深度学习-物体检测概览
1 物体检测任务
输入:图像
输出:
Bounding Box(回归任务):矩形边界框框出物体位置
物体类别(分类任务):判断矩形框内的物体类别
2 物体检测评测指标
2.1 Top1%和Top5%正确率
参考:https://stats.stackexchange.com/questions/156471/imagenet-what-is-top-1-and-top-5-error-rate
参考:ImageNet 中的Top-1与Top-5 https://blog.csdn.net/v1_vivian/article/details/73251187
2.2 MAP
参考:https://blog.csdn.net/qq_29462849/article/details/81053038
参考:https://medium.com/@jonathan_hui/map-mean-average-precision-for-object-detection-45c121a31173
参考:https://github.com/Cartucho/mAP
参考:目标检测模型中的性能评估——MAP(Mean Average Precision)
https://blog.csdn.net/katherine_hsr/article/details/79266880
2.3 FPS
Frame per second
参考:https://en.wikipedia.org/wiki/Frame_rate
3 物体检测方案
3.1 基于回归的方案
- YOLO模型
整体流程:

具体模型:
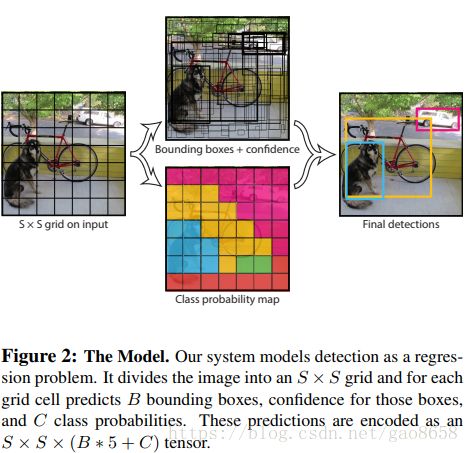
训练的损失函数:

几个额外参数的目的


几个注意点:
(1) 阈值threshold:

(2) 坐标为相对grid cell和image的相对值,每个grid cell会预测B个bounding box

(3) 置信度
Label某些量是在训练时计算出来的。
训练时,置信度的ground-truth。注意IOU是输出训练样本输出的时候
才能计算出来的,而不是提前label出的

测试时,又乘了个类别概率P(C),阈值设置参考(1)

(4) CNN如何起作用,以及和7*7的候选框的关系?
CNN其实预测出的向量,逻辑上会对应到7*7的区域和结果。所以除了最后的一层dense layer之外,之前的一些
卷积和池化的设计调优和按照相应的方式设计即可。
参考:
You Only Look Once: Unified, Real-Time Object Detection
https://github.com/pjreddie/darknet/wiki/YOLO:-Real-Time-Object-Detection
- SSD模型
和YOLO相比,区别在于
- 对不同尺度的featuremap的每个cell进行anchorbox的提取(YOLO相当于是直接对image提取),分别提取出类似Faster R-CNN的类似的anchorbox的size

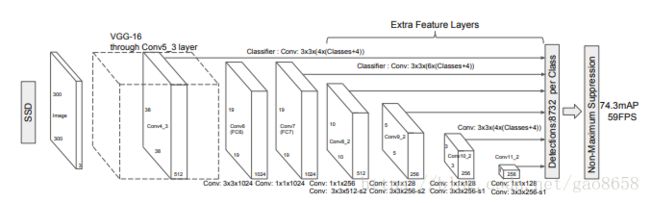
提取多少个box?
- 参考下面的公式:每个cell为k个。
- 对每个featuremap输出:kmn(c+4)个维度的数据

参考:SSD: Single Shot MultiBox Detector
参考:https://blog.csdn.net/helloR123/article/details/75647570/
3.2 基于分类的方案
参考:
Object Recognition for Dummies Part 3: R-CNN and Fast/Faster/Mask R-CNN and YOLO
https://lilianweng.github.io/lil-log/2017/12/31/object-recognition-for-dummies-part-3.html#model-workflow
- R-CNN模型
How R-CNN works can be summarized as follows:
- Pre-train a CNN network on image classification tasks; for example, VGG or ResNet trained on ImageNet dataset. The classification task involves N classes.
NOTE: You can find a pre-trained AlexNet in Caffe Model Zoo. I don’t think you can find it in Tensorflow, but Tensorflow-slim model library provides pre-trained ResNet, VGG, and others. - Propose category-independent regions of interest by selective search (~2k candidates per image). Those regions may contain target objects and they are of different sizes.
- Region candidates are warped to have a fixed size as required by CNN.
- Continue fine-tuning the CNN on warped proposal regions for K + 1 classes; The additional one class refers to the background (no object of interest). In the fine-tuning stage, we should use a much smaller learning rate and the mini-batch oversamples the positive cases because most proposed regions are just background.
- Given every image region, one forward propagation through the CNN generates a feature vector. This feature vector is then consumed by a binary SVM trained for each class independently.
The positive samples are proposed regions with IoU (intersection over union) overlap threshold >= 0.3, and negative samples are irrelevant others. - To reduce the localization errors, a regression model is trained to correct the predicted detection window on bounding box correction offset using CNN features.
- Fast R-CNN模型
RoI Pooling
It is a type of max pooling to convert features in the projected region of the image of any size, h x w, into a small fixed window, H x W. The input region is divided into H x W grids, approximately every subwindow of size h/H x w/W. Then apply max-pooling in each grid.
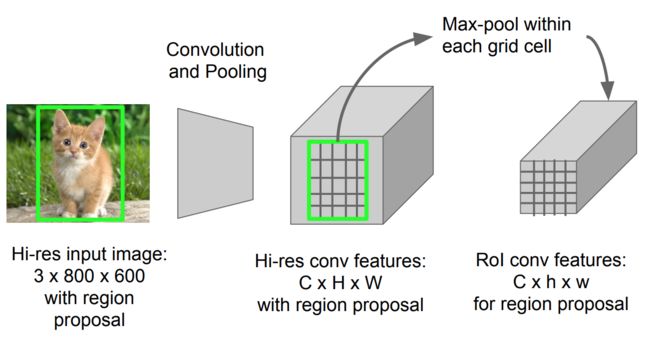
Fig. 3. RoI pooling (Image source: Stanford CS231n slides.)
How Fast R-CNN works is summarized as follows; many steps are same as in R-CNN:
- First, pre-train a convolutional neural network on image classification tasks.
- Propose regions by selective search (~2k candidates per image).
- Alter the pre-trained CNN:
- Replace the last max pooling layer of the pre-trained CNN with a RoI pooling layer. The RoI pooling layer outputs fixed-length feature vectors of region proposals. Sharing the CNN computation makes a lot of sense, as many region proposals of the same images are highly overlapped.
- Replace the last fully connected layer and the last softmax layer (K classes) with a fully connected layer and softmax over K + 1 classes.
- Finally the model branches into two output layers:
- A softmax estimator of K + 1 classes (same as in R-CNN, +1 is the “background” class), outputting a discrete probability distribution per RoI.
- A bounding-box regression model which predicts offsets relative to the original RoI for each of K classes.
- Faster R-CNN模型
An intuitive speedup solution is to integrate the region proposal algorithm into the CNN model. Faster R-CNN (Ren et al., 2016) is doing exactly this: construct a single, unified model composed of RPN (region proposal network) and fast R-CNN with shared convolutional feature layers.
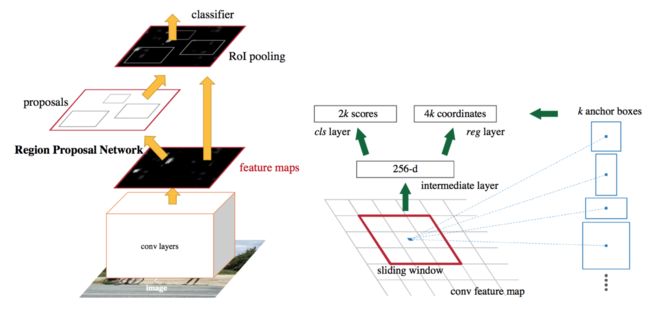
Fig. 5. An illustration of Faster R-CNN model. (Image source: Ren et al., 2016)
- Pre-train a CNN network on image classification tasks.
- Fine-tune the RPN (region proposal network) end-to-end for the region proposal task, which is initialized by the pre-train image classifier. Positive samples have IoU (intersection-over-union) > 0.7, while negative samples have IoU < 0.3.
- Slide a small n x n spatial window over the conv feature map of the entire image.
- At the center of each sliding window, we predict multiple regions of various scales and ratios simultaneously. An anchor is a combination of (sliding window center, scale, ratio). For example, 3 scales + 3 ratios => k=9 anchors at each sliding position.
- Train a Fast R-CNN object detection model using the proposals generated by the current RPN
- Then use the Fast R-CNN network to initialize RPN training. While keeping the shared convolutional layers, only fine-tune the RPN-specific layers. At this stage, RPN and the detection network have shared convolutional layers!
- Finally fine-tune the unique layers of Fast R-CNN
- Step 4-5 can be repeated to train RPN and Fast R-CNN alternatively if needed.
4 开源物体检测框架
4.1 Tensorflow Object Detection Model
Tensorflow内置的物体检测模块
https://github.com/tensorflow/models/tree/master/research/object_detection
4.2 Detectron
Facebook开源的物体检测框架
https://github.com/facebookresearch/Detectron
4.3 Darknet
YOLO作者开源的物体检测框架
https://pjreddie.com/darknet/
5 概念附录:
5.1 IOU

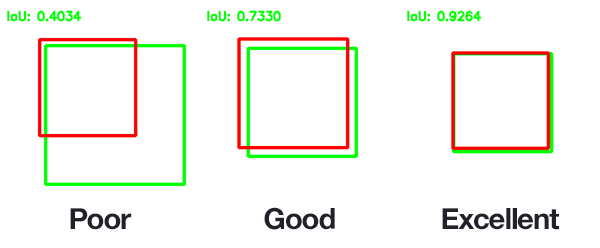
参考:https://www.pyimagesearch.com/2016/11/07/intersection-over-union-iou-for-object-detection/
5.2 Non-max Suppression
非极大值抑制的方法是:先假设有6个矩形框,根据分类器的类别分类概率做排序,假设从小到大属于车辆的概率 分别为A、B、C、D、E、F。
(1)从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
(2)假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
(3)从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
就这样一直重复,找到所有被保留下来的矩形框。
参考:https://www.cnblogs.com/makefile/p/nms.html
5.3 Anchor Boxes
候选区域(anchor)
特征可以看做一个尺度51*39的256通道图像,对于该图像的每一个位置,考虑9个可能的候选窗口:三种面积{1282,2562,5122}×{1282,2562,5122}×三种比例{1:1,1:2,2:1}{1:1,1:2,2:1}。这些候选窗口称为anchors。下图示出51*39个anchor中心,以及9种anchor示例。

参考:https://blog.csdn.net/shenxiaolu1984/article/details/51152614
5.4 hard negative mining
https://www.quora.com/What-is-hard-negative-mining?redirected_qid=21542872
5.5 selective search
参考:
Selective Search
https://lilianweng.github.io/lil-log/2017/10/29/object-recognition-for-dummies-part-1.html#selective-search
6 物体检测中的问题和解决方法总结:
6.1 如何提取候选框
selective search
RPN (Faster R-CNN) + Sliding window
6.2 如何解决提取的候选框输入CNN提取大小不一问题
空间金字塔池化 SPPNet (Fast RCNN)
6.3 如何解决分类方法FPS过低
采用回归的方法,YOLO,SSD
6.4 如何去重重复bounding box
NMS
6.5 如何解决尺度问题
SSD模型结构提取不同size featuremap,(其他就是靠inception可以解决)
6.6 如何解决图像特征提取问题
Base CNN迁移学习:SSD
6.7 如何解决anchor box位置不准确
bounding box regression模型微调(RCNN, FastRCNN)
6.8 分类网络的位置不敏感性和检测网络的位置敏感性
分类网络的位置不敏感性:简单来讲,对于分类任务而言,我希望我的网络有一个很好地分类性能,随着某个目标在图片中不断的移动,我的网络仍然可以准确的将你区分为对应的类别。如上图左边所示,不管你这只鸟在图片中如何移动,我的分类网络都想要准确的将你分类为鸟。即我的网络有很好地区分能力。实验表明,深的全卷积网络能够具备这个特性,如ResNet-101等。
检测网络的位置敏感性:简单来讲,对于检测任务而言,我希望我的网络有一个好的检测性能,可以准确的输出目标所在的位置值。随着某个目标的移动,我的网络希望能够和它一起移动,仍然能够准确的检测到它,即我对目标位置的移动很敏感。我需要计算对应的偏差值,我需要计算我的预测和GT的重合率等。但是,深的全卷积网路不具备这样的一个特征。
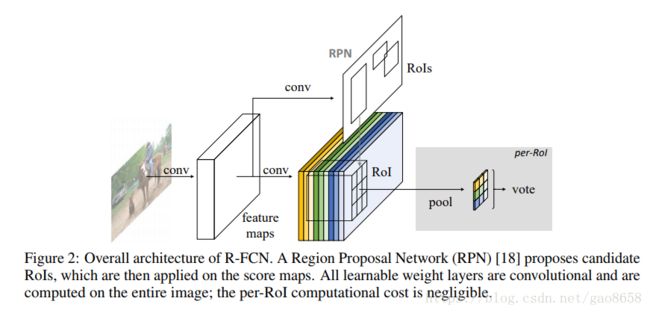
总之,分类网络的位置不敏感性和检测网络的位置敏感性的一个矛盾问题,而我们的目标检测中不仅要分类也要定位,那么如何解决这个问题呢,R-FCN提出了Position-sensitive score maps来解决这个问题;
参考:https://blog.csdn.net/WZZ18191171661/article/details/79481135
参考:R-FCN: Object Detection via Region-based Fully Convolutional Networks
对每个ROI拆分成k*k个cell然后预测每个cell score,综合后为一个score
7 综合评测:
Speed/accuracy trade-offs for modern convolutional object detectors.
友情推荐:ABC技术研习社
为技术人打造的专属A(AI),B(Big Data),C(Cloud)技术公众号和技术交流社群。
