小米Kylin平滑迁移HBase实践

根据美团等其他公司在Kylin社区的公开分享资料,跨HBase集群升级方案需要在新集群重新构建历史的Cube,或者有一段时间的服务停止。
小米在Kylin生产环境的跨HBase集群迁移中实现了无中断的平滑迁移,对业务的影响减到最低。
往期文章回顾:Talos网卡负载优化:基于个性化一致性哈希的负载均衡
背景
小米Kylin生产环境部署的是基于社区2.5.2修改的内部版本,所依赖HBase集群是一个公共集群,小米内部很多离线计算服务共享使用该HBase集群。由于Kylin已经产生超过6000张HBase表,给HBase的metadata管理造成了不小的压力,HBase metadata节点异常恢复的速度也受到极大的影响。随着业务的增长,Kylin HBase表继续快速增长,HBase集群的运维压力也越来越大。
为了应对快速增长的业务需求,我们决定将Kylin使用的HBase集群独立运维。同时,公共集群的HBase是基于社区0.98.11的小米内部版本,版本较旧。在集群独立过程中,HBase团队推荐使用最新基于社区2.2.0的小米内部版本 ,升级后HBase对超大metadata的管理也更友好。
目标与挑战
小米Kylin生产环境上运行着超过50个项目、300多个cube,服务于很多在线的BI或报表系统。本次升级希望尽量减小对业务的影响:
迁移数据和切换集群期间,查询服务不中断;
项目、数据模型和cube的新增、更改、发起构建、发起合并等操作不受影响;
数据构建任务可延后调度,但不能超过天级别;
Kylin存储在HBase中的数据主要有两类:Kylin metadata(元数据)、Cube预计算数据。
元数据中存储着所有的用户、项目和数据模型的信息;数据模型对应的结果数据表;数据任务的执行参数、状态和日志;查询使用的词典等重要信息。由于我们接入了很多自动化BI系统,这部分信息随时在变化。
Cube预计算数据是查询使用的结果数据,每一个segment对应着一张数据表,预计算的数据表生成之后不会变化。我们虽然可以通过HBase snapshot复制后在新集群restore的方式将数据复制到新的集群,但是由于生产环境的Kylin中的数据表比较多,且以每天400张的速度不断生成(注:因为有合并和过期删除策略,每天数据表的增加数量要少于400)。新的数据表生成后会在metadata中标记为可查询,若此时数据表的同步未完成,就会导致查询失败。
我们面对挑战是如何保障数据迁移的过程中的服务可用性:
Kylin metadata不断变化,Cube预计算数据存量巨大且在持续增加;
metadata可以做到秒级别同步,Cube预计算数据只能做到天级别(存量)和小时级别(增量)的同步;
metadata新旧集群保证一致,Cube预计算数据迁移过程中保障可用;
如下图所示:
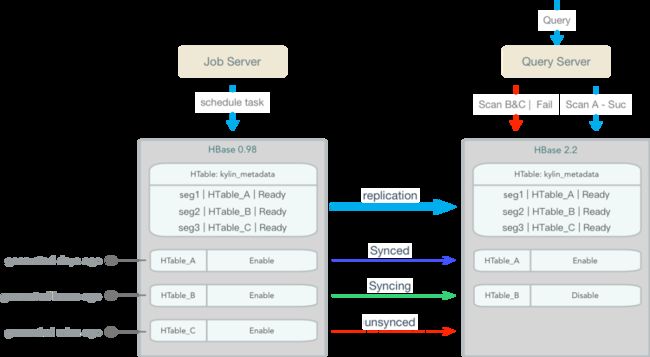
图1-通常方案的问题
迁移方案
因为我们维护了基于Kylin-2.5.2的内部版本,希望通过修改代码实现平滑迁移,其关键点是:
通过HBase replication保证新旧集群Kylin metadata的数据同步
Kylin的meta信息存储在HBase的kylin_metadata表中,两个集群的此表保持同步更新。
Kylin支持连接多个HBase集群
查询时如果在首选HBase中找不到需要的HTable,则回退到备选HBase集群。(已提交社区:KYLIN-4175)
任务调度支持安全模式
安全模式下,用户可继续提交构建任务,且已在调度中的任务可以继续执行,但新提交的任务暂缓调度。(已提交社区:KYLIN-4178)
迁移示意图如下:

图2-支持secondary HBase方案
除了上述关键点,还需要注意一些细节问题。
1. 超大metadata的数据迁移
超过阈值(默认为10MB)的metadata存储在HBase依赖的HDFS上,需要手动迁移这部分数据。我们通过Hadoop distcp来迁移此部分数据。
2. coprocessor的更新
Kylin使用了HBase的coprocessor机制,在执行查询的时候扫描HBase的数据。起初我们认为可以使用兼容HBase 0.98和2.2的coprocessor,实际测试中发现需要更新为支持HBase2.2的coprocessor。Kylin提供了工具来进行批量的更新。
构建基于HBase 2.2的Kylin,需要基于社区的2.5.x-hadoop3.1或2.6.x-hadoop3.1分支。我们选择从Hadoop3.1的分支上移植相关特性。相关的JIRA有:KYLIN-2565、KYLIN-3518
>>>>
迁移步骤
具体迁移步骤如下:
HBase团队搭建好基于HBase 2.2的独立HBase集群
HBase团队添加新老集群kylin_metadata表的异步replication;
HBase团队通过snapshot + restore同步HBase其他表,并更新coprocessor;
在测试节点上回放生产环境查询请求,验证新集群HBase数据表可正常提供查询;
开启JobServer的安全模式,禁用新的任务调度;
滚动升级QueryServer,切换至兼容新旧HBase;
等待安全模式下所有任务运行完成,切换JobServer至新HBase并关闭安全模式;
等待表全部迁移完成,使用KylinHealthCheck工具检查HBase表,确认所有在用cube segment对应的HBase表存在;
检查确认后,从Kylin去除旧HBase集群配置;
旧HBase集群数据保留一段时间,最后清理删除。
问题&解决
在演练和执行的过程中,我们遇到了如下的一些问题:
>>>>
Kylin metadata的一致性验证
Metadata作为最重要的HBase表,影响着Kylin的主要功能。虽然有HBase replication来保证数据同步,也最好双重确认来保障服务可用性。
我们在Kylin中开发了一个脚本来批量对比两个meta表,通过扫描meta表所有的键值和时间戳来发现差异。在初期确实发现了差异,也依此来修正了replication的配置。在HBase团队的协助下,该表做到了实时的同步。
>>>>
新HBase数据表的可用性验证
为了验证新集群的数据可用性,我们启动了一个测试的Kylin实例用以模拟兼容多个HBase集群的查询。测试实例不直接对用户服务,而是通过回放SQL query来进行可用性测试。回放测试自动验证查询是否正常返回。
这种测试方式弥补了回归测试用例覆盖范围的不足,通过测试我们确实发现了隐藏的问题并进行了修复。在生产环境的切换中,未发生新的问题。
>>>>
HBase2 protobuf变更带来的影响
测试中发现,若HBase返回数据量较大时会查询报错,提示消息的长度超过限制:
InvalidProtocolBufferException:Protocol message was too large. May be malicious.
在查询时,HBase和Kylin之间的数据发送通过protobuf序列化。HBase 2修改了返回数据的方式,从一次性返回变成了流式的返回,从而触发了protobuf的长度检查逻辑。这个长度在protobuf 3之前的版本被限制为64M,支持通过setSizeLimit()方法来修改。
实际上,大多数Hadoop项目都会使用shaded protobuf并修改这个限制。由于Kylin项目中未使用自己打包的protobuf,因此这里需要通过接口修改长度限制。
相关讨论见:KYLIN-3973。
>>>>
HBase写大文件的异常
当Cube的预计算结果数据量比较大,单HBase region的文件大小超过配置的阈值时,向HBase 2.2写文件会造成海量的小文件。这一步发生在将计算的结果转换为HFile时,此步骤的任务执行时间也比较长。这是由HBase 2.2的BUG导致,HBase的修复方案已合入最新分支。可以移植该patch以解决问题,也修改配置hbase.hregion.max.filesize来解决。
相关讨论见:HBASE-22887、KYLIN-4292、KYLIN-4293。
>>>>
部分数据构建任务失败
迁移过程中有两种数据构建任务的失败:包更新导致的失败、segment合并的失败。
由于Kylin的任务机制,在提交任务的时候就已经指定了使用的jar包的绝对路径。如果Kylin的依赖升级后,jar包版本号发生了变化,就会导致执行异常。社区版本尚未修复,可以通过保留原来版本的文件来避免该问题。相关讨论见:KYLIN-4268。
另外,多集群的HBase配置仅支持了查询引擎,在合并最新生成的HBase表时会出现异常。我们认为segment合并可以接受一定时间的延迟,在HBase表同步完成后再触发相关合并操作即可。
总结与展望
本次Kylin的HBase跨集群迁移和版本升级的挑战点是如何保证对用户的影响最小。迁移的重点是设计一个高效迁移方案、保证迁移过程的数据一致性和正确性、保证测试方案的完整覆盖,同时需要设计执行过程中的异常情况的判定和处理机制。
最后的Kylin滚动升级过程耗时2小时,也就意味着用户作业的调度延后为2小时。基于前期的大量工作,最终实现了对业务的影响最小。我们在维护的内部版本的基础上,通过技术修改优雅解决问题,相关成果也反馈给社区。
>>>>
后续改进
目前使用HBase作为Kylin的预计算结果存储有着诸多问题。除了本文提到的海量表,还包括不支持第二索引、查询引擎无法分布式、扫描表的数据量和时间存在限制等问题,这些都限制了Kylin的能力。社区正在实现Kylin on Parquet的方案,数据存储使用Parquet,查询引擎使用SparkSQL,此方案能够极大的提升Kylin的能力。我们期待该方案的落地,也会积极的参与相关讨论、开发和测试。
致谢
感谢HBase团队同学在迁移期间的给力支持!
关于我们
小米云平台计算平台团队,负责为小米集团各业务线提供高品质的弹性调度和计算服务。包括离线平台(Spark,Hadoop Yarn,Kylin,Doris等),流式平台(Kafka,Flink及自研Talos等),弹性平台(Docker,Kubernetes等)。武汉团队主要负责Kylin、Druid等OLAP引擎开发。
![]()
we want you
北京武汉均有职位,欢迎优秀的你加入~
联系方式:[email protected]
参考资料
[1] Apache Kylin跨机房迁移实战
https://blog.bcmeng.com/post/kylin-migrate.html
[2] KYLIN-4175: Support secondary hbase storage config for hbase cluster migration
https://issues.apache.org/jira/browse/KYLIN-4175
[3] KYLIN-4178: Job scheduler support safe mode
https://issues.apache.org/jira/browse/KYLIN-4178
[4] KYLIN-3973: InvalidProtocolBufferException: Protocol message was too large. May be malicious.
https://issues.apache.org/jira/browse/KYLIN-3973
[5] KYLIN-3997: Add a health check job of Kylin
https://issues.apache.org/jira/browse/KYLIN-3997
[6] KYLIN-4268: build job failed caused by hadoop utils update
https://issues.apache.org/jira/browse/KYLIN-4268
[7] HBASE-22887: HFileOutputFormat2 split a lot of HFile by roll once per rowkey
https://issues.apache.org/jira/browse/HBASE-22887
[8] KYLIN-4293: Backport HBASE-22887 to Kylin HFileOutputFormat3
https://issues.apache.org/jira/browse/KYLIN-4293
[9] [DISCUSS] Columnar storage engine for Apache Kylin:
http://apache-kylin.74782.x6.nabble.com/DISCUSS-Columnar-storage-engine-for-Apache-Kylin-td11821.html

我就知道你“在看”
