当当网书籍封面爬取
当当网书籍封面爬取
本人小白一枚,才开始接触爬虫,这是第一次进行爬虫试验,爬取了当当网上python相关书籍的封面。至于为什么想到做这个,也是参考了别人的文章啦,没有照搬,主要还是自己的思路。
在当当网输入python,搜索结果有57页,作为小白,首先尝试抓取出一页的封面图片。
在网页界面右击,查看网页源代码,找到代码中的封面图片链接(只看源代码找不出或者说不确定链接在哪的话,可以右击检查,在Elements中鼠标指哪,网页中对应部分就会被标记选中)。以下代码片段包含了其中两本书的图片链接:
上到有编程基础的程序员,下到10岁少年,想入门Python并达到可以开发实际项目的水平,本书是读者*! 本书是一本全面的从入门到实践的Python编程教程,带领读者快速掌握编程基础知识、编写出能解决实际问题的代码并开发复杂项目。 书中内容分为基础篇和实战篇两部分。基础篇介绍基本的编程概念,如列表、字典、类和循环,并指导读者编写整洁且易于理解的代码。另外还介绍了如何让程序能够与用户交互,以及如何在代码运行前进行测试。实战篇介绍如何利用新学到的知识开发功能丰富的项目:2D游戏《外星人入侵》,数据可视化实战,Web应用程序。
¥62.00定价:¥89.00 (6.97折)


本书根据Python专家Mark Lutz的著名培训课程编写而成,是易于掌握和自学的Python语言教程。书中以目前主流的Python 3.X为主,同时兼顾Python 2.X的内容,全面、系统讲解Python语言核心知识,每个知识都会以知识点、思想、示例代码的方式详细展开,由浅入深,循序渐进。同时每章都配有章后习题、编程练习及详尽的解答,并且还配有大量注释、示例和图表,便于你学习新的技能和巩固加深自己的理解。无论你从事哪个领域,本书都为你提供了未来全部Python工作的必备知识。
¥173.00定价:¥219.00 (7.9折)
图片链接所在的位置为:
http://img3m0.ddimg.cn/67/4/24003310-1_b_7.jpg’ alt=’ Python编程 从入门到实践’ />
http://img3m8.ddimg.cn/27/32/25576578-1_b_5.jpg’ src=‘images/model/guan/url_none.png’ alt=’ Python学习手册(原书第5版)’ />
在网页上观察后,进入python开始写代码啦~~
第一页的URL为http://search.dangdang.com/?key=python&act=input&page_index=1
import requests
url=r'http://search.dangdang.com/?key=python&act=input&page_index=1'
response=requests.get(url)
text=response.text
text
得到的 text 即为之前在网页看到的源代码。可以观察出的规律是,图片的链接均在
import re
re.findall("" ,text)
len(re.findall("" ,text))
一页有60本书的信息,匹配出了65项,查看匹配成功的部分,其中多余的5项为:




我们真正需要的那60项可以更准确表示为
fit=re.findall("" ,text)
len(fit)
检测一下列表 fit 有60个元素。
现在 fit 中的元素形如以下两个例子:


还需要进一步提取出 http 开头的链接,同时提取出 alt 后面的书名。创建列表 links 和 names,遍历 fit 中的元素,将提取出的链接和书名添加到列表中。
links=[]
names=[]
for i in fit:
links.append(re.findall("http.*?jpg",i))
name=re.findall("alt.*'",i)
name=re.sub("^alt=' ","",name[0])
name=re.sub("'$","",name)
names.append(name)
可以检查一下,links 和 names 均有60个元素,是预期的结果。接下来就是同时遍历 links 和 names,下载获取每一张图片,以书名保存下来就OK了~编写了如下的代码:
for i in range(len(links)):
print("Downloding the Picture of "+names[i]+" from: "+links[i][0])
pic=requests.get(links[i][0])
file=open(names[i]+".jpg","xb") #一定要事先创建一个文件夹,并一定记得指定为默认工作目录!!!图片将保存到文件夹里。否则,上千张图片将占据你原来的工作目录。。。。。。
file.write(pic.content)
file.close()
我的默认工作目录为桌面,某次调试不小心运行完以上代码,大量图片在电脑桌面疯狂生长。。。。。。所以要记得事先创建好文件夹,将默认工作目录改为这个文件夹呀(真诚的语气)
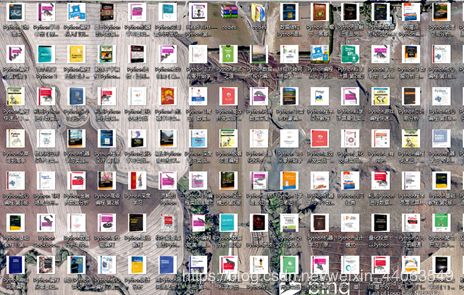
运行代码,我创建的 pic 文件夹里就有60张图片了,按时间排下序,图片的顺序就和网页上一样了。

接下来实现爬取57页的封面图片。首先观察每一页的URL的规律:
http://search.dangdang.com/?key=python&act=input&page_index=1
http://search.dangdang.com/?key=python&act=input&page_index=2
⋮ \vdots ⋮
http://search.dangdang.com/?key=python&act=input&page_index=57
每一页唯一的不同就在于 page_index 后面跟的数字,所以用一个循环遍历每个数字,做一个字符串拼接就可以了。代码中还添加了一个 n,用于做每一页匹配个数的监测。运行后可以看到1至56页匹配个数为60,57页匹配个数为9,与预期结果相符。
links=[]
names=[]
n=[]
print("Loading...")
for i in range(57):
url=r'http://search.dangdang.com/?key=python&act=input&page_index='+str(i+1)
response=requests.get(url)
text=response.text
fit=re.findall("" ,text)
n.append(len(fit))
for i in fit:
links.append(re.findall("http.*?jpg",i))
name=re.findall("alt.*'",i)
name=re.sub("^alt=' ","",name[0])
name=re.sub("'$","",name)
names.append(name)
len(links)
Out[53]: 3369
len(names)
Out[54]: 3369
有3369条书籍信息
共57页的图书链接和书名均已保存在 links 和 names 列表里,接下来根据链接地址下载图片保存的代码和处理一页是一样的,运行一下。
for i in range(len(links)):
print("Downloding the Picture of "+names[i]+" from: "+links[i][0])
pic=requests.get(links[i][0])
file=open(names[i]+".jpg","xb")
file.write(pic.content)
file.close()
似乎运行了以后爬虫就完成了,然而数据多了总会出点问题的。没多久,就出现了第一次报错:
File “
”, line 4, in
file=open(names[i]+".jpg",“xb”)
FileExistsError: [Errno 17] File exists: ‘Python深度学习.jpg’
FileExistsError 的意思是文件已存在错误。因为我打开文件(file=open())时用的是创建写模式(‘x’),即文件不存在则创建,存在则返回异常 FileExistsError,所以书名重复时就会报错。在这里我更改了打开模式,改成覆盖写模式(‘w’),即文件不存在则创建,存在则覆盖原有文件(书名重了按理说封面应该是一样的吧)。关于文件的打开模式,可以参考这里。
file=open(names[i]+".jpg",“xb”)
↓ \downarrow ↓
file=open(names[i]+".jpg",“wb”)
再运行,又出现报错OSError,原因是书名中带有 *,open 时就会报错(页面越往后提取出的书名包含了很多杂乱的内容。。。我还没考虑怎么处理的事,就先这样了)。就简单处理了一下,将 * 替换成空格,就不会报错了。之后调试还发现,’|’,’?’ 也会导致这种报错,还有成对的 ‘:’,均替换成空格。
也就是在运行上一段代码之前,再加上一段:
for i in range(len(names)):
names[i]=re.sub("[\*\|:\?]"," ",names[i])
又一次运行,又有新的报错 FileNotFoundError,按理说改为覆盖写模式是不会出现这种错误的,看了一下导致报错的书名,其中有符号 ‘/’,这个符号会在表示文件路径中出现,比较特殊,所以以某种原因导致了打开文件时出错吧,至于怎么清楚地解释,我还没深究,反正替换成空格就可以继续跑了。。。
File “
”, line 4, in
file=open(names[i]+".jpg",“wb”)
FileNotFoundError: [Errno 2] No such file or directory: ‘Python基础教程 第2版 编程从入门到实践 核心语言开发指南 自学教程基础书籍 程序设计/软件开发教材 代码大全入.jpg’
终于,没有报错了。查看一下,用于监测每一页匹配数量的列表 n 的最后一个数字变成了7(之前调试时是9),links 和 names 的元素个数也从3369变成3367,也就是从调试到现在,网页上 python 相关书目的条数发生了变化。
print(n[56],len(links),len(names))
7 3367 3367
其实,网页上的内容经常都在发生变化,我昨天晚上写好了爬虫代码,调试不报错了,今天来写这篇 record 时,用昨天的正则式就多匹配出来两项,这里的正则式是今天又小改了一下的。所以,我的爬虫初体验就是,具体问题具体分析,很灵活多变的。
最后,展示一下下载好的图片吧~~~网页上书目条数是3367,因为是覆盖写,最后保存的图片是3025张。

附上完整的代码:
import time
start=time.perf_counter()
import requests
import re
links=[]
names=[]
n=[]
response_time=0
print("Loading...")
for i in range(57):
url=r'http://search.dangdang.com/?key=python&act=input&page_index='+str(i+1)
t0=time.perf_counter()
response=requests.get(url)
t1=time.perf_counter()
response_time=response_time+t1-t0
text=response.text
fit=re.findall("" ,text)
n.append(len(fit))
for i in fit:
links.append(re.findall("http.*?jpg",i))
name=re.findall("alt.*'",i)
name=re.sub("^alt=' ","",name[0])
name=re.sub("'$","",name)
names.append(name)
for i in range(len(names)):
names[i]=re.sub("[\*/\|:\?]"," ",names[i])
t0=time.perf_counter()
for i in range(len(links)):
print("Downloding the Picture of "+names[i]+" from: "+links[i][0])
pic=requests.get(links[i][0])
file=open(names[i]+".jpg","wb")
file.write(pic.content)
file.close()
t1=time.perf_counter()
download_time=t1-t0
end=time.perf_counter()
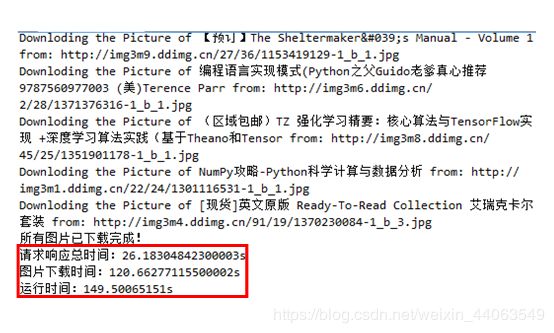
print("所有图片已下载完成!")
print("请求响应总时间:{}s".format(response_time))
print("图片下载时间:{}s".format(download_time))
print("运行时间:{}s".format(end-start))
加了个时间监测,requests.get 向网页发出请求到响应的总耗时为26s,向3367张图片的 HTTP 发出请求后响应、并保存的总耗时为120s,程序的总运行时间149s。