tensorflow使用GAN生成手写数字(代码介绍)
前言
本篇文章主要介绍如何来设置一个GAN网络利用MNIST手写数字图片进行训练来生成手写数字图片,代码主要参考github的实现,在原来的基础上做了一些修改和新增了一些功能。
GAN简介
生成对抗式网络(GAN,Generative Adversarial NetWorks):是深度学习中的一种模型,属于无监督学习算法。模型主要包括两个模块,生成模型(Generative Model)和判别模型(Adversarial Model),通过两个模型的互相博弈使得生成模型产生接近于真实数据。举个简单一点的例子,方便理解,
例如:制作假钞团伙和真钞的鉴别专家,对于假钞制作团伙来说他们为了能让假钞顺利使用,那么他们就需要让他们制作的假钞像真钞一样,那样他们制作的假钞就不会被鉴别专家发现。所以假钞的制作团伙就需要不断的模仿真钞,不断的使得假钞越来越想真钞,从而骗过钞票的鉴别专家。在这个例子中假钞制作团伙就相对于GAN中的
生成模型,钞票鉴别专家就是判别模型。生成模型就是通过不断的和判别模型进行博弈不断学习,最终使得生成模型达到以假乱真的目的。
在GAN中有一个非常重要的公式,如果理解了,就代表你弄懂了GAN,公式如下:
min G max D V ( D , G ) = E x ~ p d a t a ( x ) [ l o g D ( x ) ] + E z ~ p z [ l o g ( 1 − D ( G ( z ) ) ) ] {\min_G\max_D\ V(D,G)=\Epsilon_{x\text{\textasciitilde}p_{data}(x)}[logD(x)]+\Epsilon_{z\text{\textasciitilde}p_{z}}[log(1-D(G(z)))]} GminDmax V(D,G)=Ex~pdata(x)[logD(x)]+Ez~pz[log(1−D(G(z)))]
GAN论文原文:http://papers.nips.cc/paper/5423-generative-adversarial-nets.pdf
公式解读:
- 对于
G(生成模型)来说要想模型生成的结果最好,要使得上式取得最小值。对于生成模型我们只需要看后面一部分的式子 l o g ( 1 − D ( G ( z ) ) ) log(1-D(G(z))) log(1−D(G(z))), z z z表示的是输入的噪声,生成模型就是通过这个输入噪声来产生一个输出。D(判别模型)对于真实样本输出为1,对于虚假样本输出0,D(x)表示判别模型的输出,x表示输入数据(真实样本或虚假样本),要想使得生成模型G生成的接近真实样本,也就是要让判别模型D的输出为1,也就是要让 D ( G ( z ) ) D(G(z)) D(G(z))尽量接近于1,那么 1 − D ( G ( z ) ) 1-D(G(z)) 1−D(G(z))就会接近于0。当x接近于0时, l o g ( x ) log(x) log(x)会趋于负无穷,所以当上式趋于无穷小时, D ( G ( z ) ) D(G(z)) D(G(z))会趋于1,此时的生成模型生成的数据接近于真实数据,生成模型达到最优。 - 对于
D(判别模型)来说要想模型的性能最好,就要使得上式取得最大值。上式中的 x ~ p d a t a x\text\textasciitilde p_{data} x~pdata表示真实样本, z ~ p z z\text\textasciitilde p_z z~pz表示虚假样本。所以,要想使得D的性能最优,对于真实样本的输入 D ( x ) D(x) D(x)应该输出1,对于虚假样本的输入 D ( G ( z ) ) D(G(z)) D(G(z))应该输出0,所以此时 V ( D , G ) V(D,G) V(D,G)取得最大值。
GAN生成手写数字
主要利用MNIST数据集进行训练来生成手写数字
- 软件环境
- 系统:win10
- python:3.6.4
- tensorflow-gpu:1.8.0
- matplotlib:2.1.2
- numpy:1.14.0
- github地址:GAN生成手写数字
- GAN架构

上图主要展示了G(生成模型)和D(判别模型)的网络架构,可以发现G和D的结构刚好是一个逆的过程,GAN主要利用多层感知器来实现的,所以最终生成的手写数字图片会比卷积结构的生成模型效果要差一些,后面会介绍使用DCGAN来实现手写数字图片的生成。 - 代码介绍
- GAN结构设计
将G和D网络每层隐藏节点数定义在了字典中
class GAN:
#GAN Generator and Discriminator hidden layer config
Generator_config =
{"layer_1":256,"layer_2":512,"layer_3":1024,"layer_4":784}
Discriminator_config =
{"layer_1":1024,"layer_2":512,"layer_3":256,"layer_4":1}
# initializers weights and bias function
w_init_fun = tf.truncated_normal_initializer(mean=0, stddev=0.02)
b_init_fun = tf.constant_initializer(0.)
# G(z)
@staticmethod
def Generator(x):
"""GAN Generator Net
Args:
x(tensor):input noise
Returns:
output(array):output one dimensional image data
"""
config = GAN.Generator_config
w_init = GAN.w_init_fun
b_init = GAN.b_init_fun
# 1st hidden layer
w0 = tf.get_variable('G_w0', [x.get_shape()
[1],config["layer_1"]], initializer=w_init)
b0 = tf.get_variable('G_b0', [config["layer_1"]],
initializer=b_init)
h0 = tf.nn.relu(tf.matmul(x, w0) + b0)
# 2nd hidden layer
w1 = tf.get_variable('G_w1', [h0.get_shape()[1],
config["layer_2"]], initializer=w_init)
b1 = tf.get_variable('G_b1', [config["layer_2"]],
initializer=b_init)
h1 = tf.nn.relu(tf.matmul(h0, w1) + b1)
# 3rd hidden layer
w2 = tf.get_variable('G_w2', [h1.get_shape()
[1],config["layer_3"]], initializer=w_init)
b2 = tf.get_variable('G_b2', [config["layer_3"]],
initializer=b_init)
h2 = tf.nn.relu(tf.matmul(h1, w2) + b2)
# output hidden layer
w3 = tf.get_variable('G_w3', [h2.get_shape()
[1],config["layer_4"]], initializer=w_init)
b3 = tf.get_variable('G_b3', [config["layer_4"]],
initializer=b_init)
output = tf.nn.tanh(tf.matmul(h2, w3) + b3)
return output
- 损失函数的定义
为了避免出现log(0),所以我们需要在后面加一个极小的数。为了便于训练生成网络和判别网络,我们需要通过求loss最小化问题来求解网络的参数。式中的D_real表示判别网络对于真实样本的输出,D_fake表示对虚假样本的输出。当D最优时,对所有的D_real都输出1,对所有的D_fake都输出0,所以此时的D_loss最小,也就是判别网络D的损失达到最小值。当G最优时,D_fake的输出应该为1(因为此时G生成的样本已经接近于真实样本,此时D已经无法判断,认为G生成的样本就是真实样本),此时G_loss最小,也就是生成网络G的损失达到最小值。
#a minimum value for log loss bias
eps = 1e-2
#Discriminator net loss
D_loss = tf.reduce_mean(-tf.log(D_real + eps) - tf.log(1 -
D_fake + eps))
#Generator net loss
G_loss = tf.reduce_mean(-tf.log(D_fake + eps))
- 模型的训练
训练的时候我们先训练D,然后再训练G,其实这个顺序关系不大,需要保持在训练时,两个网络的参数都能够更新,从而达到相互博弈的效果。
for epoch in range(train_epoch):
G_losses = []
D_losses = []
epoch_start_time = time.time()
for iter in range(train_set.shape[0] // batch_size):
# update discriminator
x_ = train_set[iter*batch_size:(iter+1)*batch_size]
z_ = np.random.normal(0, 1, (batch_size, 100))
loss_d_, _ = sess.run([D_loss, D_optim], {x: x_, z:
z_, drop_out: 0.3})
D_losses.append(loss_d_)
# update generator
z_ = np.random.normal(0, 1, (batch_size, 100))
loss_g_, _ = sess.run([G_loss, G_optim], {z: z_,
drop_out: 0.3})
G_losses.append(loss_g_)
- 加载训练好的模型生成样本
通过加载训练好的模型,直接生成手写数字的图片。
github项目中包含已经训练好的ckpt文件,加载模型可以直接生成。
def gan_generate_mnist_image(ckpt_path):
"""generate image by load ckpt model
"""
#generate random vector mean is 0 and std is 1
gan_input_z = np.random.normal(0,1,(25,100))
with tf.Session() as sess:
with tf.variable_scope('G'):
z = tf.placeholder(dtype=tf.float32,shape=(None,100))
G_z = GAN.Generator(z)
#load model
saver = tf.train.Saver()
saver.restore(sess,ckpt_path)
generate_images = sess.run(G_z,feed_dict={z:gan_input_z})
fig,ax = plt.subplots(5,5,figsize=(5,5))
for i,j in itertools.product(range(5),range(5)):
ax[i,j].get_xaxis().set_visible(False)
ax[i,j].get_yaxis().set_visible(False)
for k in range(5*5):
i = k // 5
j = k % 5
ax[i,j].cla()
ax[i,j].imshow(np.reshape(generate_images[k],
(28,28)),cmap="gray")
fig.text(0.5,0.04,"Generator Net generate
image",ha="center")
plt.show()
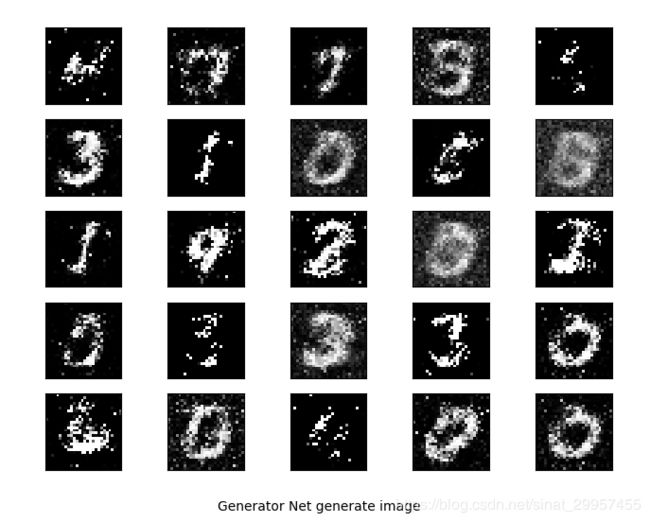
- 结果展示
- 训练结果
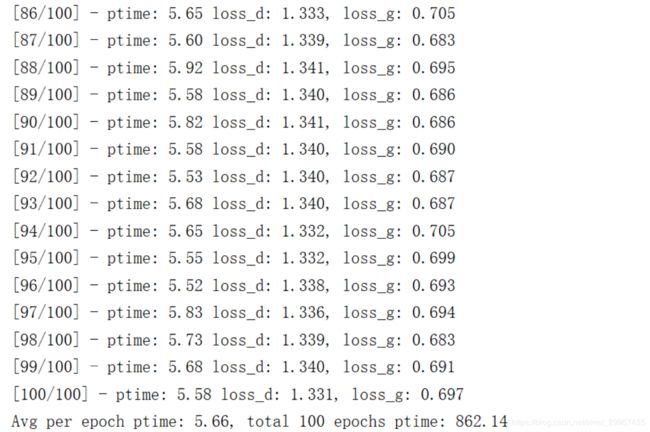
使用的是GTX1060训练的每个batch大约需要花5.7s左右。
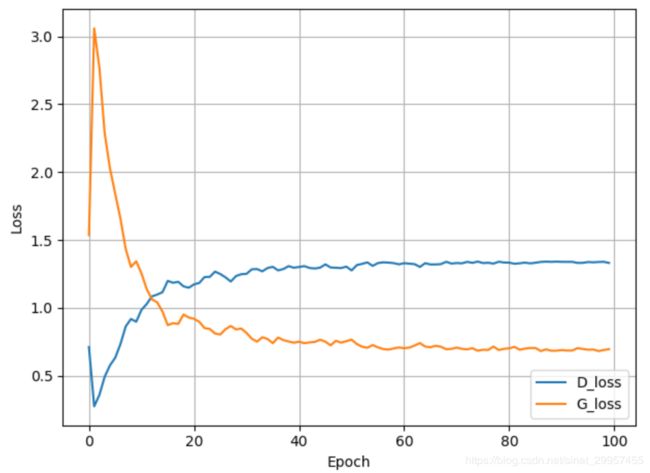
- loss变化
随着epoch的增大,G_loss越来越小。
- 最终生成的手写数字图片
可以发现迭代100个epoch之后,GAN生成的手写数字图片效果并不是特别好,下一篇文章介绍使用DCGAN来生成手写数字图片,效果会比这个结果好很多。