视觉slam14讲——第9讲 设计前端
本系列文章是记录学习高翔所著《视觉slam14讲》的内容总结,文中的主要文字和代码、图片都是引用自课本和高翔博士的博客。代码运行效果是在自己电脑上实际运行得出。手动记录主要是为了深入理解
涉及到的主要内容如下
- 设计一个视觉里程计前端
- 理解slam软件框架的搭建
- 理解前端设计容易出现的问题及解决方式
- 搭建VO框架
- 1 确定程序框架
- 2 确定基本数据结构
- 3 Camera类
- 4 Frame类
- 5 MapPoint类
- 6 Map类
- 7 Config类
- 基本的VO特征提取和匹配
- 1 两两帧的视觉里程计
- 改进优化PnP的结果
- 改进 局部地图
- 小结
1 搭建VO框架
1.1 确定程序框架

- bin用来存放可执行二进制文件
- include/myslam存放SLAM模块文件
- src存放源代码文件
- lib放置编译好的库文件
- config放置配置文件
- cmake_modules第三方库cmake文件
1.2 确定基本数据结构
讨论以下几个重要的基本概念
- 1 帧Frame
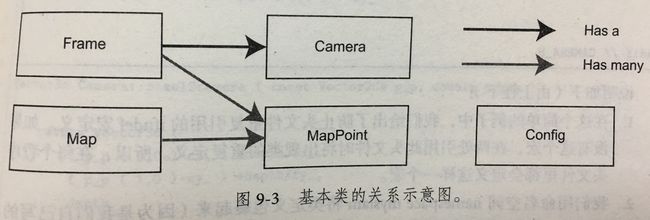
帧是采集图像的基本单位,主要包含一个图像,还有特征点,位姿,内参等信息。在SLAM中我们重点讨论关键帧的选取Key-Frame - 2 路标
路标点即是图像中的特征点。通常路标存放在地图中 - 3 其他工具
(1)配置文件
方便调试参数
(2)坐标变换
定义一些类进行这些操作
设计的基本类的关系示意图
1.3 Camera类
Camera类存储相机的内参和外参,并完成相机坐标系,像素坐标系和世界坐标系之间的坐标转换。
类的定义如下
#ifndef CAMERA_H
#define CAMERA_H
#include "myslam/common_include.h"
namespace myslam
{
// Pinhole RGBD camera model
class Camera
{
public:
typedef std::shared_ptr Ptr;
float fx_, fy_, cx_, cy_, depth_scale_; // Camera intrinsics
Camera();
Camera ( float fx, float fy, float cx, float cy, float depth_scale=0 ) :
fx_ ( fx ), fy_ ( fy ), cx_ ( cx ), cy_ ( cy ), depth_scale_ ( depth_scale )
{}
// coordinate transform: world, camera, pixel
Vector3d world2camera( const Vector3d& p_w, const SE3& T_c_w );
Vector3d camera2world( const Vector3d& p_c, const SE3& T_c_w );
Vector2d camera2pixel( const Vector3d& p_c );
Vector3d pixel2camera( const Vector2d& p_p, double depth=1 );
Vector3d pixel2world ( const Vector2d& p_p, const SE3& T_c_w, double depth=1 );
Vector2d world2pixel ( const Vector3d& p_w, const SE3& T_c_w );
};
}
#endif // CAMERA_H 类的实现
#include "myslam/camera.h"
namespace myslam
{
Camera::Camera()
{
}
Vector3d Camera::world2camera ( const Vector3d& p_w, const SE3& T_c_w )
{
return T_c_w*p_w;
}
Vector3d Camera::camera2world ( const Vector3d& p_c, const SE3& T_c_w )
{
return T_c_w.inverse() *p_c;
}
Vector2d Camera::camera2pixel ( const Vector3d& p_c )
{
return Vector2d (
fx_ * p_c ( 0,0 ) / p_c ( 2,0 ) + cx_,
fy_ * p_c ( 1,0 ) / p_c ( 2,0 ) + cy_
);
}
Vector3d Camera::pixel2camera ( const Vector2d& p_p, double depth )
{
return Vector3d (
( p_p ( 0,0 )-cx_ ) *depth/fx_,
( p_p ( 1,0 )-cy_ ) *depth/fy_,
depth
);
}
Vector2d Camera::world2pixel ( const Vector3d& p_w, const SE3& T_c_w )
{
return camera2pixel ( world2camera ( p_w, T_c_w ) );
}
Vector3d Camera::pixel2world ( const Vector2d& p_p, const SE3& T_c_w, double depth )
{
return camera2world ( pixel2camera ( p_p, depth ), T_c_w );
}
}其实上面的每一个函数的实现都是按照之前第5讲相机和图像中的坐标变换公式写成的。
1.4 Frame类
Frame类是基本的数据单元,定义了ID,时间戳,位姿,相机,图像这几个量。
几个重要的方法是创建Frame,寻找给定点对应的深度,获取相机广信,判断某个点是否在视野之内。
简单的接口如下。
#ifndef FRAME_H
#define FRAME_H
#include "myslam/common_include.h"
#include "myslam/camera.h"
namespace myslam
{
// forward declare
class MapPoint;
class Frame
{
public:
typedef std::shared_ptr Ptr;
unsigned long id_; // id of this frame
double time_stamp_; // when it is recorded
SE3 T_c_w_; // transform from world to camera
Camera::Ptr camera_; // Pinhole RGBD Camera model
Mat color_, depth_; // color and depth image
public: // data members
Frame();
Frame( long id, double time_stamp=0, SE3 T_c_w=SE3(), Camera::Ptr camera=nullptr, Mat color=Mat(), Mat depth=Mat() );
~Frame();
// factory function
static Frame::Ptr createFrame();
// find the depth in depth map
double findDepth( const cv::KeyPoint& kp );
// Get Camera Center
Vector3d getCamCenter() const;
// check if a point is in this frame
bool isInFrame( const Vector3d& pt_world );
};
}
#endif // FRAME_H
1.5 MapPoint类
MapPoint表示路标点,我们会估计他的世界坐标,并且拿当前帧提取到的特征点与地图中的路标点匹配来估计相机的运动,因此还需要存储对应的描述子。
此外还记录一个点被观测到的次数和被匹配的次数,作为评价好坏程度的指标。
#ifndef MAPPOINT_H
#define MAPPOINT_H
namespace myslam
{
class Frame;
class MapPoint
{
public:
typedef shared_ptr Ptr;
unsigned long id_; // ID
Vector3d pos_; // Position in world
Vector3d norm_; // Normal of viewing direction
Mat descriptor_; // Descriptor for matching
int observed_times_; // being observed by feature matching algo.
int correct_times_; // being an inliner in pose estimation
MapPoint();
MapPoint( long id, Vector3d position, Vector3d norm );
// factory function
static MapPoint::Ptr createMapPoint();
};
}
#endif // MAPPOINT_H 1.6 Map类
Map类管理这所有的路标点,并负责添加新路标,负责删除不好的路标。VO的匹配过程只需要和Map沟通即可。
#ifndef MAP_H
#define MAP_H
#include "myslam/common_include.h"
#include "myslam/frame.h"
#include "myslam/mappoint.h"
namespace myslam
{
class Map
{
public:
typedef shared_ptr1.7 Config类
Config类负责参数文件的读取,并在程序的任意地方都可以随时提供参数的值。把COnfig类写成单件模式,它只有一个全局对象。
#ifndef CONFIG_H
#define CONFIG_H
#include "myslam/common_include.h"
namespace myslam
{
class Config
{
private:
static std::shared_ptr config_;
cv::FileStorage file_;
Config () {} // private constructor makes a singleton
public:
~Config(); // close the file when deconstructing
// set a new config file
static void setParameterFile( const std::string& filename );
// access the parameter values
template< typename T >
static T get( const std::string& key )
{
return T( Config::config_->file_[key] );
}
};
} 2 基本的VO:特征提取和匹配
事实上仅凭两帧的估计是不够的,我们会把特征点缓存为一个小地图,计算当前帧与地图之间的位置关系。
2.1 两两帧的视觉里程计
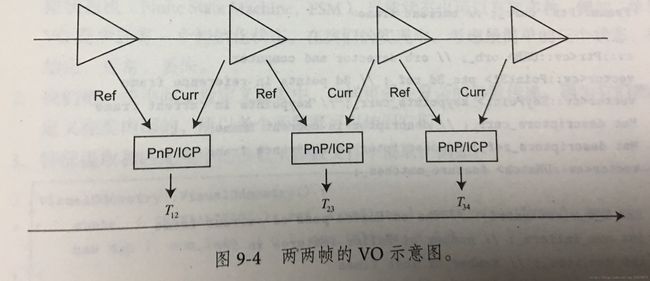
计算流程如下
1 对新的当前帧,提取关键点和描述子
2 如果系统没有初始化,以该帧为参考帧,根据深度图计算关键点的3D位置,返回第1步
3 估计参考帧与当前帧的运动
4 判断上述估计是否成功
5 如果成功,把当前帧当做新的参考帧,返回第1步
6 如果失败,记录连续丢失帧数。当丢失帧数达到一定时,设置VO状态为丢失,算法结束。如果没有超过,返回第1步
3 改进:优化PnP的结果
尝试RANSAC PnP加上迭代优化的方式估计相机位姿。
通过运行程序,对比之前的结果发现估计的运动明显稳定了很多。同时,由于增加的优化仍是无结构的,规模小,对计算时间影响忽略不计。整个VO计算时间在30ms左右。
不过这个版本的VO仍然受到两两帧匹配的局限性影响。一旦视频序列中的某个帧丢失了,就会导致后续的帧也无法和上一帧匹配。
4 改进: 局部地图

在使用地图的VO中,每个帧为地图贡献一些信息。我们维护一个不断更新的地图,只要地图是正确的,即使中间的某帧出现了差错,仍有希望求出那些帧的正确位置。
地图分为局部和全局两种。在VO中,我们更关心直接用于定位的局部地图。局部地图的一个问题是维护他的规模,为了保证实时性,我们需要保证地图规模不至于太大。此单个帧与地图的特征匹配符存在一些加速手段。
重点观察以下几项
1 在提取到第一帧的特征点之后,将第一帧的所有特征点全部放入地图中
2 后续帧中,使用OptimizeMap函数对地图进行优化。包括删除不在视野内的点,在匹配数量减少时添加新点。
3 特征匹配代码。在匹配之前,我们从地图中拿出一些候选点,然后将他们与当前帧的特征描述子进行特征匹配。
5 小结
我们这种局部的方式有着明显的缺点
1 容易丢失。
一旦丢失,我们需要等到相机转回来或者重置整个VO以跟踪新的图像数据。
2 轨迹飘逸
主要原因是每次估计的误差会累积至下一次估计,导致长时间轨迹不准确。大一点的局部地图可以环节这种现象,但它始终是存在的。