- ML-Agents(九)Wall Jump
- 一、前言
- 二、课程训练(Curriculum Learning)
- 一个教学示例
- 具体实现
- 三、环境与训练参数
- 四、场景基本构成
- 五、代码分析
- Agent初始化
- 环境观测值收集
- Agent动作反馈
- Agent重置
- 其他
- 六、训练
- 训练配置参数
- 开始训练
- 七、总结
ML-Agents(九)Wall Jump
一、前言
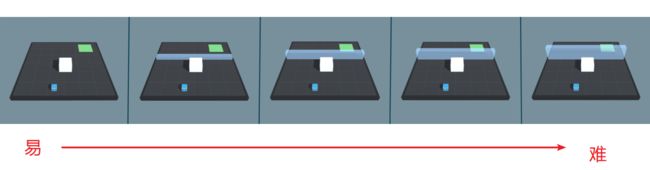
这次我们来看一下Wall Jump示例,这个例子又和我们之前学习的示例不同,它引用了Curriculum Learning(课程学习)的学习方法,简单来讲就是使用授课学习的方式来训练神经网络,学习的样本从易到难,模拟人类学系的过程。先来看看本示例的最终效果:
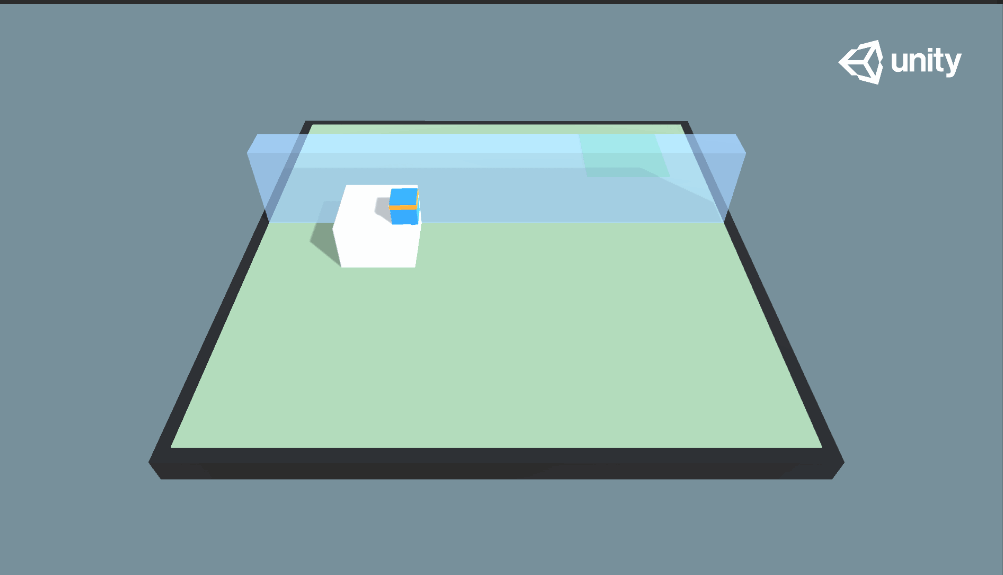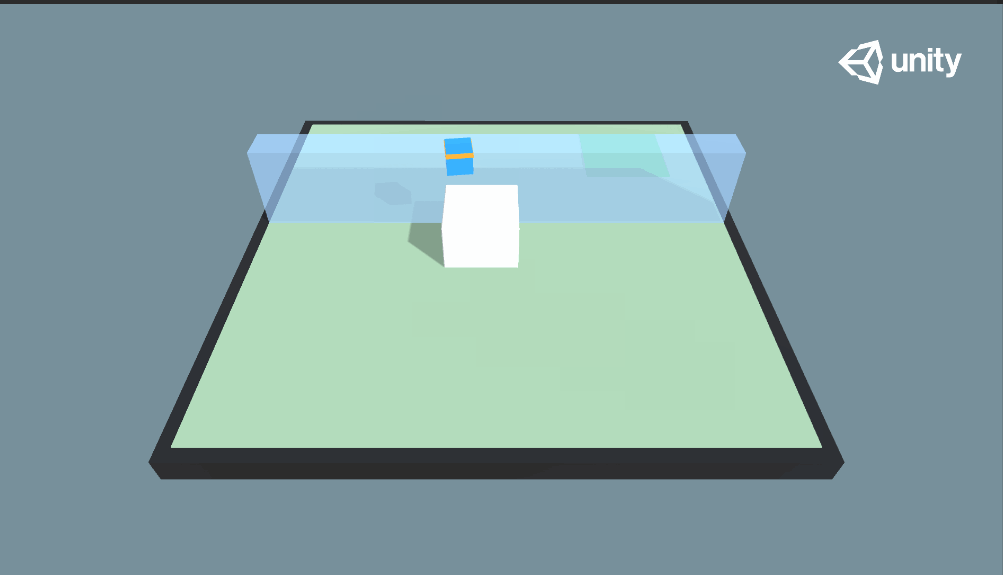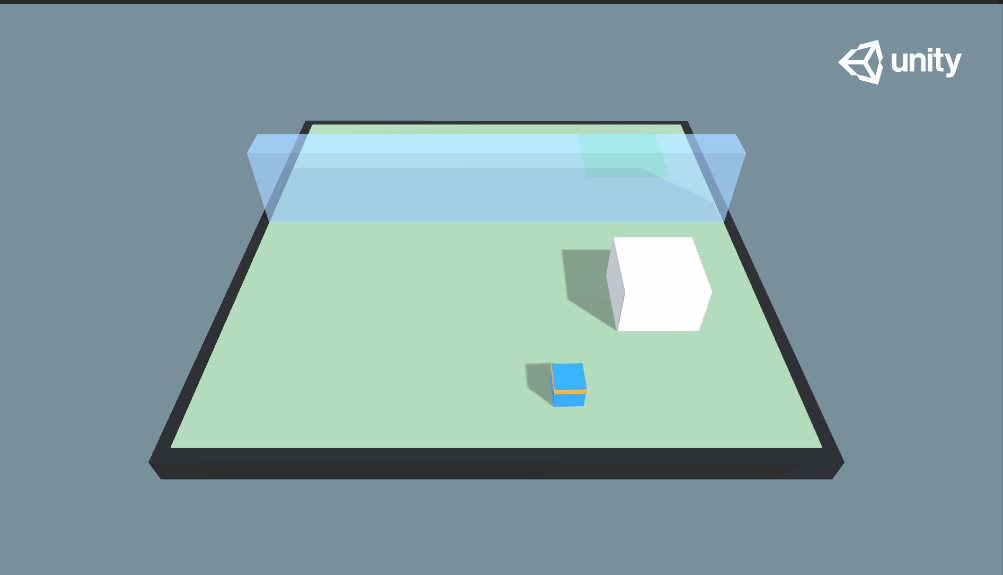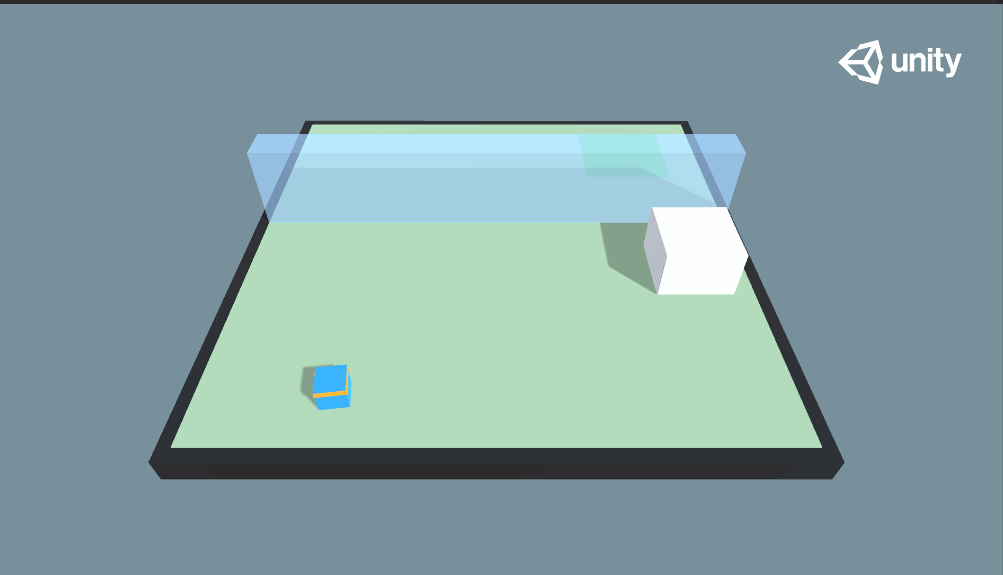
由图中可以看到本示例的效果,小蓝需要越过蓝色的墙体到达绿色的目标地点,此外还可以留意到,蓝色的墙体高度是随机变化的:当蓝色的墙体较高时,小蓝推动大白块当梯子才能越过墙体;当蓝色墙体高度较低时,小蓝则可以直接跳跃过去。
因此,在本示例中,小蓝拥有两个训练好的训练模型——SmallWallJump和BigWallJump,分别对应矮墙(无墙)和高墙情况下的行动。
下面我们先来学习一下官方对于Curriculum Learning的相关文档。
二、课程训练(Curriculum Learning)
这一节内容主要是翻译官方文档 Training with Curriculum Learning。
首先文档介绍了课程学习是ML-Agents的一项功能,它允许在训练的过程中更改环境的属性来帮助学习。
一个教学示例
先想象一个任务,agent需要越过一堵墙到达目标位置(其实就是Jump Wall)。一开始训练agent来完成该任务其实是一个随机策略。因此直接训练的话,开始的策略将使agent在循环中运行,并且可能永远,或者很少正确地越过墙体到达目标以获得奖励(意思就是一开始要是训练难度过大,agent可能很难理解自己要达成的目标)。如果我们从一个更简单的任务开始,例如让agent朝着一个无障碍的目标前进,那么agent则会很容易地学会完成任务。在此基础上,我们再通过增加墙体的大小来慢慢增加任务的难度,直到agent可以完成最初几乎不可能完成的任务(就是小蓝通过大白块间接越过高墙)。下图展示了任务由易到难的过程:
具体实现
在一个训练环境中,具有相同Behavior Name的每一组Agent具有相同的课程。这些课程被称为"metacurriculum"(元课程)。元课程允许不同组的agent在同一环境中学习不同的课程。
指定课程
为了定义课程,第一步是确定环境的哪些参数会变化。在Wall Jump示例环境中,墙的高度则是这个变量。我们将墙的高度定义为Academy.Instance.EnvironmentParameters中可以访问的Environment Parameters参数,并通过这样做使得Python API来对其调整。我们将创建一个YAML配置文件来描述课程过程,而不是通过手动来调整课程。通过该配置文件,我们可以指定墙在训练的某个阶段开始改变高度,既可以通过训练总步数的百分比来设置,也可以通过agent获得的平均奖励来设置(Wall Jump中用的是第一种)。下面来看一会下Wall Jump环境课程的示例配置。
BigWallJump:
measure: progress
thresholds: [0.1, 0.3, 0.5]
min_lesson_length: 100
signal_smoothing: true
parameters:
big_wall_min_height: [0.0, 4.0, 6.0, 8.0]
big_wall_max_height: [4.0, 7.0, 8.0, 8.0]
SmallWallJump:
measure: progress
thresholds: [0.1, 0.3, 0.5]
min_lesson_length: 100
signal_smoothing: true
parameters:
small_wall_height: [1.5, 2.0, 2.5, 4.0]
在配置的顶层是Behavior Name,即对应于agent的行为名称(在Unity中的设置)。每种行为的课程都有以下参数:
-
measure:衡量学习进度和课程进度的方法。reward:使用奖励来衡量。progress:使用steps/max_steps比例来衡量。
-
thresholds(float array):配合measure使用,应当改变课程的阶段。简单解释一下以上两个属性,以Wall Jump为例,其measure属性为progress,对应thresholds为[0.1,0.3,0.5],其含义是:
一开始训练时,墙的高度变化范围是0-4(参考下面
parameters参数);当steps/max_steps=0.1(当前训练步数/总训练步数=0.1)时,改变一次墙的高度范围(对应下面参数为4.0-7.0);当steps/max_steps=0.3时,在改变一次墙的高度范围(6.0-8.0);当steps/max_steps=0.5时,墙的高度固定为8.0。 -
min_lesson_length(int):在课程改变之前,应该完成的episodes最小数量。如果measure设置为reward,则将使用最后min_lesson_lengthepisodes的平均奖励来确定课程是否应该改变。必须是非负数。重要:与
thresholds比较的平均奖励不同于控制台(Console)中记录的平均奖励。例如,如果min_lesson_length为100,那么在最近100的episodes的平均累积奖励超过当前thresholds设置的值后,课程将改变。记录到控制台的平均奖励是由配置文件中summary_freq参数决定的。 -
signal_smoothing(true/false):是否通过以前的值来衡量当前的进度。- 如果设置为
true,则权重将由老的0.25变为新的0.75。
- 如果设置为
-
parameters(dictionary: key(string),value(float array)):对应于要控制的环境参数。每个数组的长度应该大于thresholds的数目。具体的意思在上面也有解释。
一旦我们定义好课程配置,我们就必须使用定义的环境参数,并通过agent的OnEpisodeBegin()函数来修改环境。具体我们在后面的章节介绍Wall Jump的Agent脚本时再来看。
开始训练
至此,我们指定好了我们的课程配置文件,然后通过ml-agents命令台中使用-curriculum命令字来指定我们的配置文件,PPO将使用课程学习进行训练。例如下面要通过课程学习训练Wall Jump,在控制台中可以输入:
mlagents-learn config/trainer_config.yaml --curriculum=config/curricula/wall_jump.yaml --run-id=wall-jump-curriculum
主要是留意--curriculum命令字的使用。
Note:如果要恢复使用课程的训练,在mlagents-learn时使用--lesson标志来输入最后课程的编号。
至此,我们大概了解了在ML-Agents中课程训练的配置文件,下面我们开始正式学习Wall Jump示例。
三、环境与训练参数
- 设定:一个平台环境中,agent可以跳过一堵墙。
- 目标:Agent必须使用方块越过墙体到达目的地。
- Agents:环境中包含一个链接到两个不同模型的agent。Agent的策略链接改变取决于墙的高度(即墙低的时候<4时,采用SmallWallJump训练,墙高度>4时,采用BigWallJump训练)。策略的改变在WallJumpAgent脚本中实现,下面看代码会有介绍。
- Agent奖励设定:
- 每一步-0.0005。
- 如果agent到达目的地,则+1.0。
- 如果agent从平台上掉落,则-1.0。
- 行为参数:
- 矢量观测空间:74个变量,对应于14条射线(ray casts),每条射线检测四个物体。再加agent的世界坐标以及agent是否已接地。
- 矢量动作空间:离散(Discrete),4个分支,分别是
- 前后移动:前移、后移、No Action
- 旋转:左旋转、右旋转、No Action
- 左右移动:左平移、右平移、No Action
- 跳跃:跳跃、NoAction
- 视觉观察值:无
- 可变参数:4个
- 基准平均奖励(Big && Small Wall):0.8
四、场景基本构成
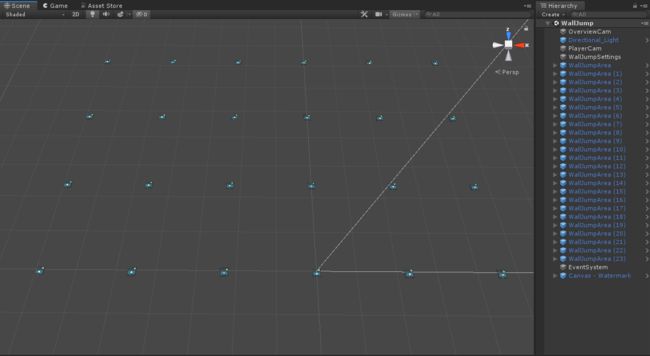
场景中包含24个训练单元,训练单元之间都相隔较远距离,如下图:
-
PlayerCam
PlayerCam是我们一开始游戏的相机,对应于第一个训练单元: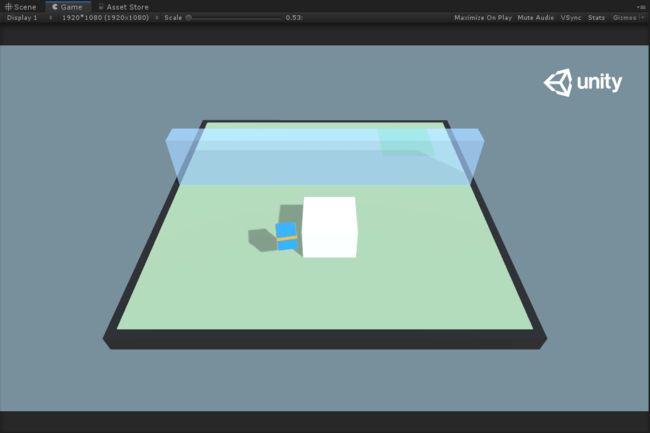
-
OverviewCam
OverviewCam是一个鸟瞰相机,注意它是在Display 2中,具体效果如下: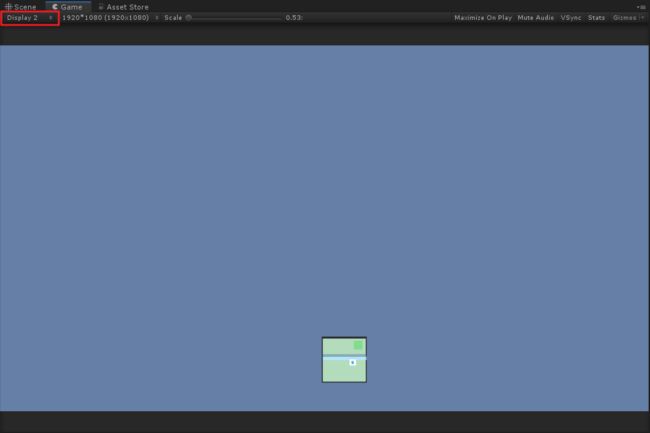
这个相机目前没发现什么特殊的用途,感觉应该是想把所有的训练单元都纳入,于是我自己调整了一下,就变成如下效果:
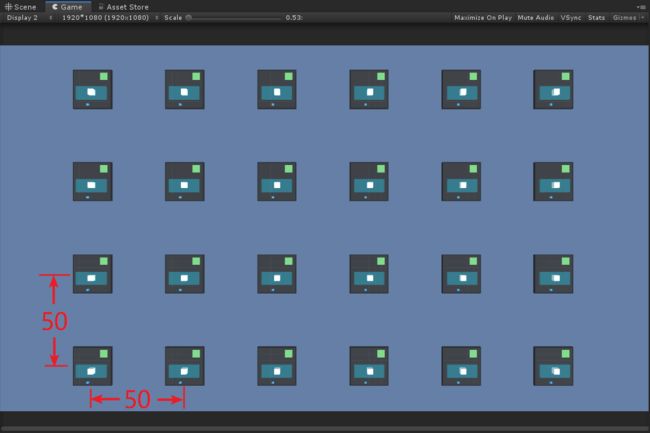
这个视图还是有一点好处,就是之后我们在训练的时候,因为这个示例也和上一次讲的PushBlock示例一样,当小蓝完成任务地面就变绿闪一下;当小蓝任务失败或者掉落平台,地面就变红闪一下。用这种鸟瞰视图就很容易看出来你训练的效果怎么样,例如一开始应该是红色闪的多,越到后面就是绿色闪的多,由此来看训练效果。
-
WallJumpSettings
WallJumpSettings物体依旧是设置了一些全局变量,主要有小蓝的速度、小蓝跳跃的高度等。 -
WallJumpArea
WallJumpArea是一个基本的训练单元,主要有以下物体: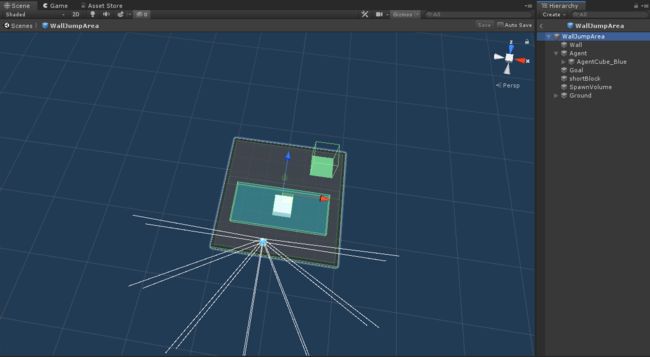
这里面的构成和PushBlock里的很相似,没什么太难的点。主要说一下
SpawnVolume,这个对象在运行的时候就令它SetActive(false)了。那为什么还需要这个对象呢?其实是在Agent的脚本里,利用了该对象的Bounds,即控制大白块的位置是随机产生在该区域里的。其他的物体没什么好说的,下面我们直接进入代码环节。
五、代码分析
其余代码都比较简单,我们主要来研究一下WallJumpAgent.cs脚本。
Agent初始化
using System.Collections;
using UnityEngine;
using MLAgents;
using Barracuda;
using MLAgents.Sensors;
public class WallJumpAgent : Agent
{
//该值范围为[0,5],控制墙体高度以及设置不同的Brain
int m_Configuration;
//当墙体高度为0时,采用此Brain
public NNModel noWallBrain;
//当墙体高度为1时,采用此Brain(实际上与NoWallBrain是一样的)
public NNModel smallWallBrain;
//当墙体高度大于1时,采用此Brain
public NNModel bigWallBrain;
public GameObject ground;//地面,变换地面材质用
public GameObject spawnArea;//大白块随机生成区域
Bounds m_SpawnAreaBounds;//区域的Bounds
public GameObject goal;//目标区域
public GameObject shortBlock;//大白块
public GameObject wall;//墙体
Rigidbody m_ShortBlockRb;//大白块的刚体
Rigidbody m_AgentRb;//小蓝的刚体
Material m_GroundMaterial;
Renderer m_GroundRenderer;
WallJumpSettings m_WallJumpSettings;//小蓝的速度、跳跃高度等设置
public float jumpingTime;//跳起空中时间
public float fallingForce;//小蓝在空中时下降时所受向下的力
//判断小蓝是否在落在地上、墙上或大白块上
public Collider[] hitGroundColliders = new Collider[3];
Vector3 m_JumpTargetPos;//跳跃目标位置
Vector3 m_JumpStartingPos;//起跳位置
///
/// 初始化Agent
///
public override void InitializeAgent()
{
m_WallJumpSettings = FindObjectOfType();//获取全局设定
m_Configuration = Random.Range(0, 5);//随机产生墙面高度
m_AgentRb = GetComponent();//获得小蓝的刚体
m_ShortBlockRb = shortBlock.GetComponent();//获得大白的刚体
m_SpawnAreaBounds = spawnArea.GetComponent().bounds;//获得大白随机产生的区域范围
m_GroundRenderer = ground.GetComponent();
m_GroundMaterial = m_GroundRenderer.material;//获得地面的材质,以备后面改变地面材质
spawnArea.SetActive(false);
}
}
初始化内容都比较简单,注意第一个变量m_Configuration,该变量只标识了墙的高度应该为多少,但并不是指定墙的高度是几,例如m_Configuration=1时,实际墙的高度会是4而不是1,该值的使用一会儿在ConfigureAgent(int config)方法中讲解。下面我们来看Agent收集的环境观测值。
环境观测值收集
在第三章环境训练参数中,我们知道了本示例小蓝除了采用了14条射线来收集射线监测数据外,还需要采集自己的世界坐标以及是否接触地面的信息,这两种信息在CollectObservations(Vector sensor)方法中进行收集。
///
/// 收集环境中其他数据
///
///
public override void CollectObservations(VectorSensor sensor)
{
var agentPos = m_AgentRb.position - ground.transform.position;
//小蓝相对于地面中心的位置,除以20是为了让其位置x、y、z值归一化
sensor.AddObservation(agentPos / 20f);
//判断小蓝是否落地
sensor.AddObservation(DoGroundCheck(true) ? 1 : 0);
}
///
/// 检测是否落地
///
/// 墙的高度是否是低(<=4)
/// true为落地,否则为false
public bool DoGroundCheck(bool smallCheck)
{
if (!smallCheck)
{//4<墙高度<=8
hitGroundColliders = new Collider[3];
var o = gameObject;
//无GC的相交盒检测,可采集与相交盒碰撞的碰撞体Collider[]
//此处赋值给hitGroundColliders
Physics.OverlapBoxNonAlloc(
o.transform.position + new Vector3(0, -0.05f, 0),
new Vector3(0.95f / 2f, 0.5f, 0.95f / 2f),
hitGroundColliders,
o.transform.rotation);
var grounded = false;
foreach (var col in hitGroundColliders)
{//遍历与碰撞盒产生碰撞的物体
if (col != null && col.transform != transform &&
(col.CompareTag("walkableSurface") ||
col.CompareTag("block") ||
col.CompareTag("wall")))
{
//若碰撞的物体为地面、大白块或墙体,则判断小蓝已落地
grounded = true; //then we're grounded
break;
}
}
return grounded;
}
else
{//0<=墙高度<=4
RaycastHit hit;
//若墙的高度较低,则只需要向下发出长度为1的射线来检测小蓝是否落地
Physics.Raycast(transform.position + new Vector3(0, -0.05f, 0), -Vector3.up, out hit,
1f);
if (hit.collider != null &&
(hit.collider.CompareTag("walkableSurface") ||
hit.collider.CompareTag("block") ||
hit.collider.CompareTag("wall"))
&& hit.normal.y > 0.95f)
{
return true;
}
return false;
}
}
此处代码中,需要注意DoGroundCheck(bool smallCheck)这个方法,该方法除了在收集观测值时使用,还在其他3处地方分别使用。
首先该方法是为了检测小蓝是否落地,是则返回true,否则返回false。然后其分别处理了墙面高和低的两种情况:若墙面较高,则采用无GC的相交盒来检测小蓝的碰撞状态;若墙面较低,则直接向下发射射线来检测小蓝是否落地。
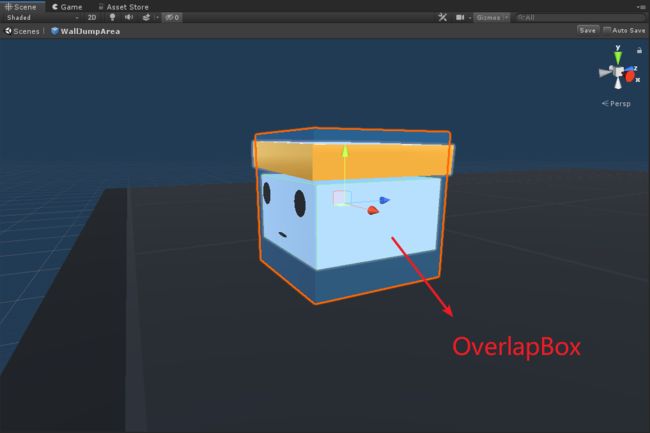
Physics.OverlapBoxNonAlloc()则是相交盒检测方法,在上一篇“ML-Agents(八)PushBlock”中介绍了Physics.CheckBox(),该方法与CheckBox()不同的是,CheckBox只会返回bool来判断是否产生碰撞,而OverlapBox()不仅可以返回bool来判断是否产生碰撞,而且可以将产生碰撞的Colliders获取到。
如下图,我将小蓝材质改透明,其中白色的方块则是代码中Physics.OverlapBoxNonAlloc()方法产生的相交盒。Physics.OverlapXXXNonAlloc()对应无GC的方式,这里XXX也可以是Sphere和Capsule。
Agent动作反馈
///
/// Agent动作
///
///
public override void AgentAction(float[] vectorAction)
{
MoveAgent(vectorAction);//小蓝移动
if ((!Physics.Raycast(m_AgentRb.position, Vector3.down, 20))
|| (!Physics.Raycast(m_ShortBlockRb.position, Vector3.down, 20)))
{//若小蓝落下平台或大白块落下平台
SetReward(-1f);//惩罚1
Done();//本次训练结束,并重置agent
ResetBlock(m_ShortBlockRb);//重置大白块位置、速度等
//设置地面颜色为红色
StartCoroutine(
GoalScoredSwapGroundMaterial(m_WallJumpSettings.failMaterial, .5f));
}
}
///
/// Agent移动
///
///
public void MoveAgent(float[] act)
{
AddReward(-0.0005f);//每一步-0.0005
//判断小蓝是否在地面上,若在地面上则移动速度相应要快一些,在空中的话移动速度要减半
var smallGrounded = DoGroundCheck(true);//墙低情况
var largeGrounded = DoGroundCheck(false);//墙高情况
var dirToGo = Vector3.zero;
var rotateDir = Vector3.zero;
var dirToGoForwardAction = (int)act[0];//前后移动
var rotateDirAction = (int)act[1];//左右旋转
var dirToGoSideAction = (int)act[2];//左右移动
var jumpAction = (int)act[3];//跳跃
//前后移动
if (dirToGoForwardAction == 1)
dirToGo = (largeGrounded ? 1f : 0.5f) * 1f * transform.forward;
else if (dirToGoForwardAction == 2)
dirToGo = (largeGrounded ? 1f : 0.5f) * -1f * transform.forward;
//左右旋转
if (rotateDirAction == 1)
rotateDir = transform.up * -1f;
else if (rotateDirAction == 2)
rotateDir = transform.up * 1f;
//左右平移
if (dirToGoSideAction == 1)
dirToGo = (largeGrounded ? 1f : 0.5f) * -0.6f * transform.right;
else if (dirToGoSideAction == 2)
dirToGo = (largeGrounded ? 1f : 0.5f) * 0.6f * transform.right;
//跳跃
if (jumpAction == 1)
if ((jumpingTime <= 0f) && smallGrounded)
{//判断小蓝是否在地上且jumpingTime<=0,初始化起跳变量
Jump();
}
transform.Rotate(rotateDir, Time.fixedDeltaTime * 300f);//旋转
m_AgentRb.AddForce(dirToGo * m_WallJumpSettings.agentRunSpeed,
ForceMode.VelocityChange);//前后左右移动
if (jumpingTime > 0f)
{//起跳条件满足
m_JumpTargetPos =
new Vector3(m_AgentRb.position.x,
m_JumpStartingPos.y + m_WallJumpSettings.agentJumpHeight,
m_AgentRb.position.z) + dirToGo;//计算跳跃后控制位置
//使得小蓝跳到计算后的位置m_JumpTargetPos,并限制其速度
MoveTowards(m_JumpTargetPos, m_AgentRb, m_WallJumpSettings.agentJumpVelocity,
m_WallJumpSettings.agentJumpVelocityMaxChange);
}
if (!(jumpingTime > 0f) && !largeGrounded)
{//判断小蓝处于空中,给小蓝施加向下的力使其下落
m_AgentRb.AddForce(
Vector3.down * fallingForce, ForceMode.Acceleration);
}
jumpingTime -= Time.fixedDeltaTime;
}
///
/// 重置大白块
///
///
void ResetBlock(Rigidbody blockRb)
{
//重置大白块的位置
blockRb.transform.position = GetRandomSpawnPos();
blockRb.velocity = Vector3.zero;//速度置零
blockRb.angularVelocity = Vector3.zero;//角速度置零
}
///
/// 改变地面材质颜色
///
/// 这里的代码虽长,但是都比较简单,属于一看就懂系列,但是有一个点可以注意一下,即此处小蓝起跳以及下落的代码处理过程,感觉和我见过处理跳跃的方式有一些不同。
Agent重置
///
/// Agent重置
///
public override void AgentReset()
{
ResetBlock(m_ShortBlockRb);//重置大白块
//重置小蓝位置
transform.localPosition = new Vector3(
18 * (Random.value - 0.5f), 1, -12);
m_Configuration = Random.Range(0, 5);//重置墙体高度以及选用的Brain
m_AgentRb.velocity = default(Vector3);//小蓝速度置零
}
///
/// 检测小蓝是否到达目标区域
///
///
void OnTriggerStay(Collider col)
{
if (col.gameObject.CompareTag("goal") && DoGroundCheck(true))
{//若小蓝到目标区域,且在地面上
SetReward(1f);//奖励1
Done();//结束此次训练
//使地面置为绿色
StartCoroutine(
GoalScoredSwapGroundMaterial(m_WallJumpSettings.goalScoredMaterial, 2));
}
}
重置Agent的代码,一部分实际上是在Unity的方法OnTriggerStay(Collider col)中实现的,因为目标区域其实也是有碰撞体的,因此若小蓝Stay在目标区域,则会触发此函数。
到此为止,我们还没有看到此示例是如何使用两个Brain来回切换使用的,下面我们就来看一下这一部分代码是如何实现的。
其他
void FixedUpdate()
{
if (m_Configuration != -1)
{
//设置agent的Brain
ConfigureAgent(m_Configuration);
//标志位置位
m_Configuration = -1;
}
}
///
/// 设置Agent的Brain,墙的高低来决定不同的Brain
///
///
/// 如果为0:No wall + noWallBrain
/// 如果为1:Samll Wall + samllWallBrain
/// 其他:Tall wall + bigWallBrain
///
void ConfigureAgent(int config)
{
var localScale = wall.transform.localScale;//墙的比例大小
if (config == 0)
{//如果m_Configuration==0,墙高度为0
localScale = new Vector3(
localScale.x,
Academy.Instance.FloatProperties.GetPropertyWithDefault("no_wall_height", 0),
localScale.z);
wall.transform.localScale = localScale;
//设置agent的Model
GiveModel("SmallWallJump", noWallBrain);
}
else if (config == 1)
{//如果m_Configuration==1
localScale = new Vector3(
localScale.x,
Academy.Instance.FloatProperties.GetPropertyWithDefault("small_wall_height", 4),
localScale.z);
wall.transform.localScale = localScale;
GiveModel("SmallWallJump", smallWallBrain);
}
else
{//如果m_Configuration>1
//若开始训练时,此处的min和max值取决于课程配置值
var min = Academy.Instance.FloatProperties.GetPropertyWithDefault("big_wall_min_height", 8);
var max = Academy.Instance.FloatProperties.GetPropertyWithDefault("big_wall_max_height", 8);
var height = min + Random.value * (max - min);
localScale = new Vector3(
localScale.x,
height,
localScale.z);
wall.transform.localScale = localScale;
GiveModel("BigWallJump", bigWallBrain);
}
}
由以上代码可以看出,其实现是在FixedUpdate()中,实时判断m_Configuration的值来改变agent不同的Brain,m_Configuration会在训练一开始以及AgentReset的时候随机重置。
此外,之前已经讲过,Academy.Instance.FloatProperties.GetPropertyWithDefault(string key, float defaultValue)这个方法的第二个参数defaultValue是默认值,若key没读取到,则采用输入的默认值。因此在该示例运行的时候,你会发现墙的高度只有0、4、8这是三个值,但是如果开始训练后,该方法中的key就会与之前课程配置文件中的值开始对应。

即在SmallWallJump的时候,墙的高度从1.5->2.0->2.5->4.0;在BigWallJump时,墙的高度则一开始会在0-4随机,然后在4-7随机,然后在6-8随机,最后高度固定在8。从此也可以看出课程训练从易到难的特点。
六、训练
训练配置参数
Wall Jump的课程训练配置已经在上面第二章讲解过了,下面我们来看一下Wall Jump的训练配置:
trainer_config.yaml
SmallWallJump:
max_steps: 5e6
batch_size: 128
buffer_size: 2048
beta: 5.0e-3
hidden_units: 256
summary_freq: 20000
time_horizon: 128
num_layers: 2
normalize: false
BigWallJump:
max_steps: 2e7
batch_size: 128
buffer_size: 2048
beta: 5.0e-3
hidden_units: 256
summary_freq: 20000
time_horizon: 128
num_layers: 2
normalize: false
首先因为要训练两个Model,分别对应SmallWallJump和BigWallJump,因此在配置文件中对应的是两个部分。可以看出Small的max_steps比Big的更小,也好理解,简单的任务训练快,难的任务需要训练步数应该较多。
其他的属性在前几篇都已经分析过,所以不再赘述,这里有一个normalize属性,其作用是是否对输入的矢量观测值(vector observation)进行规范化处理。在之前的内容我们知道,规范化对于复杂的连续控制(continuous control)问题很有用,但对于较简单的离散控制(discrete control)可能反而有害。而且我们在代码中已经对小蓝位置做过规范化处理,因此这里使其变为false。
开始训练
cd到ml-agents目录,并输入一下命令:
mlagents-learn config/trainer_config.yaml --curriculum=config/curricula/wall_jump.yaml --run-id=walljump
开始训练,一开始会发现失败的情况更多,如下图:

上面红色闪烁则为失败的单元,同时我们观察Console会发现,SmallWallJump和BigWallJump会随机穿插进行训练,如下图:
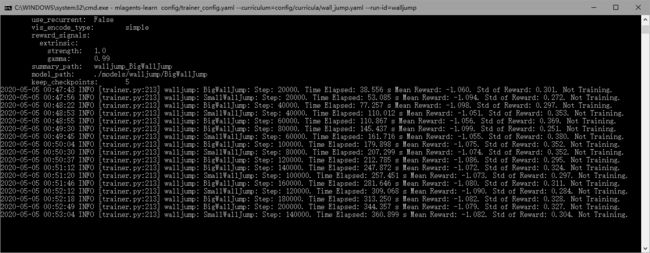
训练了一晚上,发现没训练成功。。。。。摔!

由图可以看到已经训练9个小时了,但平均收益还是-1.1左右,在Unity中也是失败的多,没有什么改观。
其实这期间我又做了许多次尝试,包括修改源码之类的,但是都没有训练成功。于是我最终从git上又拉取了最新版的ml-agents(release_1),并重新新建了一个Anaconda训练环境(具体可参考Unity ML-Agents v0.15.0(一)环境部署与试运行),然后开始训练,终于得到了比较好的训练效果:

这才是训练了40万步左右的结果,相比之前的训练效果好了不止N倍。其实我现在还没搞清楚为什么一开始的版本(0.15.0)训练失败。。。
除此之外,最新版release_1里的文档少了很多,包括课程训练的简介都没有了,大家要是想看英文原版,还是要选0.15.1之前版本的doc才能看到。
OK,这次训练结果就没有问题了,相应的Tensorboard如下:
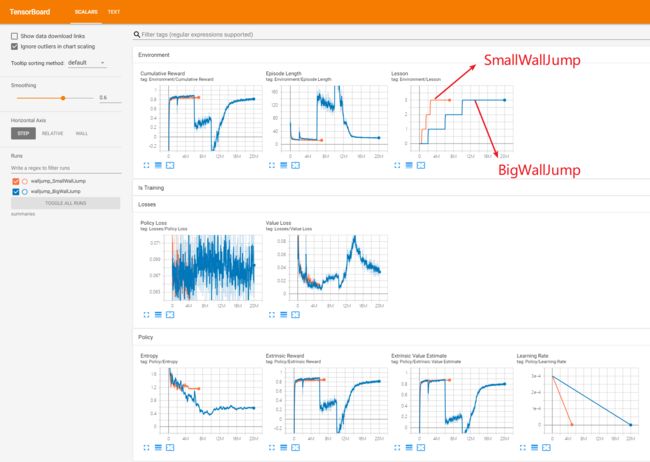
图中橘黄色线的是SmallWallJump的训练数据,蓝色线是BigWallJump的训练数据,在Lesson图表有明显的阶梯状,代表各个课程的开始。
我们再以蓝色线BigWallJump训练数据为例,在Cumulative Reward图标里,可以看出每次课程难度的增加,会使得改变时的累计奖励骤减,但是慢慢会上升,最终的基准平均奖励也和官方的数据一致,大概在0.8左右。
我们把训练好的模型放到Unity中试验一下:
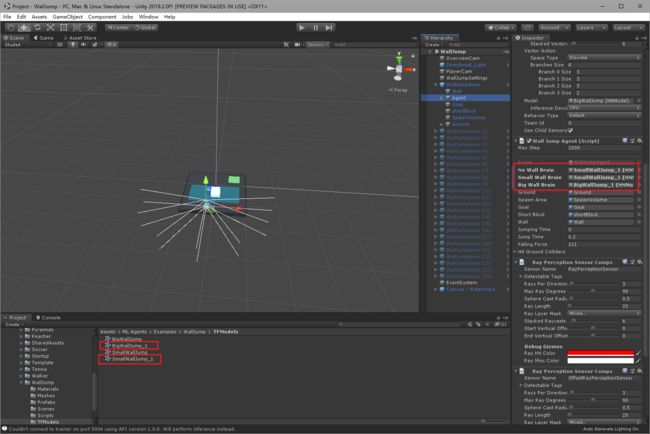
方便起见直接用一个来测试即可。

OK,发现训练的模型也没有问题。
七、总结
这个示例我们主要学习了如何使用Curriculum Learning进行训练,其中关于射线传感器的数据采集内容在ML-Agents(八)PushBlock已有讲述,不熟悉的亲可以回看。本篇文章就此结束,欢迎大家留言交流~
写文不易~因此做以下申明:
1.博客中标注原创的文章,版权归原作者 煦阳(本博博主) 所有;
2.未经原作者允许不得转载本文内容,否则将视为侵权;
3.转载或者引用本文内容请注明来源及原作者;
4.对于不遵守此声明或者其他违法使用本文内容者,本人依法保留追究权等。