1 知识图谱概论
知识图谱与语义技术概述:
Vannevar Bush
Sir Tim Berners-Lee:以链接为中心的系统
语义网:从链接文本到链接数据
语义网络(Semantic Network)->本体论(Ontology)->Web->The Semantic Web->Link Data->知识图谱(Knowledge Graph,KG)
KG辅助搜索,从文本搜索变为语义搜索。
手工众包,格式转化,元组抽取,实体融合,链接预测,推理补全,语义嵌入。
KG辅助问答,输入自然语言,返回精确答案。
给万物都挂接一个背景知识库。
KG辅助决策。
预先抽取语义->建立数据链接,不规范数据表达->规范数据表达,粗糙数据->可计算数据。
Palantir:动态本体、Kensho:金融知识图谱。
KG辅助AI,常识推理。
KG的本质:
Web视角:像建立文本之间的超链接一样,建立数据之间的语义链接,并支持语义的搜索。
NPL视角:怎样从文本中抽取语义和结构化数据。
深度学习->学习
知识图谱->推理
各种知识图谱项目:
CYC:常识知识库。
包括了术语Terms(词)、断言Assertions(句子)
Wordnet:英语词义消歧。
ConceptNet:常识知识库。
主要依靠互联网众包、专家创建、游戏三种方法构建。
以三元组(主谓宾)形式的关系型知识构成,更加接近自然语言。
Freebase:通过开源免费吸引用户。
Wikidata:目标是构建全世界最大的免费知识库。
DBPedia:数据库版本的Wikipedia。
YAGO:集成了Wikipedia、Wordnet、GeoNames三个来源的数据。
考虑了时间和空间维度的扩展。
Babelnet:多语言词典知识库。
NELL:互联网挖掘方法从Web自动抽取三元组知识。
Concept Graph:以概念层次体系为中心的知识图谱。
OpenKG:中文知识图谱。
Zhishi.me:合成中文数据库。
cnSchema:开放的中文知识图谱Schema。
知识图谱技术概览:
数据来源:文本、结构化数据库、多媒体、传感器、众包->KG Data。
基于数理逻辑的知识表示->基于向量空间学习的分布式知识表示。
语义网知识表示框架:
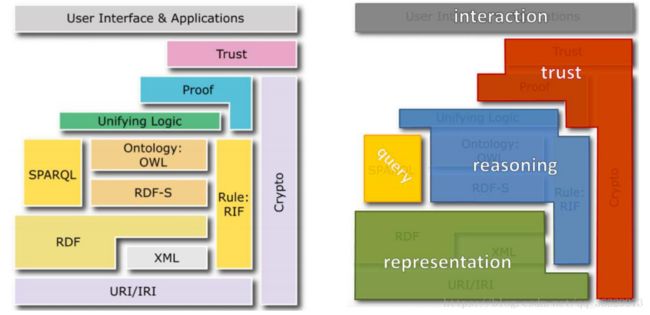
RDF:Triple-based Assertion model
主语、宾语是节点,谓语是边。
RDF Graph:Directed Labeled Graph
基本数据模型:有向标记图。
RDFS:Simple Vocabulary and Schema(类比数据库表、字段的设计)
OWL:本体(Ontology)是一个概念和关系的描述,是对其形式化的定义。通过规范描述。
OWL extends RDF Schema
SPARQL:RDF的查询语言。类SQL的声明式的查询语言。
子图匹配。
JSON-LD:数据交换格式。适用于作为程序之间做数据交换。
RDFa、HTML5 MicroData:在网页中嵌入语义数据。
KG的分布式表示:
KG Embedding:KG的分布式表示,在保留语义的同时,将知识图谱中的实体和关系映射到连续的稠密的低维向量空间。
张量分解、神经网络、距离模型(翻译模型)。
知识抽取:NLP + KR:
非结构化文本数据->文本预处理->分词、词性标注、语法解析、依存分析->NER命名实体识别、Entity Linking实体链接->关系抽取、事件抽取->KR:三元组、多元关系、模态知识
基于知识工程(正则、模板匹配、规则约束)
基于本体抽取(知识挖掘,PRA)
基于模型的抽取(模型、训练)
知识存储:
基于干系数据库的存储、基于原生图的存储。
知识问答:
KBQA基于知识库的问题回答。
语义解析->语义表示->查询数据库->返回用户
知识推理:
基于已知事实推出未知事实的计算过程。
缺省推理、连续变化推理、空间推理、因果关系推理。
基于描述逻辑的推理-本体推理:
描述逻辑是一种用于知识表示的逻辑语言和以其为对象的推理方法。
知识融合:
在不同数据集中找出同一个实体。
Dedupe基于python的工具包。
LIMES不要求两个数据集的实体具有相似的结构。
知识众包:
Wikibase、Schema.ORG
典型案例简介:
Open PHACTS:药物研发的开放数据访问平台。
SAP:企业知识图谱应用。
BBC ONTOLOGIES:更好的搜索体验。