时序分析(6) -- ARIMA(p,d,q)模型
时序分析(6)
ARIMA(p,d,q)模型
上一篇文章我们探讨了ARIMA模型时序数据进行建模,这一节我们主要讨论ARMA模型的一个非常重要的扩展模型ARIMA。
首先我们介绍ARIMA模型的基本概念:
Autoregressive Integrated Moving Average Models - ARIMA(p, d, q)
我们以前提到过金融时序大多数都不是平稳时序,也就是说其统计特性随着时间的推移而变化,但是通过差分我们有时可以将其变成平稳时序。在前面文章中我们看到了把指数数据变换成收益率后就是平稳过程了;把随机步行序列进行一阶差分以后就变成了白噪声。
ARIMA模型中的参数d就代表我们对原始序列进行差分的次数。
导入python包和数据
如同系列文章前面一样
我们将对四个指数数据进行ARIMA建模,注意:不是对收益率数据建模。
- 国内股票
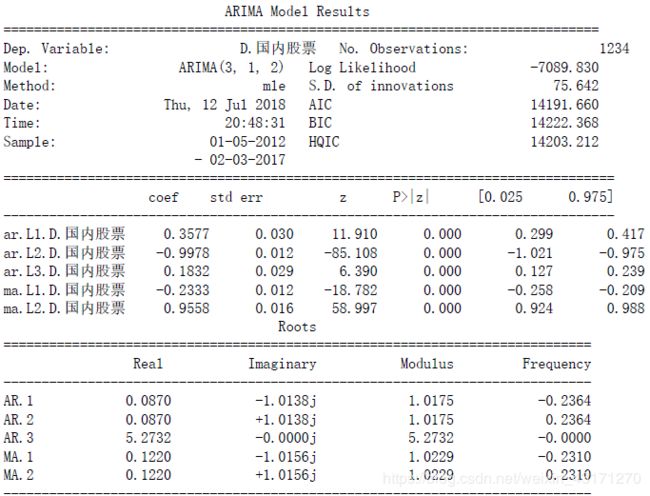
以ARIMA建模, 模型比较准则为AIC,得到阶数为(3,1,2)
best_aic = np.inf
best_order = None
best_mdl_gg = None
Y = indexs_sub['国内股票']
pq_rng = range(5) # [0,1,2,3,4]
d_rng = range(2) # [0,1]
for i in pq_rng:
for d in d_rng:
for j in pq_rng:
try:
tmp_mdl = smt.ARIMA(Y, order=(i,d,j)).fit(method='mle', trend='nc')
tmp_aic = tmp_mdl.aic
if tmp_aic < best_aic:
best_aic = tmp_aic
best_order = (i, d, j)
best_mdl_gg = tmp_mdl
except: continue
print('aic: {:6.5f} | order: {}'.format(best_aic, best_order))
aic: 14191.66013 | order: (3, 1, 2)
得到p,d,q分别为3,1,2,这是符合我们的预期的。
print(best_mdl_gg.summary())
残差Plot
_ = tsplot(best_mdl_gg.resid, lags=30)
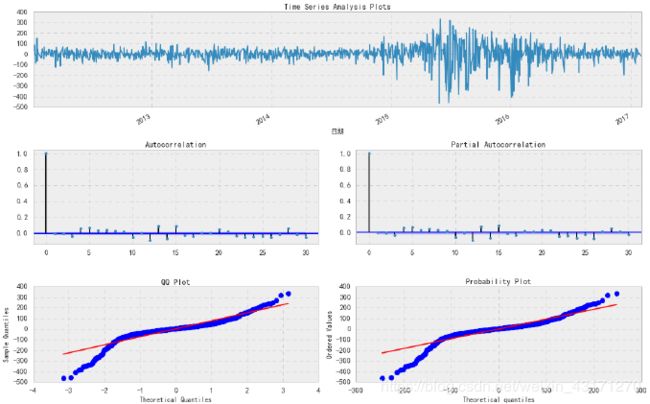
从QQ-plot上看,残差并非正态分布。
以下代码类似
- 香港股票
以ARIMA建模
比较准则为AIC,拟合参数为(3,1,2)
aic: 17054.58001 | order: (3, 1, 2)
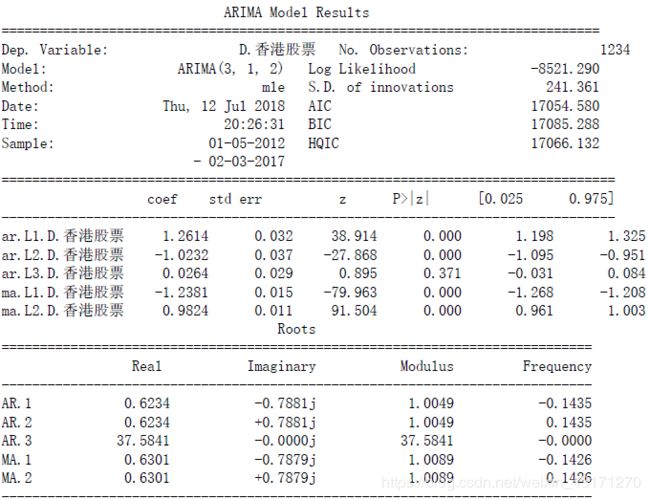
残差Plot
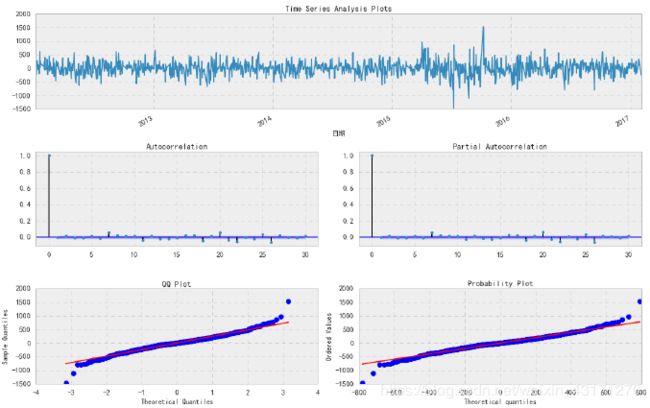
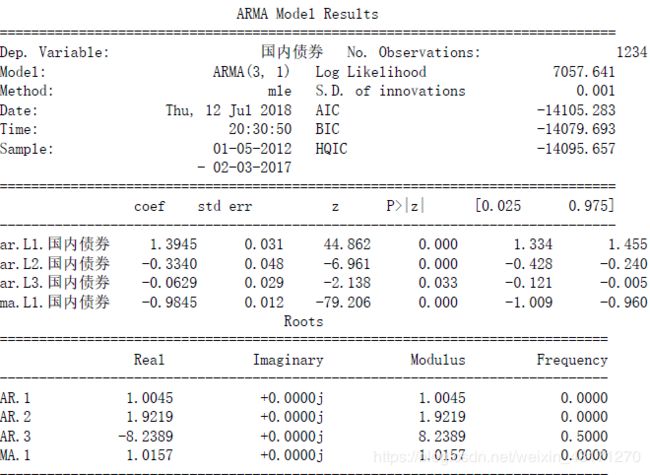
- 国内债劵
以ARIMA建模,比较准则AIC,得到(3,0,1).
aic: -14105.28291 | order: (3, 0, 1)
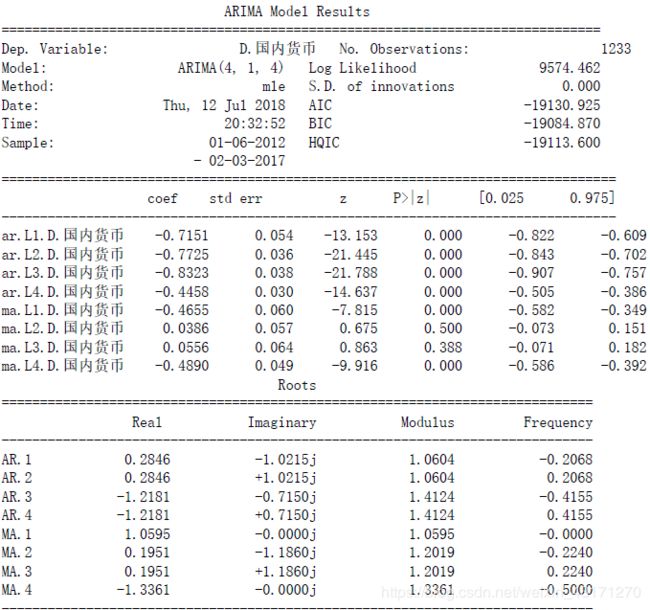
- 国内货币
以ARIMA建模
比较准则AIC,得到(4,1,4).
aic: -19130.92496 | order: (4, 1, 4)
最后,我们尝试对国内股票收益率用ARIMA模型建模。
aic: -6601.86081 | order: (3, 0, 2)
如我们所料,得到了参数(3,0,2)
其实,我们采用了如此多的模型来为时序数据进行建模,最主要的目的是为了能够预测。下面,我们需要评估一下采用ARIMA模型预测数据的效果。
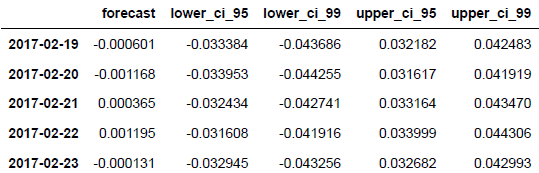
预测国内股票收益率21天数据,并分别估算其95%和99%置信水平。
n_steps = 21
f, err95, ci95 = best_mdl_gg.forecast(steps=n_steps) # 95% CI
_, err99, ci99 = best_mdl_gg.forecast(steps=n_steps, alpha=0.01) # 99% CI
idx = pd.date_range(Y.index[-1], periods=n_steps, freq='D')
fc_95 = pd.DataFrame(np.column_stack([f, ci95]),
index=idx, columns=['forecast', 'lower_ci_95', 'upper_ci_95'])
fc_99 = pd.DataFrame(np.column_stack([ci99]),
index=idx, columns=['lower_ci_99', 'upper_ci_99'])
fc_all = fc_95.combine_first(fc_99)
fc_all.tail()
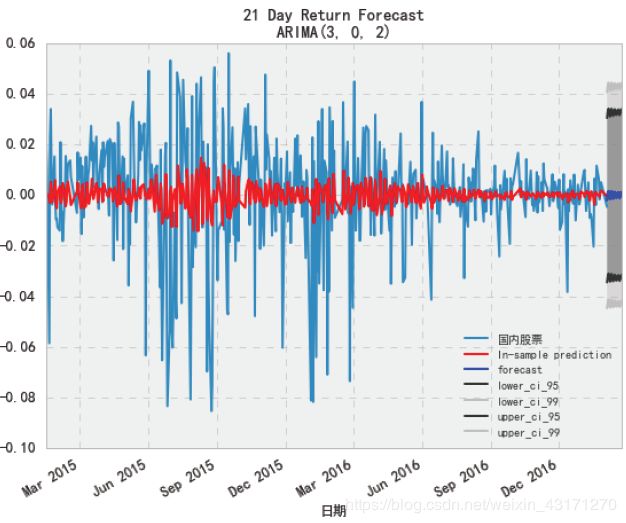
plt.style.use('bmh')
fig = plt.figure(figsize=(9,7))
ax = plt.gca()
ts = indexs_logret[['国内股票']].iloc[-500:].copy()
ts.plot(ax=ax, label='GG Returns')
# in sample prediction
pred = best_mdl_gg.predict(ts.index[0], ts.index[-1])
pred.plot(ax=ax, style='r-', label='In-sample prediction')
styles = ['b-', '0.2', '0.75', '0.2', '0.75']
fc_all.plot(ax=ax, style=styles)
plt.fill_between(fc_all.index, fc_all.lower_ci_95, fc_all.upper_ci_95, color='gray', alpha=0.7)
plt.fill_between(fc_all.index, fc_all.lower_ci_99, fc_all.upper_ci_99, color='gray', alpha=0.2)
plt.title('{} Day Return Forecast\nARIMA{}'.format(n_steps, best_order))
plt.legend(loc='best', fontsize=10)
总结
本文展示了采用Python语言为四个指数时序数据进行ARIMA建模,介绍了ARIMA模型的基本概念,并使用ARIMA模型对四指数数据进行建模其对国内股票收益率的预测进行了评估。