Python进阶语法
带*号的与python无关 只是一些面试中常见的问题
1.python的内存管理
对象的引用记数机制
- python内部使用引用计数,来保持追踪内存中的对象,所有对象都有引用计数
引用计数增加的情况
- 一个对象分配一个新名称
- 将其放入一个容器中(如列表,元组或字典)
引用技术减少的情况
- 使用
del语句对对象别名显示的销毁 - 引用超出作用域或被重新赋值
sys.getrefcount()函数,可以获得对象的当前引用计数。对于不可变数据(如数字和字符串)解释器会在程序的不同部分共享内存,以便节约内存
垃圾回收
- 当一个对象的引用计数归零后,它将被垃圾收集机制处理掉
- 当两个对象a和b相互引用时,
del语句可以减少a和b的引用计数,并销毁用于引用底层对象的名称。然而由于每个对象都包含一个对其他对象的应用,因此引用计数不会归零,对象也不会销毁(从而导致内存泄漏),为解决这一问题,解释器会定期运行一个循环检测器,搜索不可访问对象的循环并删除它们
内存池机制
Python提供了对内存的垃圾收集机制,但是它将不用的内存放到内存池而不是返回给操作系统
Pymalloc机制,为了加速Python的执行效率,Python引入了一个内存池机制,用于管理对小块内存的申请和释放Python中所有小于256个字节的对象都使用Pymalloc实现的分配器,而大的对象则使用系统的malloc- 对于
Python对象,如整数,浮点数和List,都有其独立的私有内存池,对象间不共享他们的内存池。也就是说如果你分配了又释放了大量的整数,用于缓存这些整数的内存就不能再分配给浮点数
2.迭代器和生成器
迭代器
访问集合元素的一种方式
字符串,列表或元组对象都可用于创建迭代器[int类型不可以],迭代器可以记住遍历的对象的上一个位置;从集合的第一个元素开始访问,直到所有的元素被访问结束,即只能往前不会后退
手动创建:
list实现
items = [0, 1, 2, 3, 4]
it = list(iter(items))
print(it)
自定义迭代器:内建函数
iter()可以从迭代对象中获得迭代器
生成器
通过yield语句快速生成迭代器
3.import导包过程
模块:一个 .py文件 包:一个文件夹包括一个__init__.py文件
import module
运行模块里的全部代码
from module import var/class
从模块里单独引入一个变量/类,而不执行模块内其他语句
import package
相当于引入包内的__init__模块
from package import module
引入包内的模块
4.装饰器实现
基于AOP思想,面向切面编程:编译时,类和方法加载时,动态地将代码引入到类的指定法指定方法:指定位置的编程思想
装饰器是一个著名的设计模式,经典的有插入日志/性能测试/事务处理
定义
在代码运行期间动态增加功能的方式
单例模式
确保某个类只有一个实例存在
装饰器实现单例模式
from functools import wraps
def Singleton(cls):
_instance = {}
@wraps(cls) # 保留原有函数的名称和docstring
def _singleton(*args, **kwargs):
if cls not in _instance:
_instance[cls] = cls(*args, **kwargs)
return _instance[cls]
return _singleton
@Singleton
class Settings():
"""Docstring"""
def __init__(self):
self.a = 'xxx'
self.b = 'xxx'
settings = Settings()
print(settings.a)
print(Settings.__name__)
print(Settings.__doc__)
@wraps的作用
Python装饰器在实现的时候,被装饰后的函数其实已经时另外一个函数了(函数名等函数属性会发生改变),为了不影响,Python的functools包中提供了一个叫wraps的decorator来消除这样的副作用。写一个decprator的时候,最好在实现之前加上functools的wrap,它保留原有函数的名称和docstring
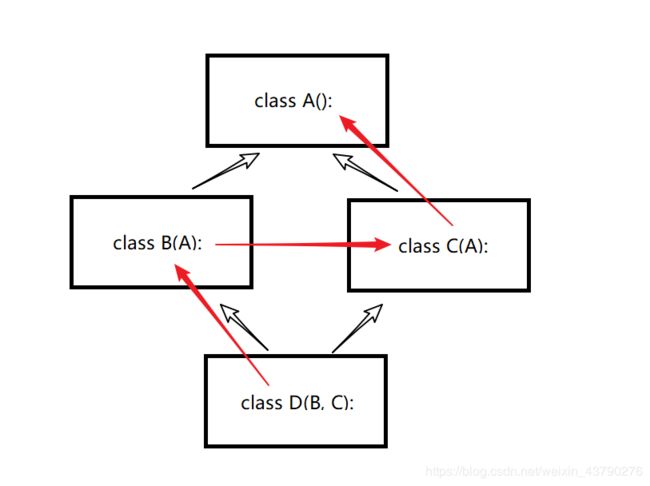
5.菱形继承(钻石继承)
__mor__方法可以查看继承顺序
*6.epoll与select区别
(1) 函数使用上:epoll 使用一组函数来完成任务,而不是单个函数
(2) 效率:select 使用轮询来处理,随着监听 fd 数目的增加而降低效率。而 epoll 把用户关心的文件描述符事件放在内核里的一个事件表中,只需要一个额外的文件描述符来标识内核中的这个事件表即可。
7.uwsgi
uWSGI是一个Web服务器,它实现了WSGI协议、uwsgi、http等协议。Nginx中HttpUwsgiModule的作用是与uWSGI服务器进行交换。
要注意 WSGI / uwsgi / uWSGI 这三个概念的区分。
- WSGI是一种通信协议。
- uwsgi同WSGI一样是一种通信协议。
- 而uWSGI是实现了uwsgi和WSGI两种协议的Web服务器。
uwsgi协议是一个uWSGI服务器自有的协议,它用于定义传输信息的类型(type of information),每一个uwsgi packet前4byte为传输信息类型描述,它与WSGI相比是两样东西。
为什么有了uWSGI为什么还需要nginx?因为nginx具备优秀的静态内容处理能力,然后将动态内容转发给uWSGI服务器,这样可以达到很好的客户端响应。
8.eval
eval是Python的一个内置函数,这个函数的作用是,返回传入字符串的表达式的结果。即变量赋值时,等号右边的表示是写成字符串的格式,返回值就是这个表达式的结果。可实现list、dict、tuple与str之间的转化
*9.如何判断链表是否有环?
快慢指针,例子:运动员赛跑 快的肯定会再次追上慢的
10.Python中的GIL锁
在C语言写的python解释器中存在全局解释器锁,由于全局解释器锁的存在,在同一时间内,python解释器只能运行一个线程的代码,这大大影响了python多线程的性能。而这个解释器锁由于历史原因,现在几乎无法消除。
python GIL 之所以会影响多线程等性能,是因为在多线程的情况下,只有当线程获得了一个全局锁的时候,那么该线程的代码才能运行,而全局锁只有一个,所以使用python多线程,在同一时刻也只有一个线程在运行,因此在即使在多核的情况下也只能发挥出单核的性能。
既然python在同一时刻下只能运行一个线程的代码,那线程之间是如何调度的呢?
对于有io操作的线程,当一个线程在做io操作的时候,因为io操作不需要cpu,所以,这个时候,python会释放python全局锁,这样其他需要运行的线程就会使用该锁。
对于cpu密集型的线程,比如一个线程可能一直需要使用cpu做计算,那么python中会有一个执行指令的计数器,当一个线程执行了一定数量的指令时,该线程就会停止执行并让出当前的锁,这样其他的线程就可以执行代码了。
由上面可知,至少有两种情况python会做线程切换,一是一但有IO操作时,会有线程切换,二是当一个线程连续执行了一定数量的指令时,会出现线程切换。当然此处的线程切换不一定就一定会切换到其他线程执行,因为如果当前线程 优先级比较高的话,可能在让出锁以后,又继续获得锁,并优先执行。
在做科学计算的时候是用的单线程,因为这种计算是需要CPU一直做计算的,如果用多线程反而会降低计算速度。
11.C/C++嵌入Python
- 安装python程序,这样才能使用python的头文件和库
- 在我们写的源文件中增加“Python.h”头文件,并且链入“python**.lib”库(还没搞清楚这个库时静态库还是导出库,需要搞清楚)
- 掌握和了解一些python的C语言api,以便在我们的c++程序中使用常用的一些C API函数
*12.HTML5的新特性
增强了图片渲染、数据存储、影音和多任务处理等功能
新加的属性是:
1.canvas动画
2.本地存储localstorage
3.时间监听 addeventlistener(window的对象)
4.sessionstorage数据在浏览器关闭后自动删除
5.媒体video和audio
需要第三方插件就能播放音频和视频了,可以直接插入,并且用同一的API接口控制。
6.语义化的标签
语义化的标签对搜索引擎优化有好处,更易被搜索到。其他的同事维护代码也很方便一点
7.表单的控制
email、time、search
8.Geolocation 地理定位
*13.page cache
-
什么是page cache的机制
当APP需要读取磁盘文件数据时,linux先分配一些内存,将数据从磁盘读区到内存中,然后再将数据传给APP。
当APP需要写数据到磁盘文件时,linux先分配内存接受用户数据,然后再将数据从内存写到磁盘。 -
page cache的结构
linux的文件cache分为两层,一个是page cache,另一个是buffer cache;每一个page cache包含若干个buffer cache。真正指向磁盘block的其实是buffer cache里面的指针。
-
cache是如何提高性能的呢?
靠的是cache的预读
对于每个文件的第一次读请求,系统读入所请求的页面并读入紧随其后的的少数几个页面(不少于1个,通常是3个),此种读区成为同步预读;
第二次读取,如果页面不在cache中,说明不是顺序读取,继续重复第一次的同步预读过程。
第二次读取,如果页面在cache中,说明是顺序读取,会将预读group扩大一倍,将不在cache中的文件数据读进来。此为异步预读。
*14.如何强制要求浏览器不走缓存
- 浏览器设置,我Chrome浏览器,按下快捷键
Shift+F5 - 服务端返回文件的时候,设置响应头
- 每次请求的时候家一个随机数参数或者时间戳,它的作用就是让浏览器误以为请求的是一个新链接,这样浏览器就不会区读取缓存里的内容
*15.用户态通过终端切换到内核态
用户态与内核态
- Linux把内存主要分为四个段,分别是内核代码段、内核数据段、用户代码段、用户数据段
- 内核两个段特权级都为最高级0,用户两个段特权级都为最低级3。内核代码段可以访问内核数据段,但不能访问用户数据段和用户代码段,同样地,用户代码段可以访问用户数据段,但不能访问内核数据段或内核代码段
- 当前进程运行的代码若属于内核代码段,则称当前进程处于内核态,若属于用户代码段,则称当前进程处于用户态。用户代码段和内核代码段的代码分别运行在用户栈上和内核栈上。
- 处于用户态的进程若想要切换到内核态,便要依靠中断
过程
- 第一步,当前进程在用户态用汇编指令
int<中断向量号>发出中断请求,设中断向量号为i,i∈{3,4,5,128}。 - 第二步,CPU在总线上捕捉到中断向量i, 通过寄存器IDTR找到IDT,再找到下标为i的中断描述符,进行两道特权级检查
- 第三步,用户栈切换到内核栈,切换的关键在于栈地址的切换,而栈地址由某些特定寄存器的值共同决定,故关键在于改变这些特定寄存器的值。如何改变?依靠TTS——由于TSS存放着内核栈的栈地址,把TSS里的内核栈栈地址赋给这些特定寄存器,便能完成从用户栈到内核栈的切换,即完成了用户态到内核态的切换
- 切换成功后,还有许多操作,强调两处操作,一是将用户栈栈地址保存在内核栈上,以便从内核栈切换回用户栈,二是取出第二步访问过的中断描述符的中断服务函数的入口地址将其保存在内核栈上,并跳转到中断服务函数开始执行
*16.中断及系统调用
- CPU每次执行完一条指令后,总会先检查有无中断请求,无则执行下一条命令,有则在总线上读取中断的标识码即中断向量
- 内存中存放着一个中断描述符表(Interrupt Descriptor Table,简称IDT,也可以叫做中断向量表),表里有许多个中断描述符,所以要在中断描述符表中找到特定一项中断描述符需要一个下标,这个下标就是上文提及的中断向量,就像访问数组中的特定元素一样。每个中断描述符的内容有3项信息比较重要——该描述符的特权级,中断服务函数的入口地址,中断服务函数所在段的特权级。在Linux中,所有的中断服务函数都放在内核代码段,故中断服务函数所在段的特权级都为0
- 那CPU通过什么手段IDT子内存中的地址呢?答案是寄存器。CPU有个寄存器叫IDTR,用于存放IDT的首地址和长度
系统调用
从用户空间到内核空间并找到函数执行体
软中断:当用户空间使用系统调用的时候就会出发软中断。当要准备从用户态到内核态执行,就会有一个指令——SWI(software interrupt)被执行。进入内核态
判断不同的系统调用:当从用户空间进入到内核态,系统并不知道要执行哪个系统调用,为了解决这个问题,先将每个系统调用函数进行编号,再调用相应的函数的时候,将相应的编号进行放入寄存器r7.根据编码并查看相应的表。就得到相应的函数
*17.如何交换两个元素不使用中间量
异或
#include*18.局部变量和全局变量在内存中的存储位置
1.局部变量
在一个函数内部定义的变量是内部变量,它只在本函数范围内有效,也就是说只有在本函数内才能使用它们,在此函数以外时不能使用这些变量的,它们称为局部变量。
局部变量保存在动态数据区的栈中,只有在所在函数被调用时才动态地为变量分配存储单元。
1).主函数main中定义的变量也只在主函数中有效.
2).不同函数中可以使用名字相同的变量,它们代表不同的对象,互不干扰.
3).形参也是局部变量.
4).在复合语句中定义的局部变量,这些变量只在本复合语句中有效.
2.全局变量
在函数外定义的变量是外部变量,外部变量是全局变量,全局变量可以为本文件中其它函数所共用,它的有效范围从定义变量的位置开始到本源文件结束。
全局变量位于静态数据区中。
1).设全局变量的作用:增加了函数间数据联系的渠道.
2).建议不再必要的时候不要使用全局变量,因为
a.全局变量在程序的全部执行过程中都占用存储单元.
b.它使函数的通用性降低了
3).如果外部变量在文件开头定义,则在整个文件范围内都可以使用该外部变量,如果不再文件开头定义,按上面规定作用范围只限于定义点到文件终了.如果在定义点之前的函数想引用该外部变量,则应该在该函数中用关键字extern作外部变量说明.
4).如果在同一个源文件中,外部变量与局部变量同名,则在局部变量的作用范围内,外部变量不起作用.
3.静态变量
静态变量并不是说其就不能改变值,不能改变值的量叫常量。 其拥有的值是可变的 ,而且它会保持最新的值。说其静态,是因为它不会随着函数的调用和退出而发生变化。即static局部变量只被初始化一次,下一次依据上一次结果值;
静态变量的作用范围要看静态变量的位置,如果在函数里,则作用范围就是这个函数。
静态变量属于静态存储方式,其存储空间为内存中的静态数据区(在静态存储区内分配存储单元),该区域中的数据在整个程序的运行期间一直占用这些存储空间(在程序整个运行期间都不释放),也可以认为是其内存地址不变,直到整个程序运行结束(相反,而auto自动变量,即动态局部变量,属于动态存储类别,占动态存储空间,函数调用结束后即释放)。静态变量虽在程序的整个执 行过程中始终存在,但是在它作用域之外不能使用。
另外,属于静态存储方式的量不一定就是静态变量。 例如:外部变量虽属于静态存储方式,但不一定是静态变量,必须由 static加以定义后才能成为静态外部变量,或称静态全局变量。
19.面向对象的四种基本特征
抽象 封装 继承 多态
- 抽象:将一些事物的共性和相似点愁里出来,并将这些属性归位一个类
- 封装:隐藏内部的细节,保证软件部件具有优良的模块性的基础,“高内聚,低耦合”
- 继承:在定义和实现一个类的时候,可以在一个已经存在的类所定义的内容作为自己的内容并可以加入新内容,或修改原来的方法
- 多态:运行时刻接口匹配的对象相互替换的能力
20.or
对于
or操作符
-
只要两边表达式为真,整个表达式的结果是左边表达式的值
1 or 3 #1 -
如果是一真一假,返回真值表达式的值
a= '' a or -1 #-1 -
如果两个都是假,比如空值和0,返回的是右边的值
a = '' a or 0 #0
21.斐波那契生成器
- 生成器做法
def fib(n):
a = b = 1
for i in range(n):
yield a
a, b = b, a + b
for x in fib(num): #num为所求的数
print(x)
- 常规做法
def fib(n):
a, b = 1, 1
for i in range(n-1):
a, b = b, a+b
return a
print(fib(num)) # num为所求的数
- 递归方法
def fib(n):
if m == 1 or m == 2:
return 1
return fib(m -1) + fib(m - 2)
print(fib(num)) # num为所求的数
22.extend和append
- append
a = [1,2,3]
b = [4,5,6]
a.append(b)
# [1, 2, 3, [4, 5, 6]]
- extend
>>> a = [1, 2, 3]
>>> b = [4, 5, 6]
>>> a.extend(b)
>>> print(a)
# [1, 2, 3, 4, 5, 6]