- 20199123 2019-2020-2 《网络攻防实践》期末大作业
- 1 论文介绍
- 1.1 引入
- 1.2 背景介绍
- 1.3 论文核心点
- 2 核心算法
- 2.1 DLFuzz结构
- 2.2 变异算法
- 2.3 代码解析
- 2.3.1 基于梯度的优化
- 2.3.2 模糊化过程
- 2.3.3 优化策略
- 3 实验复现
- 3.1 环境配置
- 3.2 对比实验
- 3.3 实验复现——ImageNet
- 3.4 实验复现——MNIST
- 4 实验思考
- 5 学习总结和建议意见
- 参考资料
- 1 论文介绍
20199123 2019-2020-2 《网络攻防实践》期末大作业
我选择的论文是DLFuzz: Differential Fuzzing Testing of Deep Learning Systems我将从论文介绍、核心算法、实验复现、实验思考四个部分来介绍这篇论文以及我复现的一些结果与思考。
1 论文介绍
1.1 引入
深度学习高速发展至今,但却难以解决debug和解释的问题,导致可重复性危机,因此AI debug显得越来越有需求。从工程角度看,算法开发人员很难解释新版模型比之前版本优异之处,模型在测试集上表现优异,但是线上表现仍然会让人担忧,因此模型的覆盖率白盒测试能帮助开发人员从不同的角度理解模型之间的差异性。利用覆盖率帮助算法自动找模型bug,这对于类似自动驾驶等数据集收集难度大的场景帮助很大。
小明:“我们用同样结构的神经网络模型训练,你凭什么说你调的参数比我好?”
小红:“我的模型在测试集上不管是准确率还是auc值(AUC就是衡量学习器优劣的一种性能指标)都比你高啊。”
小明:“呵呵,那你说你的模型究竟哪里比我的好,我看是测试集不够全面,不能测出我的模型的优异处,不信你再造一些测试集看看能不能找到我模型的bad case。”
小红:“你这凭什么说测试集质量好不好?”
简单的例子体现了目前DL模型应用场景的三个问题:
(1) 同样结构,经过调参之后的模型差异在哪里?
(2) 如何对模型进行自动化测试,特别是要求高的安全领域?
(3) 如何对测试集进行判断优劣?
在判断测试集的优劣时,从传统意义上采用代码覆盖率这一概念判断测试集的优劣,代码覆盖率(Code coverage)是软件测试中的一种度量,描述程序中源代码被测试的比例和程度,所得比例称为代码覆盖率。但与传统软件不同,DL(Deep Learning)系统的大多数规则不是由程序员手工编写,而是从训练数据中学习,因此代码覆盖本身并不是评估DL系统覆盖率的一个好的度量标准。由此在Yinzhi Cao在deepxplore automated whitebox testing of deep learning systems中借鉴传统代码覆盖率的概念提出了神经元覆盖率的概念,其指被激活的神经元的占比,被激活的神经元就是输出值大于阈值的单元。
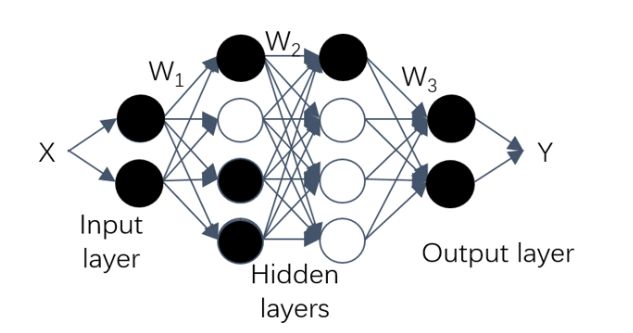
DNN每一层包含多个神经元,每个神经元都是一个包括激活函数的独立的计算单元,给定一个输入,输出对应的结果。如下图2为神经元结构:
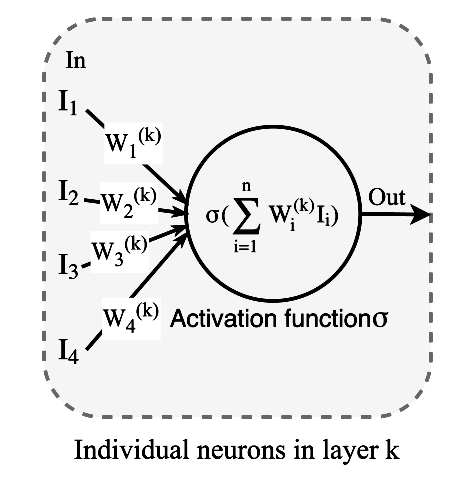
常用的激活函数是sigmoid/tanh/RELU等,如下图所示。激活函数的作为主要是将输入到神经网络中的数据非线性化使得神经网络能够更好表达输入数据的信息。
每一层的神经元都会提取特定的特征信息,然后传到更高层,这就类似传统软件的逻辑分支,如下图所示,左边a图是传统的代码的逻辑分支,b图是输入一个汽车的图像,传入神经网络之后,每个神经元提取信息,然后根据提取的信息对汽车的颜色,轮子等进行概率的评价,最后得到0.95的概率是汽车。这个过程和传统的软件逻辑分支非常相似。

有了这样的认识,那么神经元覆盖率的定义也就很好理解了,覆盖率就是被激活的神经元的占比,被激活的神经元就是输出值大于阈值的单元,DNN所有神经元为集合N={n1,n2,...},测试集则为T={x1,x2,...}那么神经元n的输出就为 out(n,x)。neuron coverage就可以定义为:
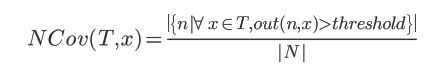
通过上面的分析就能够回答同样的结构,经过调参之后模型的差异在哪里?调参之后,我们可以从覆盖的角度比较同样的测试输入,所激活的神经元的不同。从这一角度,可以给我们一个评判的标准,那就是每一层神经元所提取的特征,不同在何处。
Fuzz本意是“羽毛、细小的毛发、使模糊、变得模糊”,后来用在软件测试领域,中文一般指“模糊测试”,英文有的叫“Fuzzing”,有的叫“Fuzz Testing”。Fuzzing是模糊测试,意味着测试用例的不确定和模糊。在现实中我们无法穷举所有的输入作为测试用例,在编写测试用例时我们也没有办法将所有的输入都遍历进行测试一遍;除此之外,测试人员也无法想到所有可能的异常场景,因此Fuzzing测试就显得尤为重要了。
(1)首先是一种自动化技术,即软件自动执行相对随机的测试用例。因为是依靠计算机软件自动执行,所以测试效率相对人来讲远远高出几个数量级。比如,一个优秀的测试人员,一天能执行的测试用例数量最多也就是几十个,很难达到100个。而Fuzzing工具可能几分钟就可以轻松执行上百个测试用例。
(2)Fuzzing技术本质是依赖随机函数生成随机测试用例,随机性意味着不重复、不可预测,可能有意想不到的输入和结果。
(3)根据概率论里面的“大数定律”,只要我们重复的次数够多、随机性够强,那些概率极低的偶然事件就必然会出现。Fuzzing技术就是大数定律的典范应用,足够多的测试用例和随机性,就可以让那些隐藏的很深很难出现的Bug成为必然现象。
目前,Fuzzing技术已经是软件测试、漏洞挖掘领域的最有效的手段之一。Fuzzing技术特别适合用于发现0 Day漏洞,也是众多黑客或黑帽子发现软件漏洞的首选技术。Fuzzing虽然不能直接达到入侵的效果,但是Fuzzing非常容易找到软件或系统的漏洞,以此为突破口深入分析,就更容易找到入侵路径,这就是黑客喜欢Fuzzing技术的原因。
1.2 背景介绍
深度学习系统在很多领域都展现出了很强的竞争力,例如在图像分类、自然语言处理、自动驾驶、无人机和恶意软件检测领域,所以提高DL系统的健壮性是一个迫切的需求。对于DL测试,经典的方法是收集足够的人工标记数据来评估DL系统的准确性。然而,测试的输入空间非常大,很难收集所有可能的输入来触发DL系统的每个可行逻辑。并且通过在测试输入中添加小扰动可以愚弄最先进的DL系统。尽管DL系统在图像分类任务上表现出令人印象深刻的性能,但通过应用不可察觉的扰动,分类器也很容易导致不正确的分类,因此,DL测试非常具有挑战性,但对于确保这些安全关键实践的正确性是必不可少的。
DLFuzz论文的目标是打破黑盒测试技术的资源消耗限制和白盒测试技术与DLFuzz的交叉引用障碍,DLFuzz是第一个利用不可察觉的扰动来确保输入和变异输入之间的不可见差异的差分模糊测试框架。模糊测试和DL测试有着相似的目标,即实现更高的覆盖率,以及获得更多的异常行为。本论文将模糊化关键阶段的知识组合到DL测试中,如下所示:
(1)优化目标。达到更高的神经元覆盖率和暴露更多异常行为的目标可以看作是一个联合优化问题。这个优化问题可以用基于梯度的方法来实现。
(2)种子养护。在模糊化过程中,根据在随后的模糊化过程中不断提高神经元覆盖率的潜力,将有助于一定程度提高神经元覆盖率的变异输入保留在种子列表中。
(3)突变策略的多样性(针对输入的突变)。我们设计了许多神经元选择策略来选择可能覆盖更多逻辑和触发更多错误输出的神经元。此外,测试输入的多种变异方法已经被实践,并且易于集成。
1.3 论文核心点
DLFuzz这篇论文提出了差分模糊测试框架,其目的是在不交叉参考其他类似的DL系统或人工标注的情况下,最大化神经元覆盖率并为给定的DL系统生成更多的对抗性输入。为了评价DLFuzz的有效性,作者在两个流行的数据集MNIST和ImageNet上对六个DL系统进行了实证研究。DL系统和数据集与DeepXplore使用的完全相同。与DeepXplore相比,DLFuzz不需要额外的努力来收集类似的功能性DL系统来进行交叉引用标签检查,但是可以产生更多的对抗性输入、小扰动和神经元覆盖率。
2 核心算法
2.1 DLFuzz结构

DLFuzz的总体架构如上图所示。本论文将DLFuzz应用于图像分类,以验证其可行性和有效性。其他任务(如语音识别)中的自适应非常简单,也遵循图中相同工作流。
具体来说,给定的测试输入t是要分类的图像,DNN是被测的特定卷积神经网络(CNN),如VGG-16。变异算法对t施加微扰,得到t′,与t明显不可区分,如果变异后的输入t′和原始输入t都被输入到CNN中,但被分类为不同的类别标签,则我们将其视为不正确的行为,而t′是对抗性输入之一。变异前后的分类结果不一致,说明至少有一个是错误的,不需要人工标注。与此相反,如果CNN预测两者属于同一类标签,则t′将继续用变异算法进行变异,以检验CNN的鲁棒性(健壮性)。
其中最重要的部分是变异算法部分。变异算法的优化目标是最大化错误行为和神经元覆盖。在进行变异的过程中,使用基于梯度的方式进行对输入的图像进行优化并且使用预测误差最大化来建立扰动;在提高神经元覆盖率方面使用了模糊化过程,即对原始输入产生多个对抗性输入,并且有4种策略来进行神经元的选择。
2.2 变异算法
变异算法是DLFuzz算法的主要组成部分。它是通过求解一个最大化神经元覆盖率和错误行为数的联合优化问题来完成的。基于覆盖更多神经元可能触发更多逻辑和错误行为,输出值大于设定阈值的神经元被视为被激活(即被覆盖)。变异算法的核心过程如图。该算法包含三个关键部分进行详细讨论。

优化问题。基于梯度的对抗性深度学习在几个方面优于其他方法,特别是在时间效率方面。它通过优化输入以使预测误差最大化来建立扰动,这与在训练DNN时优化权重以使预测误差最小相反。以损耗函数loss为目标,采用梯度上升法使损耗loss最大化,易于实现。DLFuzz的损失函数定义为以下方程(算法1第9行),这也是优化目标:

优化目标由两部分组成。 在第一部分 \(\sum_{i=0}^{k}c_i\) 中,c是输入的原始类标签, \(c_i\) (i=0,…,k)是置信度仅低于(算法1第7行)的顶级k类标签之一。最大化第一部分引导输入越过原始类的决策边界,并位于前k个其他类的决策空间中。这种修改后的输入更可能被错误地分类。在第二部分 \(\sum_{i=0}^{m}n_i\) 中,\(n_i\)是一个将被激活的靶神经元。选择这些神经元时考虑了许多提高神经元覆盖率的策略(算法1第8行)。超参数λ用于平衡两个目标。
模糊化过程。模糊化过程揭示了算法1的总体工作流程。当给定一个测试输入x时,DLFuzz维护一个种子列表,用于保存有助于神经元覆盖的中间变异输入。首先,种子列表只有一个输入,正好是x。然后,DLFuzz遍历每个种子\(x_s\)并获得构成其优化目标的元素。然后,DLFuzz计算梯度方向以备以后的变异。在变异过程中,DLFuzz迭代地将处理后的梯度作为对\(x_s\)的扰动,得到中间输入\(x^\prime\)。每次变异后,得到中间类标签\(c^\prime\),覆盖信息,x和\(x^\prime\)的L2距离。如果需要\(x^\prime\)和L2距离来提高神经元的覆盖率,则将\(x^\prime\)添加到种子列表中。最后,如果\(c^\prime\)已经不同于c,则种子\(x_s\)的突变过程终止,\(x^\prime\)将被包含在对抗性输入集合中。因此,DLFuzz能够对某一原始输入产生多个对抗性输入,为进一步提高神经元覆盖率探索了一条新途径。
对于迭代变异过程,首先,当获得梯度时,有很多种处理方法可用于产生扰动,这些方法的变异策略易于扩展到DLFuzz。其次,DLFuzz采用L2距离测量扰动,以保证x与\(x^\prime\)之间的距离是不可察觉的。对于算法第18行的保存种子的条件,DLFuzz将我们期望的距离限制在一个相对较小的范围内(小于0.02),以确保不可察觉性。当一个输入的神经元覆盖率随着时间的推移而降低时,相应的种子保持阈值也随着时间的推移而降低。此外,DLFuzz的输入和超参数配置对其性能有一定的影响,需要进行一些探索。此外,我们可以提高种子(神经元覆盖的中间变异值)保存的阈值,以保留更多的变异输入与更大的距离。
神经元选择策略。为了最大化神经元覆盖率,我们提出了四种启发式策略来选择更有可能提高覆盖率的神经元,如下所示。对于每个种子x,使用一个或多个策略选择m个神经元,这些策略可以根据算法输入的策略进行定制。
(1)策略1。选择在过去的测试中经常覆盖的神经元。受传统软件测试实践经验的启发,经常或很少执行的代码片段更有可能引入缺陷。经常或很少被覆盖的神经元可能会导致异常的逻辑并激活更多的神经元。
(2)策略2。由于上述考虑,在过去的测试中,选择很少被覆盖的神经元。
(3)策略3。选择权重最大的神经元。这是基于我们的假设,即具有最高权重的神经元可能对其他神经元有更大的影响。
(4)策略4。选择接近激活阈值的神经元。如果激活/去激活输出值略低于/大于阈值的神经元,则更容易加速。
2.3 代码解析
2.3.1 基于梯度的优化
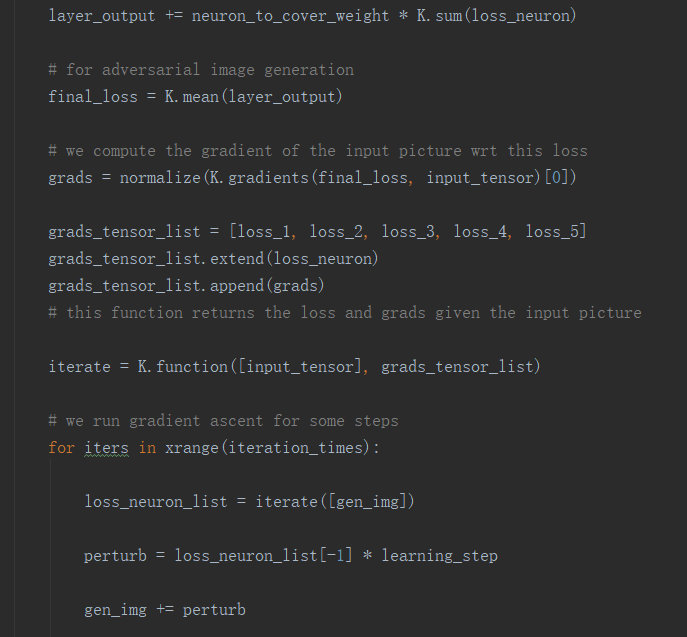
以上是用代码实现的基于梯度的优化,这个论文的代码有个很大的特点是,它采用的是常规的算法的思维,但是却用的是神经网络的架构(Tensorflow&Keras)来实现的,这倒是一个神经网络和算法的完美结合,并且使用python语言可读性很强。
从代码中,可以看到作者使用了final_loss = K.mean(layer_output)语句计算输出的可对抗性图像的loss,紧接着就是计算梯度,然后根据梯度进行迭代计算得到扰动的图像;
2.3.2 模糊化过程
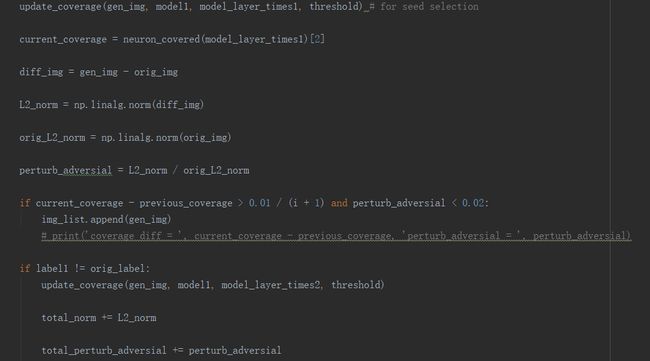
模糊化过程主要是DLFuzz维护一个种子列表,用于保存神经元覆盖的中间变异输入;也就是说利用种子列表来生成变异的输入,并且保存下来,这从代码运行中是可以非常清楚的看到的。根据算法1的描述,模糊的过程是基于上述的梯度优化,利用计算出来的梯度对中间的输入和产生的扰动的图像进行判断,并且计算L2距离和对比类标签信息从而判断是否将这些根据种子列表生成的中间输入即扰动的图像保存下来。
模糊化过程是利用迭代的方式进行的,从而最终实现了变异。为了使最终生成的可对抗性的图像(即扰动的图像)是不被察觉的,论文中利用了L2距离测算扰动,即计算原始的输入图像x和变异的图像(中间产生的扰动图像)\(x^\prime\)之间的距离,在算法1的第18行中保存种子的条件即为将这个L2距离限制在一个相对较小的范围内(小于0.02),以确保不可察觉。
2.3.3 优化策略
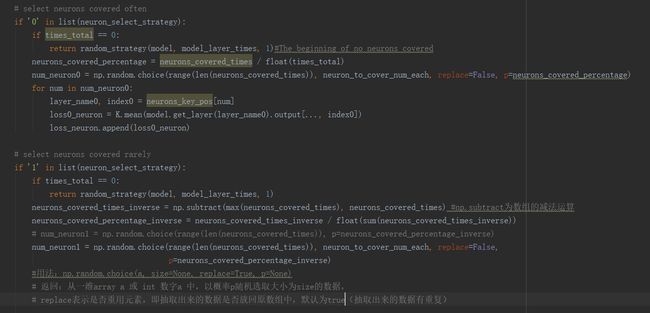

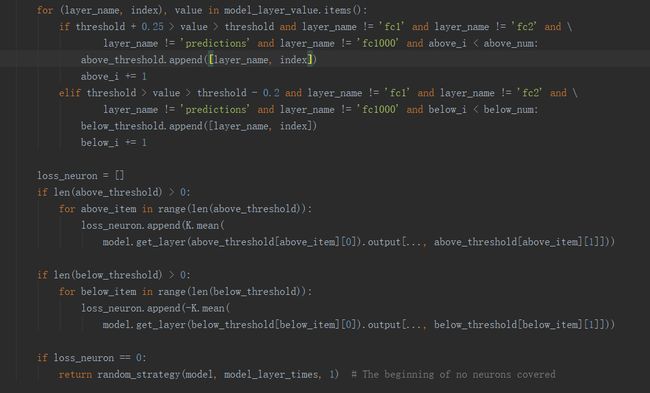
首先贴出了优化策略的代码实现的图,看代码的时候就发现论文的算法和代码是高度契合的,所以非常欣赏这个论文的算法和代码,因此也专门有一小节的代码解析。
在论文中写到选择神经元进行覆盖的策略有4种。(1)策略1,选择在过去的测试中经常覆盖的神经元。(2)策略2,选择很少被覆盖的神经元。(3)策略3,选择权重最大的神经元。(4)策略4,选择接近激活阈值的神经元。如果激活/去激活输出值略低于/大于阈值的神经元,则更容易加速。在代码中对于策略1和2是类似的实现,因为这俩区别只是被覆盖的频率上,在代码中采用了函数np.random.choice();下面以策略1为例进行分析:
num_neuron0=np.random.choice(range(len(neurons_covered_times)), neuron_to_cover_num_each, replace=False, p=neurons_covered_percentage)
从被覆盖的神经元中以被覆盖神经元比例作为概率随机选择每一次被覆盖的神经元个数,并且不放回原数组(原抽取的被覆盖神经元集合)中;
range(len(neurons_covered_times)):计算被覆盖神经元的次数的长度的范围;
neuron_to_cover_num_each:每一次被覆盖的神经元个数;
replace=False:表示不被重用,即抽取出来的数据不放回原数组;
p=neurons_covered_percentage:概率为p,即被覆盖的神经元的比例作为概率;
对于策略3根据权重来选择被覆盖的神经元,则是通过每一层卷积层然后计算top k标签神经元的权重;策略4则是设定阈值进行限定。
3 实验复现
3.1 环境配置
环境需求:
Python 2.7.14
tensorflow-gpu (1.2.1)
Keras (2.1.3)
h5py (2.7.1)
Pillow (5.0.0)
opencv-python
环境配置:
Step 1:安装cuda8.0 cudnn 5.1,由于我是在实验室的ubuntu主机上安装过了,这里就不再详细的介绍了,给出一些参考链接;
https://blog.csdn.net/wanzhen4330/article/details/81699769?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
Step 2:创建conda虚拟环境;
conda create --name DLFuzzing python=2.7.14;
命令行解析:--name为创建的虚拟环境的名字;python=2.7.14为虚拟环境中安装的python版本;
Step 3:在虚拟环境DLFuzzing中安装依赖的包;
conda install tensorflow-gpu==1.2.1;
Step 4:激活conda环境;
Linux -> source activate DLFuzzing;/ conda activate DLFuzzing;
Windows -> activate DLFuzzing;
Step 5:运行;
cd ImageNet
python gen_diff.py [2] 0.25 10 0602 3 vgg16
\#meanings of arguments
\#python gen_diff.py
[2] -> the list of neuron selection strategies
0.25 -> the activation threshold of a neuron
10 -> the number of neurons selected to cover
0602 -> the folder holding the adversarial examples generated
3 -> the number of times for mutation on each seed
vgg16 -> the DL model under test
3.2 对比实验
此论文的作者选择了两个数据集(MNIST和ImageNet)和DeepXplore用于图像分类任务的相应cnn来评估DLFuzz。MNIST是一个包含60000个训练图像和10000个测试图像的手写数字的大型数据集。ImageNet是一个大型的可视化数据集,包含超过1400万个用于对象识别的图像。与DeepXplore相同,DLFuzz对每个数据集测试了三个预先训练的模型,即LeNet-1、LeNet-4、LeNet-5用于MNIST和VGG-16、VGG-19、ResNet50用于ImageNet。此论文在ImageNet数据集上测试了VGG16、VGG19和ResNet50三个网络模型,在代码中是直接下载的已经预训练好的模型参数。
与DeepXplore相比,表中显示了DLFuzz的有效性。DLFuzz在提高神经元覆盖率、在同一时间范围内产生更多的对抗性输入、限制不可察觉的干扰等方面显示出其优越性。首先,如表的第三列所示,对于测试的6个cnn,DLFuzz在不同设置下的平均神经元覆盖率比DeepXplore高1.10%到5.59%。在最佳设置下,DLFuzz能够获得13.42%的神经元覆盖率。(表中a/b,a表示DeepXplore的结果,b表示DLFuzz的结果)

3.3 实验复现——ImageNet
VGGNet是牛津大学计算机视觉组和Google DeepMind公司的研究员仪器研发的深度卷积神经网络。VGG主要探究了卷积神经网络的深度和其性能之间的关系,通过反复堆叠33的小卷积核和22的最大池化层,VGGNet成功的搭建了16-19层的深度卷积神经网络。与之前的state-of-the-art的网络结构相比,识别错误率大幅度下降;同时,VGG的泛化能力非常好,在不同的图片数据集上都有良好的表现。到目前为止,VGG依然经常被用来提取特征图像。
DLFuzz就是生成扰动图像然后在ImageNet数据集上对VGG16、VGG19和ResNet50网络进行标签识别测试。
VGG16结构图如下:

通过输入的种子列表文件夹里的图像和参数的调整,对VGG16模型进行测试,得到的实验结果图如下:
从实验结果图中可以看到,原本的rule尺子,在经过DLFuzz之后再次通过VGG16网络的时候,就被识别为了harmonica(口琴)&pencil_box(铅笔盒);第二行的toy_poodle(玩具贵宾犬)被识别为Bedlington_terrier(贝灵顿猎犬)和Sealyham_terrier(海豹犬)。
VGG19的实验结果图如下:

从实验结果图中可以看到,原本的rule尺子,在经过DLFuzz之后再次通过VGG19网络的时候,就被识别为了bath_towel(浴巾)&pencil_box(铅笔盒);第二行的candle(蜡烛)被识别为wig(假发)和lampshade(灯罩)。

随着网络的加深,梯度崩溃问题会越来越严重,导致网络很难收敛甚至无法收敛。梯度弥散问题目前有很多的解决办法,包括网络初始标准化,数据标准化以及中间层的标准化(Batch Normalization)等。但是网络加深还会带来另外一个问题:随着网络加深,出现训练集准确率下降的现象,所以何凯明大神提出了残差网络。如图15的残差块所示,残差网络能够通过信息传递的方式来减少神经网络层之间的信息传递,从而能够避免梯度的涣散和难以收敛的问题。ResNet50是残差网络的一种,残差网络是VGG网络的升级版本。
DLFuzz在ResNet50上也做了测试,实验结果图如下:
从实验结果图中可以看到,原本的gazelle瞪羚,在经过DLFuzz之后再次通过ResNet50网络的时候,就被识别为了hartebeest(羚羊)&ibex(野山羊);第二行的minivan(小型货车)被识别为beach_wagon(沙滩车)和pickup(皮卡)。

可以看到在生成的扰动图像对三种模型都有不同的错误标签,这不仅说明了DLFuzz结构能够很好的生成扰动图像并且不被察觉(图中生成的扰动图像和原图差异肉眼很难看出来的),而且可以检测出这些网络结构存在识别的漏洞。
3.4 实验复现——MNIST
LeNet网络可以算是最基础的网络结构了,简单的卷积-池化-全连接-分类结构只是为了当时银行支票签字的识别,所以LeNet网络结构适应于MNIST数据集,因为MNIST数据集是很多手写体的数字。

LeNet-1是最基础的网络结构了,其网络结构如下图:
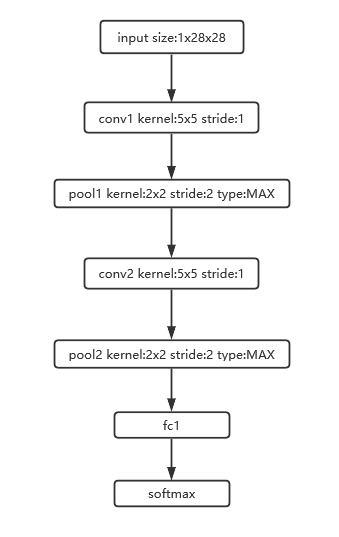
DLFuzz利用种子图像然后变异算法生成了很多扰动的可对抗性的图像,通过LeNet-1网络进行识别,出现原本的4识别为9的错误,如下图所示,第一行为原始种子图像4,第二行是真实的9但却被识别为了4,可以看到9和第一行最后一个数字4非常相似,这也能够说明LeNet-1识别率很低,并且DLFuzz生成的图像起到了很好的扰动作用。


上图为LeNet-4的网络结构图,和LeNet-1相比多了后面的relu激活函数,激活函数在前面介绍过,是为了将线性的神经网络的信息非线性化从而提取更多的信息。DLFuzz生成的扰动图像如下:

图中第一行为通过LeNet-4变异所生成的不可察觉的扰动图像,可以看到图像9仅仅只有细微的差别,第二行为通过LeNet-5变异生成的不可察觉的图像,也是只有4的右侧有一点点扰动的痕迹,这足以看出DLFuzz结构对于生成不可察觉的扰动图像的优势。
4 实验思考
首先这篇论文是将神经网络和安全领域的模糊测试Fuzzing Testing 结合的一篇论文,其提出的DLFuzz结构在DeepXplore的基础上有很好的改进,不仅是在神经元覆盖率上,而且在生成不可察觉的扰动图像方面也有很大的改进。我特别欣赏这篇论文的地方就是其神经网络在安全领域的完美应用,并且作者写的代码非常的规范,使用神经网络的架构Tensorflow&Keras然后用Python语言实现提出的变异算法,感觉和论文中的算法非常的吻合,这让我在读论文之后看代码也有一个思路,反过来从代码补充论文中的算法也是非常清晰的。并且DLFuzz将当下的识别网络都做了变异生成扰动图像,算是比较全面的工作了。
除了上面对论文和代码的一些感受外,其实我当时想的是用GAN(生成对抗网络)来进行改进,这篇论文是在2018年提出来的,那时候已经有GAN网络了但是却没有对GAN进行变异的扰动图生成,所以当时想到说用GAN来做改进,但是想了下GAN网络主要是生成图像领域的使用,GAN使用生成器Encoder生成图像,解码器Decoder去辨别生成的图像的真假,这和这篇论文主要应用于识别图像网络是相悖的,因此这个改进也没有继续进行,反观这也解释了为什么作者选择的是VGG,ResNet,LeNet网络的原因了,这些网络都是识别图像界的翘楚们。
5 学习总结和建议意见
首先很感觉老师给的机会做了一学期的课代表,也很感谢老师和昕睿的支持。最开始我不是选的这门课,由于Linux的老师出国进修,因此我误打误撞进入了攻防,我是完全没有接触过攻防的,所以在最开始做课代表的时候也挺担心,怕自己做的不好,怕课代表也没有学好这门课,所以一直以来我都很认真的在学这门课(摸着良心讲,我是真的一字一句学习完了攻防教材,一字一句写的攻防每周的博客)这一学期以来,我从最开始简简单单的觉得博客就是一个作业并且会去参考其他同学的博客,到后来我也认真的思考,认真的查资料,一点点的积累了攻防的知识,在最后上池老师的课程的最后两个实验的时候就惊奇的发现自己的动手能力是真的有在提升,虽然一路走得很艰辛,从最开始我把做攻防比作是中彩票,可能有时候机子顺利一下子就做完我彩票中的很快,有时候自己没查对资料那么彩票可能过期了也没中;就是凭着对攻防的执着,渐渐地我也开始独立的做攻防的实验,思考出一些自己的见解;后来我把攻防比作是爬泰山(不要问我为什么,我夜爬泰山,上到十八盘的时候我觉得我都要死掉了,真的太难了)因为渐渐的攻防的实践多了起来,我经常需要熬夜才能写完,就让我想起了我夜爬泰山的痛苦感受;再后来我把攻防比做打地鼠,因为在做攻防的时候你永远想象不到前方会有什么bug有什么坑在等着你,而我就像在打地鼠一样,冒出来一个打进去一个,将攻防比做这三种方式之后我突然觉得我也能成一代“文豪”了!
这都算是我这学期学习攻防的感受吧,总的来说这真的是一门动手能力很强的课程,真的很锻炼动手能力!!!他让我基本了解了整个网络攻防领域,让我基本入门了很多安全类的课程,我在学习其他课程的时候也能够用上攻防的知识,很感谢这学期与王老师的相遇和合作,一学期下来积攒了很多知识。
我依旧记得王老师说过优秀的人不是与生俱来的优秀而是背后有很多常人看不到的坚持和付出,虽然我们看到别的同学很厉害,但是却不知道他们也是熬夜写作业,他们算是我的榜样的力量,后面还要继续向优秀的同学学习,也很感谢王老师一学期的辛苦付出,在结课的时候,老师说,有什么问题可以找他,不管是科研上还是生活工作上,啊啊啊啊啊,老师的光芒又再次闪耀了!!!最后虽然我的研究领域不是网络攻防方面但是我还是会持续关注这个领域,我依旧会持续学习。
参考资料
- AI领域的白盒测试和自动debug
- 论文导读DeepXplore
- LeNet_code
- VGG网络
- 经典CNN
- Fuzzing技术总结
- Fuzzing分析技术
- conda创建新环境
- ResNet解读
- 卷积神经网络