qiuzitao机器学习(八):生动形象的理解模型集成(model ensemble)
由于最近做项目接触到集成模型(Ensemble),我查阅了一些资料终于对于集成模型有了自己生动形象的理解,“取其精华去其糟粕”。
一、什么是模型集成?
“团结就是力量”。这句话很好地表达了机器学习领域中强大「集成方法」的基本思想。总的来说,许多机器学习竞赛(包括 Kaggle)中最优秀的解决方案所采用的集成方法都建立在一个这样的假设上:将多个模型组合在一起通常可以产生更强大的模型。
集成学习是一种机器学习范式。在集成学习中,我们会训练多个模型(通常称为「弱学习器」)解决相同的问题,并将它们结合起来以获得更好的结果。最重要的假设是:当弱模型被正确组合时,我们可以得到准确率更高和鲁棒性更强的模型。
在集成学习理论中,我们将弱学习器(或基础模型)称为「模型」,这些模型可用作设计更复杂模型的构件。在大多数情况下,这些基本模型本身的性能并不是非常好,这要么是因为它们具有较高的偏置(例如,低自由度模型),要么是因为他们的方差太大导致鲁棒性不强(例如,高自由度模型)。
集成方法的思想是通过将这些弱学习器的偏置和/或方差结合起来,从而创建一个「强学习器」(或「集成模型」),从而获得更好的性能。
多模型融合存在着多种实现方法:Bagging、、Boosting、Stacking。
二、Bagging
①从原始样本集中抽取训练集。每轮从原始训练样本集中使用Bootstraping的方法得到n组训练样本集。
②每次使用一个训练样本集得到一个模型,n个训练集共得到n个模型。
③对分类问题:将上步得到的n个模型采用投票的方式得到分类结果;对回归问题,计算上述模型的均值作为最后的结果。(所有模型的重要性相同)
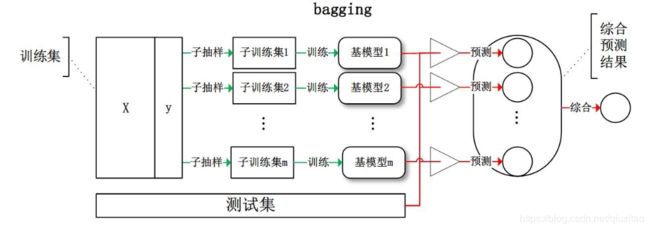
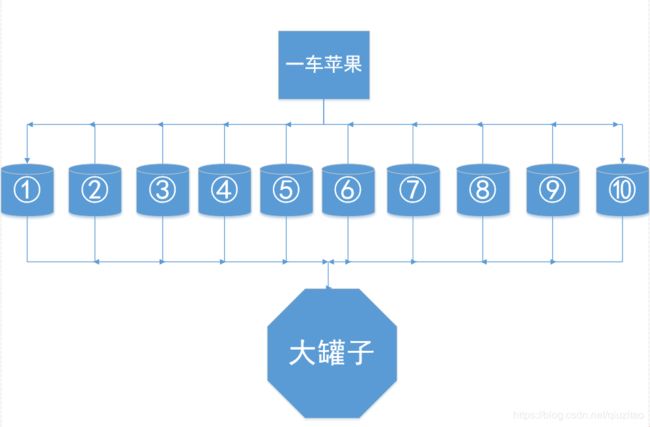
Bagging中文可以翻译为:把…装入袋中。接下来用个比喻分别对应上面的步骤,一车苹果 = 全部训练集,袋子 = 分类器(LR,决策树,xgboost等),过滤器 = 投票或取平均,Bootstraping的方法 = 老板有放回的装苹果。
①②市场上有个人拉了一车苹果在卖,老板说一袋50块钱随便挑,袋子是老板给的,都一样大。现在财大气粗的你要去全部买了,你叫老板帮你装成一袋一袋的(一车共10袋),然后你在旁边盯着不让他挑坏的给你,所以老板看到坏的就放回车上,奸诈的老板趁你不注意还是把放回的苹果均匀的分布在每一袋中,一车不剩的装给你。
③你回到家要把10袋苹果榨成汁然后放到一个大罐子里,因为水果机不够大,你每次只能榨一袋苹果,每一袋榨汁后你都用个过滤器过滤掉渣,然后倒入大罐子里。
三、Boosting
Boosting是一种将弱分类器集成的方法,这里介绍adaboost算法,是boosting系列算法中的一种,跟bagging不同的是,它给不同的分类器赋予不同的权重,它的基分类器可以是同类分类器也可以是不同的分类器。
①取全部训练集当做样本,然后扔到n个模型训练。(基模型1 = n个模型)
②转化样本,一开始给每一个样本赋予权重D,初始的样本权重是相等的。
训练后计算分类器的错误率,根据错误率ε对样本的权重进行调整(分类正确的样本权重会降低,分类错误的样本权重会上升),再进行二次、三次…训练,最终给不同的分类器分配不同的权重alpha(分类器的错误率低则权重高)
③按照某种确定性的策略将它们组合起来,对所有基模型预测的结果进行线性综合产生最终的预测结果。
这里要注意的是调整样本权重是为了训练模型,每次更新完权重就进行下一次的迭代训练。
分类器权重:alpha=0.5*ln(1-ε/max(ε,1e-16))
更新样本权重: 如果某个样本被正确分类,那么权重更新为:
D(m+1,i)=D(m,i)*exp(-alpha)/sum(D)
如果某个样本被错误分类,那么权重更新为:
D(m+1,i)=D(m,i)*exp(alpha)/sum(D)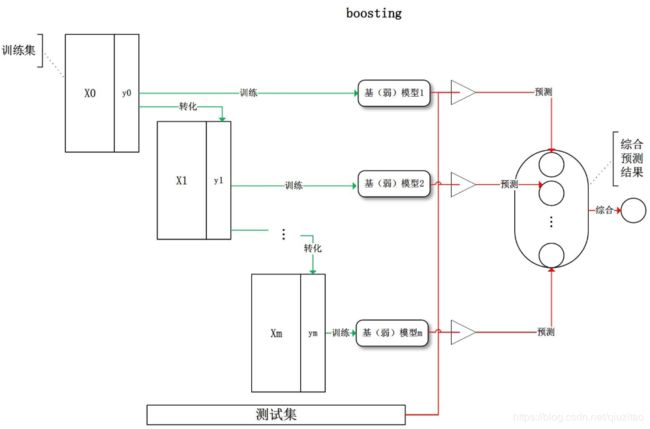
AdaBoosting方式每次使用的是全部的样本,每轮训练改变样本的权重。下一轮训练的目标是找到一个函数 f 来拟合上一轮的残差。当残差足够小或者达到设置的最大迭代次数则停止。Boosting会减小在上一轮训练正确的样本的权重,增大错误样本的权重。(对的残差小,错的残差大)
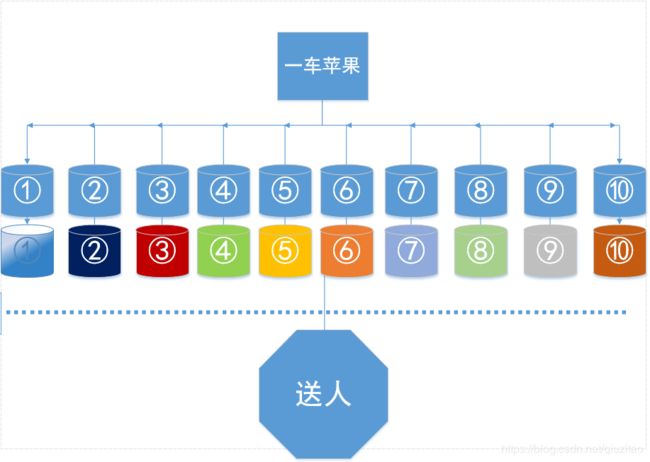
梯度提升的Boosting方式是使用代价函数对上一轮训练出的模型函数 f 的偏导来拟合残差。接下来用个比喻分别对应上面的步骤,一车苹果 = 全部训练集,各个袋子 = 各个基模型(就是n个模型训练不同权重的训练集组成的)
①市场上有个人拉了一车苹果在卖,老板说一袋50块钱随便挑,袋子是老板给的,都一样大。现在财大气粗的你要去全部买了,你叫老板帮你装成一袋一袋的(一车共10袋)。
②老板装完10袋后你突然想到要送人,就叫老板每一袋要挑好看的大的苹果放在袋子上层,老板听了后马上重新装好10袋。不过你还是觉得不满意,继续刁难老板,重新装了n次直到你满意为止。
③你回到家要把10袋苹果对比之后挑出好看的满意的去送人。
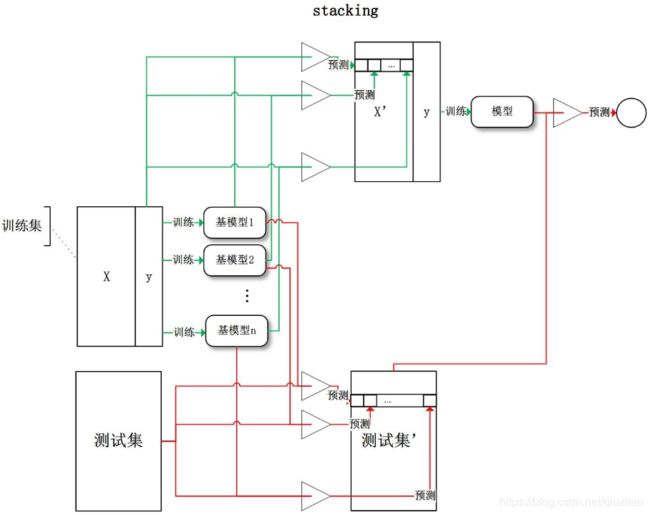
四、Stacking
Stacking是一种分层模型集成框架。下面以两层为例。
①第一层由多个基学习器(多种模型如LR,决策树)组成,其输入为原始训练集。
②第二层的模型则是以第一层基学习器的输出作为训练集进行再训练,从而得到完整的stacking模型。
③如果是多层次的话,以此类推。
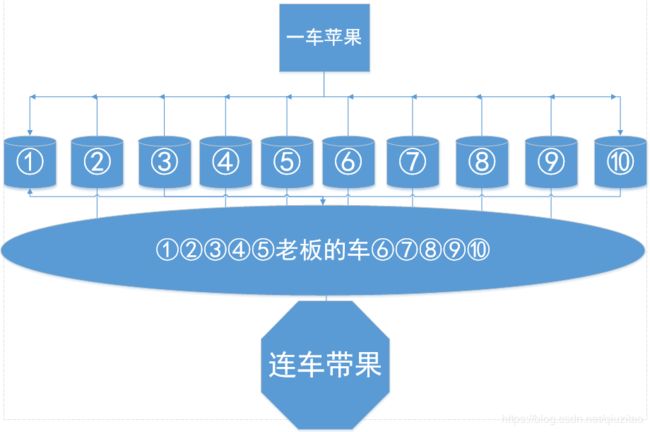
接下来用个比喻分别对应上面的步骤,一车苹果 = 全部训练集,各个袋子 = 各种模型,老板的车 = 第二层的最终分类器
①市场上有个人拉了一车苹果在卖,老板说一袋50块钱随便挑,袋子是老板给的,都一样大。现在财大气粗的你要去全部买了,你叫老板帮你装成一袋一袋的(一车共10袋)。
②老板装完10袋后你突然想到你是走路来市场的,带不了那么多苹果回家,财大气粗的你就把老板的车也买了,把装好苹果的10个袋子放车上一起运回家了。
③如果你心情不好可以打包装多点外套,把老板累死。
五、区别
①样本选择上:
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
Stacking:第一层用原来的训练样本,第二层用前面层的输出作为训练集。
②样例权重:
Bagging:使用均匀取样,每个样例的权重相等。
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
Stacking:各层的权重可以手动调整。
③预测函数:
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
Stacking:因为样本的类型不同,各层的权重有不同。
④并行计算:
Bagging:各个预测函数可以并行生成
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
Stacking:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
参考:1、https://baijiahao.baidu.com/s?id=1633580172255481867&wfr=spider&for=pc
2、https://www.cnblogs.com/mantch/p/10203143.html
3、https://www.biaodianfu.com/boosting.html
4、https://blog.csdn.net/jin__9981/article/details/86097341