RelationNet 笔记
前言
1.本文重点是object relation module,尽量用较少篇幅表达清楚论文算法,其他一些不影响理解算法的东西不做赘述
2.博客主要是学习记录,为了更好理解和方便以后查看,当然如果能为别人提供帮助就更好了,如果有不对的地方请指正(论文中的链接是我经过大量搜索,个人认为讲解最清楚的参考)
论文链接
代码链接
计算机视觉中的attention机制参考:csdn、微信文章
创新点
引入attention机制,提出object relation module,来刻画不同object之间的图像特征关系和位置关系,并用在全连接层后和nms中,实现端到端并提升检测效果
问题引出
目前的检测算法基本上都是独立的检测各个object,如果模型能够学到不同object之间的关系会对检测效果有所提升,RelationNet 就是通过attention机制来刻画object之间的关系来优化检测效果
RelationNet
RelationNet 借鉴Attention Is All You Need,提出object relation module,object relation module用在全连接层后和nms模块(基于Faster R-CNN系列),如下图所示
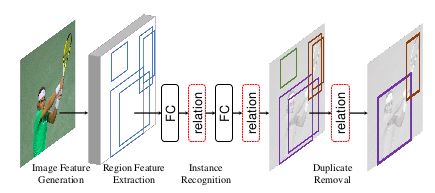
1.object relation module
1.1 算法流程

其中 f A n f_A^n fAn、 f G n f_G^n fGn分别是图像特征和位置特征(可以认为是roi和(x,y,h,w)); N r N_r Nr、 d k d_k dk、 d g d_g dg是超参数, N r N_r Nr是relation的个数,也就是object的数量减一, d k d_k dk、 d g d_g dg默认64; W K r W_K^r WKr、 W Q r W_Q^r WQr、 W G r W_G^r WGr、 W V r W_V^r WVr都是网络学习的参数,前三个是全连接层的参数,最后一个可以看做一个线性变换,源码中用1x1卷积实现; w G m n , r w_G^{mn,r} wGmn,r、 w A m n , r w_A^{mn,r} wAmn,r分别是位置特征权重和图像特征权重, w m n , r w^{mn,r} wmn,r是不同object之间关系的权重,包括位置特征权重和图像特征权重; f R n f_R^n fRn(n)是另一个object和第n个object之间通过attention机制获得的关系特征
上图中算法可以简单用下图来表示,箭头上面是对应公式,下面是用到的参数
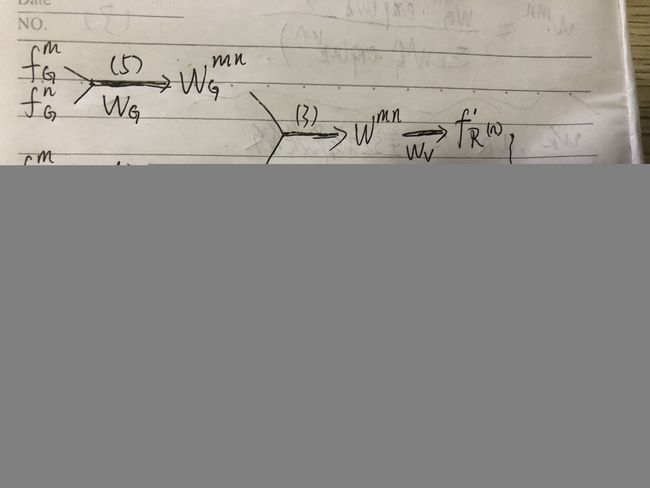
概括一下算法流程:首先根据图形特征 f A n f_A^n fAn、位置特征 f G n f_G^n fGn和参数 W G W_G WG用公式(5)算出位置特征权重 w G m n w_G^{mn} wGmn,以及和参数 W A W_A WA用公式(4)算出图像特征权重 w A m n w_A^{mn} wAmn;然后根据 w G m n w_G^{mn} wGmn、 w A m n w_A^{mn} wAmn用公式(3)计算不同object之间关系的权重 w m n w^{mn} wmn;接着根据 w m n w^{mn} wmn和参数 W V W_V WV用公式(2)计算出关系特征 f R n f_R^n fRn(n);重复上述操作,直到不同object之间的关系特征都计算出来,关系特征 f R n f_R^n fRn(n)和原图像特征 f A n f_A^n fAn用公式(6)计算之后再传递到下一层网络
1.2 算法中的公式
公式按算法顺序给出,分别是(5)、(4)、(3)、(2)、(6)
1.2.1 公式(5)
![]()
E G E_G EG操作主要是将4维的坐标信息embedding成高维的坐标信息(比如默认是64维);值得注意的一点是其中的 f G m f_G^m fGm和 f G n f_G^n fGn是经过坐标变换的,公式如下:
![]()
可以看出坐标变换公式和目标检测算法中的回归目标构造非常相似,最大的不同点在于对x和y做了log操作,原因在于这里要处理的xm与xn、ym与yn之间的距离要比目标检测算法中的距离远,因为目标检测算法中的距离是预测框和roi之间的距离,而这里是不同预测框(或者说是不同roi)之间的距离,因此加上log可以避免数值变化范围过大(此段来自AI之路的博客)
1.2.2 公式(4)
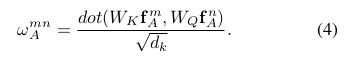
W K W_K WK是全连接层的参数, W K W_K WK f A m f_A^m fAm通过全连接层来实现, W Q W_Q WQ f A n f_A^n fAn同理
1.2.3 公式(3)

从形式上看类似softmax,如果将 w G m n w_G^{mn} wGmn先做log,得到log( w G m n w_G^{mn} wGmn),再将log( w G m n w_G^{mn} wGmn)+ w A m n w_A^{mn} wAmn作为softmax的输入就是公式(3)了
1.2.4 公式(2)
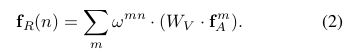
f A m f_A^m fAm就是第m个object的图像特征, W V W_V WV是之前提到的线性变换操作,在代码中用1x1的卷积层实现,公式(2)刻画第n个object和所有object之间的关系特征(relation feature);还有一点要提的是公式(2)借鉴attention is all you need这篇文章中的attention机制,也就是借鉴公式(1):

公式(2)中的 W V W_V WV对应公式(1)中的V,公式(2)中的 w m n w^{mn} wmn对应公式(1)中的softmax()
1.2.5 公式(6)
![]()
第n个object和所有object的关系特征融合之后,再和图像特征相加(每个 f R f_R fR(n)的通道维度是 f A n f_A^n fAn的1/ N r N_r Nr,concat后的维度和 f A n f_A^n fAn相同)
1.3 用图来描述算法
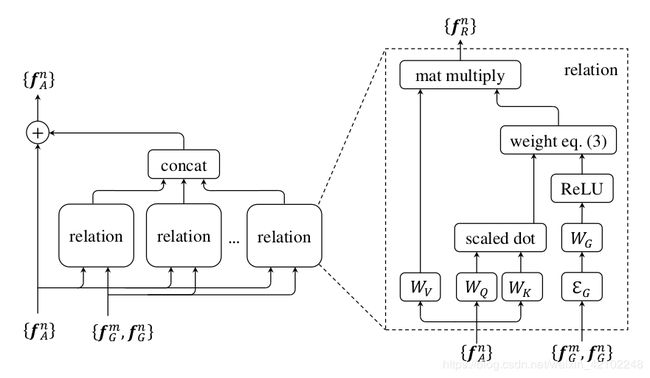
左图对应公式(6),右图对应公式(2)~公式(5)
2.object relation module与目标检测算法的结合
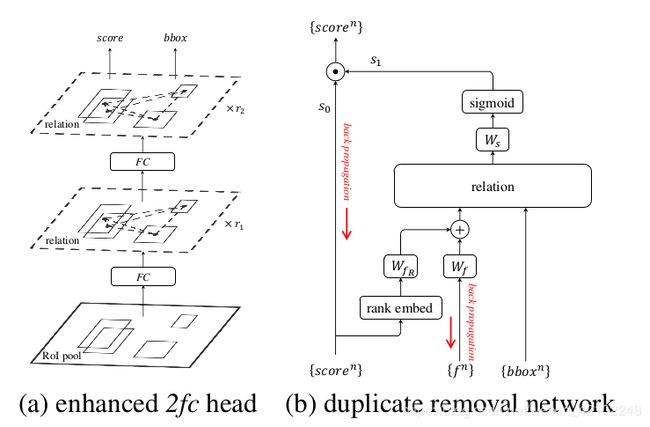
(a)就是将object relation module插入到两个全连接层后面
(b)是插入nms模块。经过nms过滤后,一个gt只留一个bbox,如果把nms看成二分类,那就是只有一个框是对的,其他的框都是错的,这篇论文就将nms当二分类处理,nms输入为score和bbox以及图像特征 f n f^n fn,score排序之后做embedding再经过全连接层,图像特征 f n f^n fn经过全连接层,二者经过全连接层之后融合作为object relation module的输入之一,object relation module的另一个输入是bbox,object relation module输出关系特征再经过一个线性变换,然后作为sigmoid的输入得到分类结果 s 1 s_1 s1, s 1 s_1 s1是二分类的结果(1表示对的;0表示错的,要移除), s 0 s_0 s0是预测框的socre,最后输出就是经过nms之后留下的框
其他
在以往的目标检测算法中,nms不属于网络本身,不能算作真正的end to end,这篇论文将nms纳入end-to-end训练;所以这样一来整体损失函数不仅包含原来的坐标回归和多分类损失函数,还包含nms的二分类损失函数