;
//计算 i <= k <= j m[i][j]的最优值
//k == i
answer[i][j] = answer[i + 1][j] + p[i - 1] * p[i] * p[j];
path[i][j] = i;
//选择一个最优解
for (int k = i + 1; k < j; k++) {
int t = answer[i][k] + answer[k + 1][j] + p[i - 1] * p[k] * p[j];
if (t < answer[i][j]) {
answer[i][j] = t;
path[i][j] = k;
}
}
}
}
if (m != nullptr)
* m = answer;
if (s != nullptr)
* s = path;
}martixChain先构造了两个二维数组,其中answer用来保存之前所说的最优值m;而path则用来保存k的值。换句话说,path[i][j]保存的值就是在![]() 矩阵连乘中,从path[i][j]断开能得到最优值。以此递归,即得到最优解。
矩阵连乘中,从path[i][j]断开能得到最优值。以此递归,即得到最优解。
之后matrixChain先计算出了answer[i][i]=0。然后,有三个for循环,最外侧循环r表示的是矩阵链长度,它表示的是相乘的相邻矩阵个数;中间的循环则是依次计算这些矩阵链。根据上面的for循环,它们首先按照矩阵链长递增的方式以此计算m[i][i+1],i=1, 2, ..., n-1(矩阵链长度为2);m[i][i+2], i = 1, 2, 3, ..., n- 2(矩阵链长度为3)。这样在计算m[i][j]时,只用到了已经计算出来的m[i][k]和m[k+1][j]。
最内侧的循环是为了求解出![]() 中m[i][j]的最小值。
中m[i][j]的最小值。
4.4 构造最优解
matrixChain有两个返回值,分别是最优值answer和最优解path,我们可以递归调用得到最优解。path[i][j]中的数表明,计算矩阵链A[i:j]的最佳方式应在矩阵和![]() 之间断开,即最优的加括号方式为(A[i:k])(A[k+1:j])。以此递归,则可以得到一个最优解。
之间断开,即最优的加括号方式为(A[i:k])(A[k+1:j])。以此递归,则可以得到一个最优解。
void traceback(int i, int j, int** s) {
if (i == j)
return;
traceback(i, s[i][j], s);
traceback(s[i][j] + 1, j, s);
cout << "Multiply A" << i << "," << s[i][j];
cout << "and A" << (s[i][j] + 1) << "," << j << endl;
}4.5 测试
int main() {
int p[] = { 30, 35, 15, 5, 10, 20, 25 };
int len = sizeof(p) / sizeof(p[0]);
int** m;
int** s;
matrixChain(p, len - 1, &m, &s);
//输出最优值
for (int i = 1; i < len; i++) {
for (int j = 1; j < len; j++) {
cout << m[i][j] << "\t";
}
cout << endl;
}
cout << endl;
//最优解
for (int i = 1; i < len; i++) {
for (int j = 1; j < len; j++) {
cout << s[i][j] << "\t";
}
cout << endl;
}
traceback(1, 6, s);
return 0;
}输出如下:

5.备忘录方法
备忘录方法是动态规划方法的变形。动态规划是自底向上的,而备忘录方法则是自顶向下的。 备忘录为每个子问题建立一个记录项,若记录项中存储的是初始化的特殊值,则计算该子问题的解,否则直接返回即可。
根据之前得到的递归式,可以直接根据递归式得到程序:
/**
* 备忘录方法求解矩阵连乘
* @param p: 矩阵的行列数数组
* @param n: p的长度, n-1表示矩阵的个数
* @param m: 最优值二维数组 m[n+1][n+1]
* @param s: 最优解二维数组 s[n+1][n+1]
* @return : m[1:n]的最小连乘次数
*/
int memoizedMatrixChain(int* p, int n, int*** m, int*** s) {
//最优值
int** answer = new int* [n + 1];
//n维数组
for (int i = 1; i <= n; i++) {
answer[i] = new int[n + 1];
memset(answer[i], 0, sizeof(int) * (n + 1));
}
//最优解
int** path = new int* [n + 1];
for (int i = 1; i <= n; i++) {
path[i] = new int[n + 1];
memset(path[i], 0, sizeof(int) * (n + 1));
}
int min = lookupChain(p, n, answer, path, 1, n);
if (m != nullptr)
* m = answer;
if (s != nullptr)
* s = path;
return min;
}
之前是类似的,answer/m矩阵的默认初始特殊值为0,因为除了m[i:i]=0外,其余的值都不可能为0。之后调用lookupChain()函数获得最优值。
/**
* 获取m[i:j]的最小连乘次数并返回
* @param p: 矩阵的行列数数组
* @param n: p的长度, n-1表示矩阵的个数
* @param m: 最优值二维数组 m[n+1][n+1]
* @param s: 最优解二维数组 s[n+1][n+1]
* @param i: 起始矩阵位置
* @param j: 结束矩阵位置
* @return : m[i:j]的最小连乘次数
*/
int lookupChain(int* p, int n, int** m, int** s, int i, int j) {
if (m[i][j] > 0)
return m[i][j];
if (i == j)
return 0;
int u = lookupChain(p, n, m, s, i + 1, j) + p[i - 1] * p[i] * p[j];
s[i][j] = i;
for (int k = i + 1; k < j; k++) {
int t = lookupChain(p, n, m, s, i, k) + lookupChain(p, n, m, s, k + 1, j) + p[i - 1] * p[k] * p[j];
if (t < u) {
u = t;
s[i][j] = k;
}
}
m[i][j] = u;
return u;
}lookupChain()函数的功能就是获取m[i:j]的值,如果m[i][j]存在不为0的值,则直接返回;如果i== j,则表示A[i:j] 为单一矩阵,此时无需计算,则直接返回0即可。之后则是获取m[i:j]中在k位置断裂时的m[i:j]数乘次数的最小值。
6.总结
动态规划的基本要素为:
- 最优子结构性质
- 重叠子问题性质
动态规划适合求最优化问题。另外,动态规划的一个变形是备忘录方法。动态规划是自底向上,由子问题的最优解得到原问题的最优解;而备忘录方法则是自顶向下,原问题的最优解能分解成子问题的最优解,且存在大量重复子问题。
一般来讲,当一个问题的所有子问题都至少要解一次时,用动态规划算法比备忘录方法要好。
7.参考
- 《计算机算法设计与分析 王晓东》