大数据ETL实践探索(3)---- 大数据ETL利器之pyspark
文章大纲
- 大数据ETL 系列文章简介
- pyspark Dataframe ETL
- spark dataframe 数据导入Elasticsearch
- dataframe 及环境初始化
- 清洗及写入数据到Elastic search
- spark SQL
- Dataframe 操作
- 加载大文件
- 遍历
- 增
- 删
- 改
- 查
- 空值处理
- 更改dataframe 列 类型
- where
- join 及聚集函数
- 列式数据存储格式parquet
- 参考
大数据ETL 系列文章简介
本系列文章主要针对ETL大数据处理这一典型场景,基于python语言使用Oracle、aws、Elastic search 、Spark 相关组件进行一些基本的数据导入导出实战,如:
- oracle使用数据泵impdp进行导入操作。
- aws使用awscli进行上传下载操作。
- 本地文件上传至aws es
- spark dataframe录入ElasticSearch
等典型数据ETL功能的探索。
系列文章:
1.大数据ETL实践探索(1)---- python 与oracle数据库导入导出
2.大数据ETL实践探索(2)---- python 与aws 交互
3.大数据ETL实践探索(3)---- pyspark 之大数据ETL利器
4.大数据ETL实践探索(4)---- 之 搜索神器elastic search
5.使用python对数据库,云平台,oracle,aws,es导入导出实战
6.aws ec2 配置ftp----使用vsftp
7.浅谈pandas,pyspark 的大数据ETL实践经验
pyspark Dataframe ETL
本部分内容主要在 系列文章7 :浅谈pandas,pyspark 的大数据ETL实践经验 上已有介绍 ,不用多说
spark dataframe 数据导入Elasticsearch
下面重点介绍 使用spark 作为工具和其他组件进行交互(数据导入导出)的方法
ES 对于spark 的相关支持做的非常好,https://www.elastic.co/guide/en/elasticsearch/hadoop/2.4/spark.html
在官网的文档中基本上说的比较清楚,但是大部分代码都是java 的,所以下面我们给出python 的demo 代码
dataframe 及环境初始化
初始化, spark 第三方网站下载包:elasticsearch-spark-20_2.11-6.1.1.jar
http://spark.apache.org/third-party-projects.html
import sys
import os
print(os.getcwd())
# 加载包得放在这里
os.environ['PYSPARK_SUBMIT_ARGS'] = '--jars elasticsearch-spark-20_2.11-6.1.1.jar pyspark-shell'
import os
from pyspark.sql import SparkSession
from pyspark import SparkConf
from pyspark.sql.types import *
from pyspark.sql import functions as F
from pyspark.storagelevel import StorageLevel
import json
import math
import numbers
import numpy as np
import pandas as pd
os.environ["PYSPARK_PYTHON"] = "/home/hadoop/anaconda/envs/playground_py36/bin/python"
try:
spark.stop()
print("Stopped a SparkSession")
except Exception as e:
print("No existing SparkSession")
SPARK_DRIVER_MEMORY= "10G"
SPARK_DRIVER_CORE = "5"
SPARK_EXECUTOR_MEMORY= "3G"
SPARK_EXECUTOR_CORE = "1"
conf = SparkConf().\
setAppName("insurance_dataschema").\
setMaster('yarn-client').\
set('spark.executor.cores', SPARK_EXECUTOR_CORE).\
set('spark.executor.memory', SPARK_EXECUTOR_MEMORY).\
set('spark.driver.cores', SPARK_DRIVER_CORE).\
set('spark.driver.memory', SPARK_DRIVER_MEMORY).\
set('spark.driver.maxResultSize', '0').\
set("es.index.auto.create", "true").\
set("es.resource", "tempindex/temptype").\
set("spark.jars", "elasticsearch-hadoop-6.1.1.zip") # set the spark.jars
spark = SparkSession.builder.\
config(conf=conf).\
getOrCreate()
sc=spark.sparkContext
hadoop_conf = sc._jsc.hadoopConfiguration()
hadoop_conf.set("mapreduce.fileoutputcommitter.algorithm.version", "2")
清洗及写入数据到Elastic search
- 数据加载
#数据加载
df = (spark
.read
.option("header","true")
.option("multiLine", "true")
.csv('EXPORT.csv')
.cache()
)
print(df.count())
#
- 数据清洗,增加一列,或者针对某一列进行udf 转换
'''
#加一列用户名,如果是xx数据则为xx
'''
from pyspark.sql.functions import udf
from pyspark.sql import functions
df = df.withColumn('customer',functions.lit("腾讯用户"))
- 使用udf 清洗时间格式及数字格式
#udf 清洗时间
#清洗日期格式字段
from dateutil import parser
def clean_date(str_date):
try:
if str_date:
d = parser.parse(str_date)
return d.strftime('%Y-%m-%d')
else:
return None
except Exception as e:
return None
func_udf_clean_date = udf(clean_date, StringType())
def is_number(s):
try:
float(s)
return True
except ValueError:
pass
return False
def clean_number(str_number):
try:
if str_number:
if is_number(str_number):
return str_number
else:
None
else:
return None
except Exception as e:
return None
func_udf_clean_number = udf(clean_number, StringType())
column_Date = [
"DATE_FROM",
"DATE_TO",
]
for column in column_Date:
df=df.withColumn(column, func_udf_clean_date(df[column]))
df.select(column_Date).show(2)
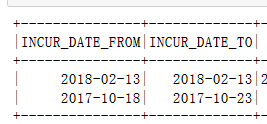
#数据写入
df.write.format("org.elasticsearch.spark.sql").\
option("es.nodes", "IP").\
option("es.port","9002").\
mode("Overwrite").\
save("is/doc")
spark SQL
SPARK 的spark 写起来对于 经常写sql 的人来说还是很友好的
一份代码样例如下,参考:update a dataframe column with new values
data1 = [
(1, "a"),
(2, "b"),
(3, "c")
]
df1 = spark.createDataFrame(data1, ["id", "value"])
data2 = [
(1, "x"),
(2, "y")
]
df2 = spark.createDataFrame(data2, ["id", "value"])
df1.registerTempTable('df1')
df2.registerTempTable('df2')
query = """SELECT l.id,
CASE WHEN r.value IS NOT NULL THEN r.value ELSE l.value END AS value
FROM df1 l LEFT JOIN df2 r ON l.id = r.id"""
spark.sql(query.replace("\n", "")).show()
# 样例输出
#+---+-----+
#| id|value|
#+---+-----+
#| 1| x|
#| 3| c|
#| 2| y|
#+---+-----+
spark SQL 中,语句包含中文列名怎么处理呢,以下给出一个样例:
query = """SELECT df1.`体检ID`,df1.`体检编号`,df1.`性别`,df1.`年龄`,df1.`检查日期`,"""+str_sql_column+"""
CASE WHEN df2.`结果` IS NOT NULL THEN df2.`结果` ELSE df1."""+'`'+jieguo+'`'+""" END AS """+'`'+jieguo+'`'+""" ,
CASE WHEN df2.`异常与否` IS NOT NULL THEN df2.`异常与否` ELSE df1."""+'`'+yichangyufou+'`'+""" END AS """+'`'+yichangyufou+'`'+"""
FROM df1 LEFT JOIN df2 ON df1.`体检ID` = df2.`体检ID`"""
Dataframe 操作
http://spark.apache.org/docs/latest/api/python/pyspark.sql.html
加载大文件
遍历
按行遍历
# DataFrame转list
rows=df.collect()
cols=df.columns
cols_len=len(cols)
all_list=[]
for row in rows:
'do your job'
这样遍历获取到的 row 是
http://spark.apache.org/docs/latest/api/python/pyspark.sql.html#pyspark.sql.Row
增
删
改
查
空值处理
dataframe 的空值可以直接使用 fillna 函数进行处理
Replace null values, alias for na.fill(). DataFrame.fillna() and DataFrameNaFunctions.fill() are aliases of each other.
# 计算dataframe 每一列缺失值的百分比
from pyspark.sql import functions as F
df.agg(*[(1-(F.count(c) /F.count('*'))).alias(c+'_missing') for c in df.columns]).show()
输出:
+----------+---------------+------------------------+
|id_missing|disease_missing| label_missing|
+----------+---------------+------------------------+
| 0.0| 0.0| 0.0|
+----------+---------------+------------------------+
更改dataframe 列 类型
# 可以这么写
from pyspark.sql.types import DoubleType
changedTypedf = joindf.withColumn("label", joindf["show"].cast(DoubleType()))
# 或者这么写:
changedTypedf = joindf.withColumn("label", joindf["show"].cast("double"))
至于每种类型怎么对应
where canonical string names (other variations can be supported as well) correspond to simpleString value. So for atomic types:
from pyspark.sql import types
for t in ['BinaryType', 'BooleanType', 'ByteType', 'DateType',
'DecimalType', 'DoubleType', 'FloatType', 'IntegerType',
'LongType', 'ShortType', 'StringType', 'TimestampType']:
print(f"{t}: {getattr(types, t)().simpleString()}")
BinaryType: binary
BooleanType: boolean
ByteType: tinyint
DateType: date
DecimalType: decimal(10,0)
DoubleType: double
FloatType: float
IntegerType: int
LongType: bigint
ShortType: smallint
StringType: string
TimestampType: timestamp
说实话,spark 的文档 cast api 的介绍 写的还没人家这个回答好
参考:https://stackoverflow.com/questions/32284620/how-to-change-a-dataframe-column-from-string-type-to-double-type-in-pyspark
where
like 操作怎么写都不对, 原来是对象的方法
like(other)
SQL like expression. Returns a boolean Column based on a SQL LIKE match.
Parameters: other – a SQL LIKE pattern
See rlike() for a regex version
>>>
df.filter(df.name.like('Al%')).collect()
[Row(age=2, name='Alice')]
join 及聚集函数
join:
groupBy:https://spark.apache.org/docs/latest/api/python/pyspark.sql.html?highlight=groupby#pyspark.sql.DataFrame.groupby
df.groupBy('name').agg({'age': 'mean'})
下面给出一个 简单使用聚集函数统计 的样例代码:
# 以下代码实现,和代码表碰撞获取代码中文名称,并统计不同项目的占比功能
门诊住院分布_df = df.groupby("TYPE"
).agg(F.count(df.OID).alias('个数'))
门诊住院分布_df =门诊住院分布_df.orderBy(F.desc("个数")
).join(code_lang_df,code_lang_df.SCMA_OID == 门诊住院分布_df.TYPE
).select(门诊住院分布_df.TYPE,门诊住院分布_df.个数,code_lang_df.CODE_DESC)
门诊住院分布_pdf = 门诊住院分布_df.toPandas()
门诊住院分布_pdf['比例'] = 门诊住院分布_pdf['个数']/门诊住院分布_pdf['个数'].sum()
#取前十个
门诊住院分布_pdf[0:10]
列式数据存储格式parquet
parquet 是针对列式数据存储的一种申请的压缩格式,百万级的数据用spark 加载成pyspark 的dataframe 然后在进行count 操作基本上是秒出结果
读写 demo code
#直接用pyspark dataframe写parquet数据(overwrite模式)
df.write.mode("overwrite").parquet("data.parquet")
# 读取parquet 到pyspark dataframe,并统计数据条目
DF = spark.read.parquet("data.parquet")
DF.count()
Parquet 用于 Spark SQL 时表现非常出色。它不仅提供了更高的压缩率,还允许通过已选定的列和低级别的读取器过滤器来只读取感兴趣的记录。因此,如果需要多次传递数据,那么花费一些时间编码现有的平面文件可能是值得的。
参考
parquet
https://www.ibm.com/developerworks/cn/analytics/blog/5-reasons-to-choose-parquet-for-spark-sql/index.html
parquet 实战应用
http://www.cnblogs.com/piaolingzxh/p/5469964.html