【Elasticsearch】数据类型及映射相关
【前言】
关于Elasticsearch记了几篇博客,关于最最基础的倒是忘了写了,万丈高楼平地起,没有基础怎么行?是不是莫名地押韵,下面进入正文:
【正文】
mysql建表的时候需要创建字段及其类型,Elasticsearch创建索引的时候也是这样
我们创建索引时,可以预先定义字段的类型以及相关属性(是否分词,使用什么样的分词器是否存储),相当于定义数据库字段的属性,这是通过Mapping来完成的;Mapping(类似于静态语言中的数据类型)是我们自己定义的字段的数据类型,可以将输入的数据转变成可搜索的索引项,同时告诉Elasticsearch如何索引数据以及是否可以被搜索。
————————————————————————————————
如果有新字段出现,Elasticsearch会根据JSON源数据的基础类型猜测你想要的字段映射Mapping(这在MySQL、SQL Server是不被容许的)。
动态映射:
数据写入,已经存在的索引是不可以更改它的映射的,只有新字段出现时,Elasticsearch才会自动进行处理
如何配置:
- 通过dynamic属性控制:true 动态添加 false 忽略新字段 strict 抛异常
不过Elasticsearch会把Object等一些“复杂”的类型视为string,这算个优化点,所以现在好好学习、万一哪天这个点被我优化了呐(^_^梦想还是要有的)废不多话,接着往下看吧
分词
分词:拆分成一个一个的词,这个和solr差不多,个人感觉更加的灵活,各有侧重吧这样说更一些
创建索引的时候通过Mapping可以配置
- analyzed:默认选项,以标准的全文索引方式,分析、拆分字符串,完成索引。
- not_analyzed:精确索引,不对字符串做拆分,作为一个整体,直接索引字段数据的精确内容。
- no:不索引该字段。
"yiwankaTags" : {
"type" : "string",
"index" : "not_analyzed"
} 下面具体抄一些这些数字符串:string
一、核心数据类型:
1、字符型:text(默认分词、text.keyword不分词) keyword(不分词)
2、数值:long:64位存储 , integer:32位存储 , short:16位存储 , byte:8位存储 , double:64位双精度存储 , float:32位单精度存储 、half_float:半精度的16位IEEE 754浮点数, scaled_float
3、日期:date,可以指定格式
“properties”: {
“date”: {
“type”: “date”,
“format”: “yyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis”
}
}
4、Boolean:boolean
false= “false”, “off”, “no”, “0”, “” , 0, 0.0
5、Binary:二进制类型接受Base64编码的二进制值字符串。该字段不是默认存储的,不能搜索
删除:
删除数据不会删除映射:DELETE /index/type
curl -XDELETE ‘http://localhost:9200/sharks/syslog’删除索引映射也没了:Delete /index
curl -XDELETE ‘http://localhost:9200/sharks’删除映射:DELETE index/_mapping
curl -XDELETE ‘http://localhost:9200/sharks/_mapping’
删除多个映射
DELETE /libraryry/_mapping/books,bank_acount #删除多个映射
差点点温柔—修改已经存在的mapping映射:
1.如果要推到现有的映射,你得重新建立一个索引.然后重新定义映射
2.然后把之前索引里的数据导入到新的索引里
——-具体方法——
1.给现有的索引定义一个别名,并且把现有的索引指向这个别名,运行步骤2
2.运行: PUT /现有索引/_alias/别名A
3.新创建一个索引,定义好最新的映射
4.将别名指向新的索引.并且取消之前索引的执行,运行步骤5
5.运行: POST /_aliases
{
"actions":[
{"remove" : { "index": "现有索引名". "alias":"别名A" }}.
{"add" : { "index": "新建索引名", "alias":"别名A" }}
]
}
注意:通过这几个步骤就实现了索引的平滑过渡,并且是零停机
注意:
Elasticsearch实际索引是以index为基础,同一index下不同type的字段mapping不一致的话,数据写入生成各自的mapping(自动映射),索引结果以第一个mapping来生成
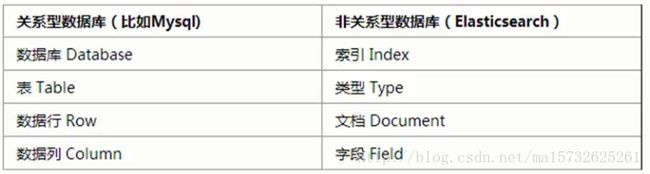
名词解释:
1、index:索引、几份相似特征的文档的集合
客户索引:多个客户信息的集合
产品索引
客户、产品不宜混合在一起,不利搜索
2、type:类型,虚拟的逻辑分组,type:Index == 多:1
根据我的经验,确实Elastic 6.x 版只允许每个 Index 包含一个 Type;
但是关于有人说的:7.x 版将会彻底移除 Type,不太确定,可能吧
3、document:文档, 可被索引的基础信息单元,json
4、field:列,Elasticsearch最小单位,数据的一列
5、node:我的理解:一个安装了一个elasticsearch就安装了一个node(不准确)
6、cluster:集群,多个node组成,前面安装的时候多少说了一下配置
7、shards:分片,索引分成若干份(5)每一部分是一个分片,索引创建完无法修改,把索引中大数据分散和备份起来
下面这张图为了帮助理解,其实是不准确的:
miqi1227:Elasticsearch学习笔记(四)Mapping映射search学习笔记(四)Mapping映射ht** https://blog.csdn.net/u010994304/article/details/50454025
官网的中文权威指南竟然蹦出来了,赶紧记下了分享一下 [Elasticsea:指南]https://www.elastic.co/guide/cn/elandex.earch/guide/current/index.html