深度学习-增强学习概览
(1) DQN与DDPG
离散状态:
DQN是一个面向离散控制的算法,即输出的动作是离散的。对应到Atari 游戏中,只需要几个离散的键盘或手柄按键进行控制。
然而在实际中,控制问题则是连续的,高维的,比如一个具有6个关节的机械臂,每个关节的角度输出是连续值,假设范围是0°~360°,归一化后为(-1,1)。若把每个关节角取值范围离散化,比如精度到0.01,则一个关节有200个取值,那么6个关节共有20062006个取值,若进一步提升这个精度,取值的数量将成倍增加,而且动作的数量将随着自由度的增加呈指数型增长。所以根本无法用传统的DQN方法解决。
连续状态:
深度确定性策略梯度(Deep Deterministic Policy Gradient, DDPG)算法是Lillicrap 等人利用 DQN 扩展 Q 学习算法的思路对确定性策略梯度(Deterministic Policy Gradient, DPG)方法进行改造,提出的一种基于行动者-评论家(Actor-Critic,AC)框架的算法,该算法可用于解决连续动作空间上的 DRL 问题。
(2) 离散状态空间-DQN
(2.1) Q-learn



Q和R矩阵的初始化如下面代码所示:
Python代码:
import numpy as np
GAMMA = 0.8
Q = np.zeros((6,6))
R=np.asarray([[-1,-1,-1,-1,0,-1],
[-1,-1,-1,0,-1,100],
[-1,-1,-1,0,-1,-1],
[-1,0, 0, -1,0,-1],
[0,-1,-1,0,-1,100],
[-1,0,-1,-1,0,100]])
def getMaxQ(state):
return max(Q[state, :])
def QLearning(state):
curAction = None
for action in range(6):
if(R[state][action] == -1):
Q[state, action]=0
else:
curAction = action
Q[state,action]=R[state][action]+GAMMA * getMaxQ(curAction)
count=0
while count<1000:
for i in range(6):
QLearning(i)
count+=1
print(Q/5)参考:https://blog.csdn.net/qq_41352018/article/details/80274282
DQN
相比Q-Learn算法有几个进化:
1 Q网络输出值近似Q值,通过MSE为损失函数调节
2 store transition,保存结果,experience relay
参考:https://storage.googleapis.com/deepmind-media/dqn/DQNNaturePaper.pdf
(3) 连续状态-DDPG
相比DQN就是状态空间太大,每次向前推进,选action时,希望通过采样或者通过函数映射每次只取其中一部分作为action。
(3.1) PG
通过采样获取action

参考:https://blog.csdn.net/kenneth_yu/article/details/78478356
(3.2) DPG
采样产生的问题,计算量太大,DPG决定通过函数来近似采样的结果:

DPG每次选action通过一个函数输出需要的action

最终将DPG算法融合进actor-critic框架,结合Q-learning或者Gradient Q-learning这些传统的Q函数学习方法,经过训练得到一个确定性的最优行为策略函数。
(3.3) DDPG
相比DPG,直接以深度学习近似U函数和Q函数。动作函数同时融入EE。


对Q网络和U网络分别通过不同的损失函数和梯度下降公式优化:
Q网络通过和target Q值进行MSE进行优化:
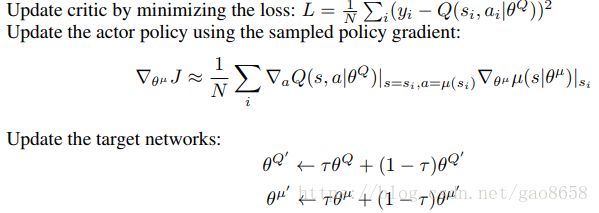
U网络:
相当于极大似然估计,希望Q值最大化期望。然后对u中的参数theta求导。J对theta求导经过链式法则转化为
Q对U求导,U对theta求导。

补充理解:
U是确定过程,N是噪音,通过随机过程模拟采样出来。

这个图容易混淆,随机过程应只发生在noise中,而且与梯度下降过程分离,不影响性能。

参考:http://wulc.me/2018/05/11/%E5%BC%BA%E5%8C%96%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0(3)-%20%E4%BB%8E%20Policy%20Gradient%20%E5%88%B0%20A3C/
参考:https://blog.csdn.net/kenneth_yu/article/details/78478356
参考:CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING
(4) 将问题转换为通过RL解决
分类问题,将类别映射为DQN的状态,类别被预测的概率为Q值,类别的target label映射为Reward值。问题同时有特点,能够源源不断对环境进行交互获取新的训练数据
回归问题,将预测值转换为DDPG预测的连续状态,回归值被预测为Q值,回归值的target label映射为Reward值。问题同时有特点,能够源源不断对环境进行交互获取新的训练数据
参考:《强化学习在阿里的技术演进与业务创新》
友情推荐:ABC技术研习社
为技术人打造的专属A(AI),B(Big Data),C(Cloud)技术公众号和技术交流社群。
