Python深度学习-ch5深度学习用于计算机视觉
本章包括以下内容:
-
理解卷积神经网络(convnet)
-
使用数据增强来降低过拟合
-
使用预训练的卷积神经网络进行特征提取
-
微调预训练的卷积神经网络
-
把卷积神经网络学到的内容和其做出的 分类决策可视化
5.1 卷积神经网络简介
随着卷积层的加入,特征的尺寸在不断减小,深度在不断加深,深度卷积神经网络的主要目标是在提升模型性能的前提下,尽可能使深度最大化。
5.1.1卷积运算
集连接层和卷积层的根本区别在于,Dense 层从输入特征空间中学到的是全局模式(比如对于MNIST 数字,全局模式就是涉及所有像素的模式),而卷积层学到的是局部模式,对于图像来说,学到的就是在输入图像的二维小窗口中发现的模式。
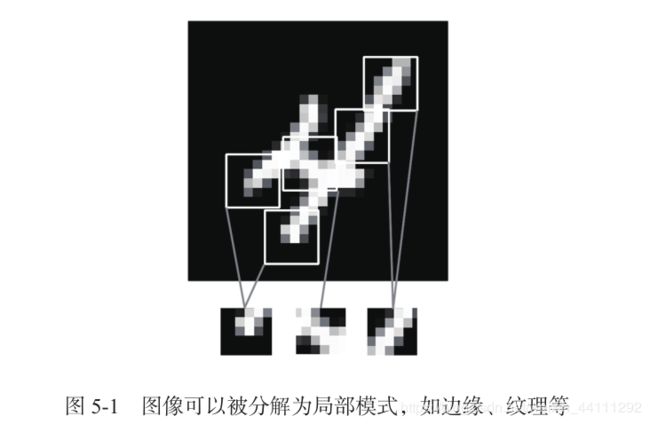
这个重要特性使卷积神经网络具有以下两个有趣的性质
卷积神经网络学到的模式具有平移不变性,卷积神经网络在图像的某个位置学到特征之后,他可以在图像的任何位置识别这个特征,但是全连接层做不到这样。
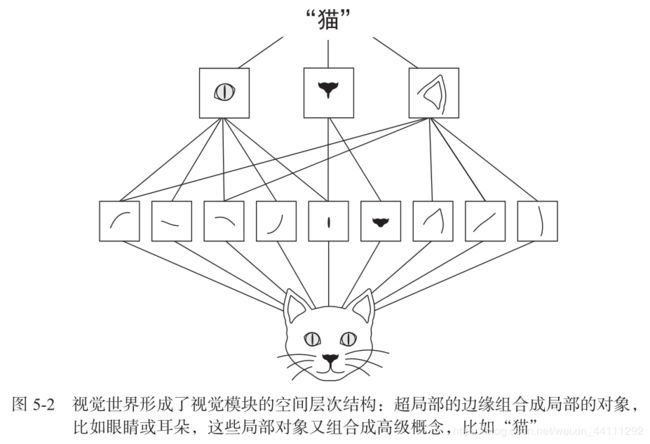
卷积神经网络可以学到模式的空间层次结构见图 5-2。第一个卷积层将学习较小的局部模式(比如边缘) ,第二个卷积层将学习由第一层特征组成的更大的模式,以此类推。这使得卷积神经网络可以有效地学习越来越复杂、越来越抽象的视觉概念。
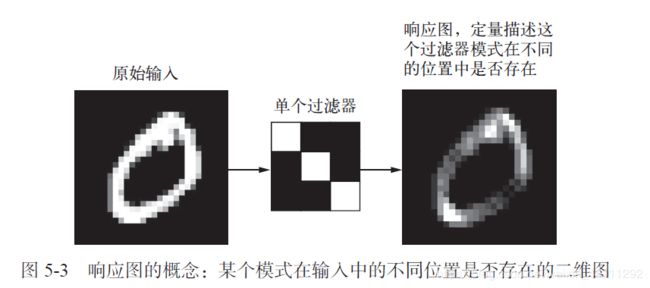
对于包含两个空间轴(高度和宽度) 和一个 深度轴(也叫通道轴) 的 3D 张量,其卷积也叫特征图(feature map) 。对于RGB 图像, 深度轴的维度大小等于 3, 因为图像有 3 个颜色通道:红色、绿色和蓝色。对于黑白图像(比如 MNIST 数字图像) ,深度等于 1(表示灰度等级) 。卷积运算从输入特征图中提取图块,并对所有这些图块应用相同的变换,生成输出特征图(output feature map) 。该输出特征图仍是一个 3D 张量,具有宽度和高度,其深度可以任意取值,因为输出深度是层的参数,深度轴的不同通道不再像 RGB 输入那样代表特定颜色,而是代表过滤器(filter) 。过滤器对输入数据的某一方面进行编码,比如,单个过滤器可以从更高层次编码这样一个概念: “输入中包含一张脸。 ”
在MNIST 示例中,第一个卷积层接收一个大小为(28, 28, 1) 的特征图,并输出一个大小为(26, 26, 32) 的特征图,即它在输入上计算32 个过滤器。对于这32 个输出通道,每个通道都包含一个26×26 的数值网格,它是过滤器对输入的响应图(response map),表示这个过滤器模式在输入中不同位置的响应(见图5-3)。这也是特征图这一术语的含义:深度轴的每个维度都是一个特征(或过滤器),而2D 张量output[:, :, n] 是这个过滤器在输入上的响应的二维空间图(map)(n代表过滤器的次序)。
卷积由以下两个关键参数所定义。
- 从输入中提取的图块尺寸(我理解的是卷积核的除了深度以为的尺寸):这些图块的大小通常是 3×3 或 5×5。本例中为 3×3,这是很常见的选择。
- 输出特征图的深度:卷积所计算的过滤器的数量。本例第一层的深度为32,最后一层的深度是64。
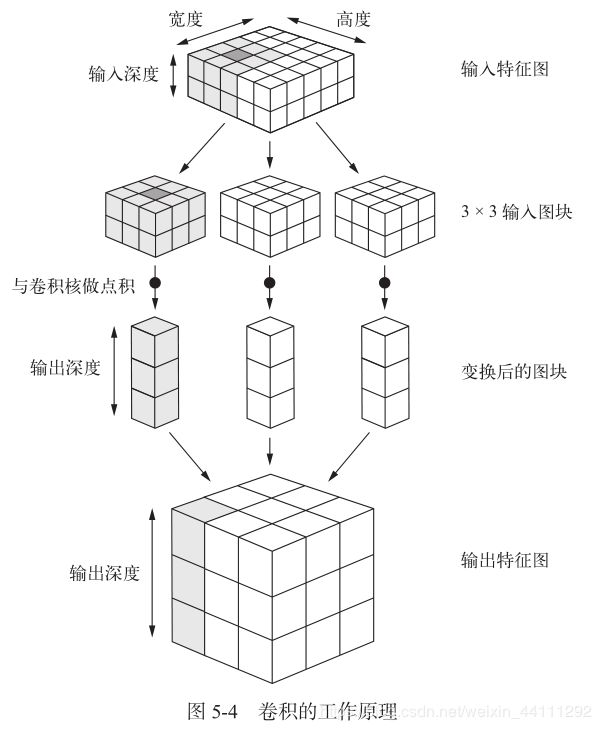
卷积的工作原理:在3D 输入特征图上滑动(slide)这些3×3 或5×5 的窗口,在每个可能的位置停止并提取周围特征的3D 图块[形状(window_height,window_width, input_depth)]。然后每个3D 图块与学到的同一个**权重矩阵[叫作卷积核(convolution kernel)]**做张量积,转换成形状为(output_depth,) 的1D 向量。然后对所有这些向量进行空间重组,使其转换为形状为(height, width, output_depth) 的3D 输出特征图。输出特征图中的每个空间位置都对应于输入特征图中的相同位置(比如输出的右下角包含了输入右下角的信息)。举个例子,利用3×3 的窗口,向量output[i, j, :] 来自3D 图块input[i-1:i+1,j-1:j+1, :]。整个过程详见图5-4。
注意,输出的宽度和高度可能与输入的宽度和高度不同。不同的原因可能有两点。
边界效应可以通过对输入特征图进行填充来抵消。
使用了 步幅(stride),稍后会给出其定义。
我们来深入研究一下这些概念。
- 理解边界效应与填充
假设有一个 5×5 的特征图(共 25 个方块) 。其中只有 9 个方块可以作为中心放入一个3×3 的窗口,这 9 个方块形成一个 3×3 的网格(见图 5-5) 。因此,输出特征图的尺寸是 3×3。它比输入尺寸小了一点,在本例中沿着每个维度都正好缩小了 2 个方块。在前一个例子中你也可以看到这种边界效应的作用:开始的输入尺寸为 28×28,经过第一个卷积层之后尺寸变为26×26。
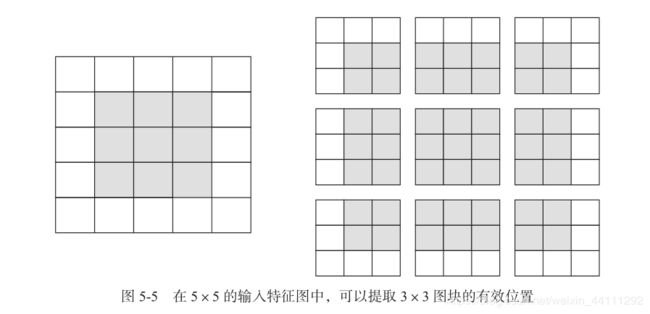
如果你希望输出特征图的空间维度与输入相同,那么可以使用 填充(padding) 填充是在输入特征图的每一边添加适当数目的行和列,使得每个输入方块都能作为卷积窗口的中心。对于 3×3 的窗口,在左右各添加一列,在上下各添加一行。对于 5×5 的窗口,各添加两行和两列(见图 5-6)。
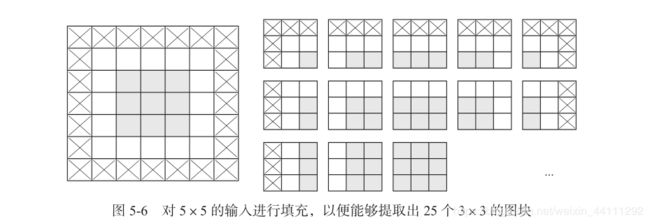
对于 Conv2D 层,可以通过 padding 参数来设置填充,这个参数有两个取值: “valid” 表示不使用填充(只使用有效的窗口位置) ; "same" 表示“填充后输出的宽度和高度与输入相同” 。padding 参数的默认值为 “valid”
- 理解卷积步幅
影响输出尺寸的另一个因素是步幅的概念。目前为止,对卷积的描述都假设卷积窗口的中心方块都是相邻的。但两个连续窗口的距离是卷积的一个参数,叫作步幅,默认值为 1。也可以使用步进卷积(strided convolution) ,即步幅大于 1 的卷积。 在图 5-7 中,你可以看到用步幅
为 2 的 3×3 卷积从 5×5 输入中提取的图块(无填充) 。

5.1.2 最大池化运算
在卷积神经网络示例中,你可能注意到,在每个 MaxPooling2D 层之后,特征图的尺寸都会减半。例如,在第一个MaxPooling2D 层之前,特征图的尺寸是 26×26,但最大池化运算将其减半为 13×13。这就是最大池化的作用:对特征图进行下采样,与步进卷积类似。
使用下采样的原因,一是减少需要处理的特征图的元素个数,二是通过让连续卷积层的观察窗口越来越大(即窗口覆盖原始输入的比例越来越大),从而引入空间过滤器的层级结构。
最大池化与卷积的最大不同之处在于,最大池化通常使用2×2 的窗口和步幅2,其目的是将特征图下采样2 倍。与此相对的是,卷积通常使用3×3 窗口和步幅1
注意,最大池化不是实现这种下采样的唯一方法你已经知道,还可以在前一个卷积层中使用步幅来实现。此外,你还可以使用平均池化来代替最大池化,其方法是将每个局部输入图块变换为取该图块各通道的平均值,而不是最大值。但最大池化的效果往往比这些替代方法更好。
简而言之,原因在于特征中往往编码了某种模式或概念在特征图的不同位置是否存在(因此得名特征图),而观察不同特征的最大值而不是平均值能给出更多的信息。因此,最合理的子采样策略是首先生成密集的特征图(通过无步进的卷积),然后观察特征每个小图块上的最大激活,而不是查看输入的稀疏窗口(通过步进卷积)或对输入图块取平均,因为后两种方法可能导致错过或淡化特征是否存在的信息。
5.2在小型数据集上从头开始训练一个卷积神经网络
这三种策略——从头开始训练一个小型模型、使用预训练的网络做特征提取、对预训练的网络进行微调——构成了你的工具箱,未来可用于解决小型数据集的图像分类问题
5.2.1 深度学习与小数据问题的相关性
有时你会听人说,仅在有大量数据可用时,深度学习才有效。这种说法部分正确:深度学习的一个基本特性就是能够独立地在训练数据中找到有趣的特征,无须人为的特征工程,而这只在拥有大量训练样本时才能实现。
但对于初学者来说,所谓“大量”样本是相对的,即相对于你所要训练网络的大小和深度而言。只用几十个样本训练卷积神经网络就解决一个复杂问题是不可能的,但如果模型很小,并做了很好的正则化,同时任务非常简单,那么几百个样本可能就足够了。由于卷积神经网络学到的是局部的、平移不变的特征,它对于感知问题可以高效地利用数据。虽然数据相对较少,
但在非常小的图像数据集上从头开始训练一个卷积神经网络,仍然可以得到不错的结果,而且无须任何自定义的特征工程。
5.2.2 下载数据
来着kaggle竞赛平台的猫狗分类数据集
(os与shutill库的用法:https://www.cnblogs.com/coder2012/p/4142420.html)
代码中的文件路径成‘D:\AI\train\train’单杠变双杠
5.2.3 构建网络
在前一个 MNIST 示例中,我们构建了一个小型卷积神经网络,所以你应该已经熟悉这种网络。我们将复用相同的总体结构,即卷积神经网络由 Conv2D 层(使用 relu 激活)和MaxPooling2D 层交替堆叠构成。
由于这里要处理的是更大的图像和更复杂的问题,你需要相应地增大网络,即再增加一个Conv2D+MaxPooling2D 的组合。这既可以增大网络容量,也可以进一步减小特征图的尺寸,使其在连接Flatten 层时尺寸不会太大。
你面对的是一个二分类问题,所以网络最后一层是使用sigmoid 激活的单一单元(大小为1 的Dense 层)。这个单元将对某个类别的概率进行编码。
注意 网络中特征图的深度在逐渐增大(从32 增大128),而特征图的尺寸在逐渐减小(从150×150 减小到7×7)。这几乎是所有卷积神经网络的模式。
5.2.4 数据预处理
我们已经知道,将数据输入神经网络之前,应该将数据格式化为经过预处理的浮点数张量。
现在,数据以JPEG 文件的形式保存在硬盘中,所以数据预处理步骤大致如下。
(1) 读取图像文件。
(2) 将JPEG 文件解码为RGB 像素网格。
(3) 将这些像素网格转换为浮点数张量。
(4) 将像素值(0~255 范围内)缩放到[0, 1] 区间(正如你所知,神经网络喜欢处理较小的输入值)。
Keras有一个图像处理辅助工具的模块,位于keras.preprocessing.image。特别地,它包含ImageDataGenerator 类,可以快速创建Python 生成器,能够将硬盘上的批量图像文件自动转换为预处理好的张量
(ImageDataGenerator生成器的flow,flow_from_directory用法:
https://blog.csdn.net/ztf312/article/details/88856215)
前面已经介绍过几种降低过拟合的技巧,比如dropout 和权重衰减(L2 正则化)。现在我们将使用一种针对于计算
机视觉领域的新方法,在用深度学习模型处理图像时几乎都会用到这种方法,它就是数据增强(data augmentation)
5.2.5 使用数据增强
过拟合的原因是学习样本太少,导致无法训练出能够泛化到新数据的模型。如果拥有无限的数据,那么模型能够观察到数据分布的所有内容,这样就永远不会过拟合。数据增强是从现有的训练样本中生成更多的训练数据,其方法是利用多种能够生成可信图像的 随机变换来增加(augment)样本。其目标是,模型在训练时不会两次查看完全相同的图像,这让模型能够观察到数据的更多内容,从而具有更好的泛化能力。
在Keras 中,可以通过ImageDataGenerator 实例读取的图像执行多次随机变换来实现。
如果你使用这种数据增强来训练一个新网络,那么网络将不会两次看到同样的输入。但网络看到的输入仍然是高度相关的,因为这些输入都来自于少量的原始图像。你无法生成新信息,而只能混合现有信息。因此,这种方法可能不足以完全消除过拟合。为了进一步降低过拟合,你还需要向模型中添加一个 Dropout 层,添加到密集连接分类器之前。
5.3 使用预训练的卷积神经网络
想要将深度学习应用于小型图像数据集,一种常用且非常高效的方法是使用预训练网络。
预训练网络(pretrained network)是一个保存好的网络,之前已在大型数据集(通常是大规模图像分类任务)上训练好。如果这个原始数据集足够大且足够通用,那么预训练网络学到的特征的空间层次结构可以有效地作为视觉世界的通用模型,因此这些特征可用于各种不同的计算机视觉问题,即使这些新问题涉及的类别和原始任务完全不同。举个例子,你在 ImageNet 上训练了一个网络(其类别主要是动物和日常用品) ,然后将这个训练好的网络应用于某个不相干的任务,比如在图像中识别家具。这种学到的特征在不同问题之间的可移植性,是深度学习与许多早期浅层学习方法相比的重要优势,它使得深度学习对小数据问题非常有效。
使用预训练网络有两种方法:特征提取(feature extraction) 和微调模型(fine-tuning) 。两种方法我们都会介绍
5.3.1 特征提取
特征提取是使用之前网络学到的表示来从新样本中提取出有趣的特征。然后将这些特征输入一个新的分类器,从头开始训练。
如前所述,用于图像分类的卷积神经网络包含两部分:首先是一系列池化层和卷积层,最后是一个密集连接分类器。第一部分叫作模型的卷积基(convolutional base) 。对于卷积神经网络而言,特征提取就是取出之前训练好的网络的卷积基,在上面运行新数据,然后在输出上面训练一个新的分类器。
为什么仅重复使用卷积基?我们能否也重复使用密集连接分类器? 一般来说,应该避免这么做。原因在于卷积基学到的表示可能更加通用,因此更适合重复使用。卷积神经网络的特征图表示通用概念在图像中是否存在,无论面对什么样的计算机视觉问题,这种特征图都可能很有用 ,如果物体位置对于问题很重要,那么密集连接层的特征在很大程度上是无用的
卷积基实例化后,有两种方法添加密集连接分类器
- 不使用数据增强的快速特征提取
保存你的数据在 conv_base 中的输出,然后将这些输出作为输入用于新模型。
首先,运行 ImageDataGenerator 实例,将图像及其标签提取为 Numpy 数组。我们需要调用 conv_base 模型的 predict 方法来从这些图像中提取特征。
我们的验证精度达到了约 90%,比上一节从头开始训练的小型模型效果要好得多。虽然 dropout 比率相当大,但模型几乎从一开始就过拟合。这是因为本方法没有使用数据增强,而数据增强对防止小型图像数据集的过拟合非常重要。
- 使用数据增强的特征提取
下面我们来看一下特征提取的第二种方法,它的速度更慢,计算代价更高,但在训练期间可以使用数据增强。这种方法就是:扩展 conv_base 模型,然后在输入数据上端到端地运行模型,模型的行为和层类似,所以你可以向Sequential 模型中添加一个模型(比如 conv_base ),就像添加一个层一样。
在编译和训练模型之前,一定要**“冻结”**卷积基。冻结(freeze)一个或多个层是指在训练过程中保持其权重不变。如果不这么做,那么卷积基之前学到的表示将会在训练过程中被修改。因为其上添加的 Dense 层是随机初始化的,所以非常大的权重更新将会在网络中传播,对之前学到的表示造成很大破坏。在 Keras 中,冻结网络的方法是将其trainable 属性设为 False 。
5.3.2 微调模型
另一种广泛使用的模型复用方法是模型微调(fine-tuning) ,与特征提取互为补充。对于用于特征提取的冻结的模型基,微调是指将其顶部的几层“解冻” ,并将这解冻的几层和新增加的部分(本例中是全连接分类器)联合训练(见图 5-19)。之所以叫作微调,是因为它只是略微调整了所复用模型中更加抽象的表示,以便让这些表示与手头的问题更加相关。
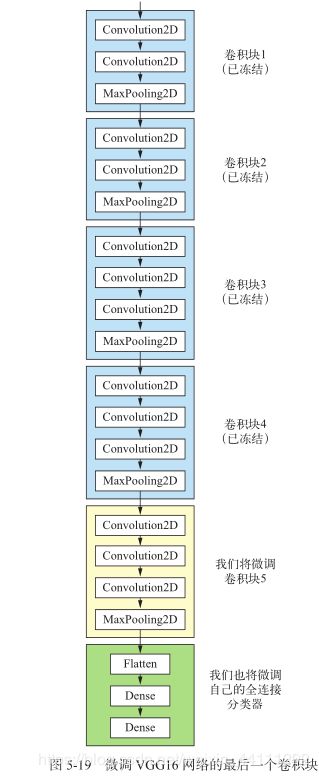
为什么不微调更多层?为什么不微调整个卷积基?你当然可以这么做, 但需要考虑以下几点。
- 卷积基中更靠底部的层编码的是更加通用的可复用特征,而更靠顶部的层编码的是更专业化的特征。微调这些更专业化的特征更加有用,因为它们需要在你的新问题上改变用途。微调更靠底部的层,得到的回报会更少。
- 训练的参数越多,过拟合的风险越大。卷积基有 1500 万个参数,所以在你的小型数据集上训练这么多参数是有风险的。
5.3.3 小结
下面是你应该从以上两节的练习中学到的要点。
-
卷积神经网络是用于计算机视觉任务的最佳机器学习模型。即使在非常小的数据集上也可以从头开始训练一个卷积神经网络,而且得到的结果还不错。
-
在小型数据集上的主要问题是过拟合。在处理图像数据时,数据增强是一种降低过拟合的强大方法。
-
利用特征提取,可以很容易将现有的卷积神经网络复用于新的数据集。对于小型图像数据集,这是一种很有价值的方法。
-
作为特征提取的补充,你还可以使用微调,将现有模型之前学到的一些数据表示应用于新问题。这种方法可以进一步提高模型性能。现在你已经拥有一套可靠的工具来处理图像分类问题,特别是对于小型数据集。
5.4 卷积神经网络的可视化
人们常说,深度学习模型是“黑盒” ,即模型学到的表示很难用人类可以理解的方式来提取和呈现。虽然对于某些类型的深度学习模型来说,这种说法部分正确,但对卷积神经网络来说绝对不是这样。卷积神经网络学到的表示非常适合可视化,很大程度上是因为它们是视觉概念的表示。自 2013 年以来,人们开发了多种技术来对这些表示进行可视化和解释。我们不会在书中全部介绍,但会介绍三种最容易理解也最有用的方法。
-
可视化卷积神经网络的中间输出(中间激活):有助于理解卷积神经网络连续的层如何对输入进行变换,也有助于初步了解卷积神经网络每个过滤器的含义。
-
可视化卷积神经网络的过滤器:有助于精确理解卷积神经网络中每个过滤器容易接受的视觉模式或视觉概念。
-
可视化图像中类激活的热力图:有助于理解图像的哪个部分被识别为属于某个类,从而可以定位图像中的物体。
对于第一种方法(即激活的可视化) ,我们将使用 5.2 节在猫狗分类问题上从头开始训练的小型卷积神经网络。对于另外两种可视化方法,我们将使用 5.3 节介绍的 VGG16 模型
5.4.1 可视化中间激活
可视化中间激活,是指对于给定输入,展示网络中各个卷积层和池化层输出的特征图(层的输出通常被称为该层的激活,即激活函数的输出) 。 这让我们可以看到输入如何被分解为网络学到的不同过滤器。我们希望在三个维度对特征图进行可视化:宽度、高度和深度(通道) 。每个通道都对应相对独立的特征,所以将这些特征图可视化的正确方法是将每个通道的内容分别绘制成二维图像。我们首先来加载 5.2 节保存的模型
接下来,我们需要一张输入图像,即一张猫的图像,它不属于网络的训练图像
(np.expand_dims方法的理解:
https://www.zhihu.com/question/265545749?sort=created)
显示出的测试图像如下:

为了提取想要查看的特征图,我们需要创建一个 Keras 模型,以图像批量作为输入,并输出所有卷积层和池化层的激活。为此,我们需要使用 Keras 的 Model 类。模型实例化需要两个参数:一个输入张量(或输入张量的列表)和一个输出张量(或输出张量的列表) 。得到的类是一个Keras 模型,就像你熟悉的 Sequential 模型一样,将特定输入映射为特定输出。 Model 类允许模型有多个输出,这一点与 Sequential 模型不同。
输入一张图像,这个模型将返回原始模型前 8 层的激活值。这是你在本书中第一次遇到的多输出模型,之前的模型都是只有一个输入和一个输出。一般情况下,模型可以有任意个输入和输出。这个模型有一个输入和 8 个输出,即每层激活对应一个输出。
对于模型第一层的输出,它是大小为 148×148 的特征图,有 32 个通道。我们来绘制原始模型第一层激活的第 4 个通道(见图 5-25) 。
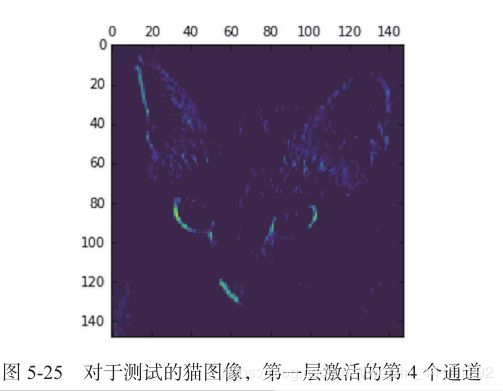
这个通道似乎是对角边缘检测器。我们再看一下第 7 个通道(见图 5-26) 。但请注意,你的通道可能与此不同,因为卷积层学到的过滤器并不是确定的。

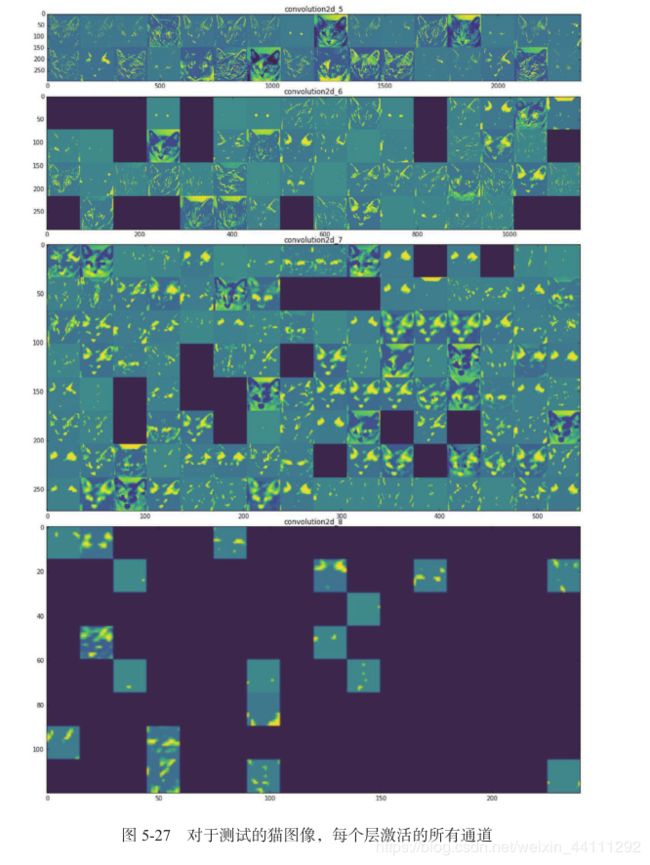
这个通道看起来像是“鲜绿色圆点”检测器,对寻找猫眼睛很有用。下面我们来绘制网络中所有激活的完整可视化(见图 5-27) 。我们需要在 8 个特征图中的每一个中提取并绘制每一个通道,然后将结果叠加在一个大的图像张量中,按通道并排。
这里需要注意以下几点。
- 第一层是各种边缘探测器的集合。在这一阶段,激活几乎保留了原始图像中的所有信息。
- 随着层数的加深,激活变得越来越抽象,并且越来越难以直观地理解。它们开始表示更高层次的概念,比如“猫耳朵”和“猫眼睛”
- 层数越深,其表示中关于图像视觉内容的信息就越少,而关于类别的信息就越多。
激活的稀疏度(sparsity)随着层数的加深而增大。在第一层里,所有过滤器都被输入图像激活,但在后面的层里,越来越多的过滤器是空白的。也就是说,输入图像中找不到这些过滤器所编码的模式。
我们刚刚揭示了深度神经网络学到的表示的一个重要普遍特征:随着层数的加深,层所提取的特征变得越来越抽象。 更高的层激活包含关于特定输入的信息越来越少,而关于目标的信息越来越多(本例中即图像的类别:猫或狗) 。深度神经网络可以有效地作为信息蒸馏管道(information distillation pipeline) ,输入原始数据(本例中是 RGB 图像) ,反复对其进行变换,将无关信息过滤掉(比如图像的具体外观) ,并放大和细化有用的信息(比如图像的类别) 。
5.4.2 可视化卷积神经网络的过滤器
想要观察卷积神经网络学到的过滤器,另一种简单的方法是显示每个过滤器所响应的视觉模式。这可以通过在输入空间中进行梯度上升(不理解)来实现:从空白输入图像开始,将梯度下降应用于卷积神经网络输入图像的值,其目的是让某个过滤器的响应最大化。得到的输入图像是选定过滤器具有最大响应的图像。
这个过程很简单:我们需要构建一个损失函数,其目的是让某个卷积层的某个过滤器的值最大化;然后,我们要使用随机梯度下降来调节输入图像的值,以便让这个激活值最大化。
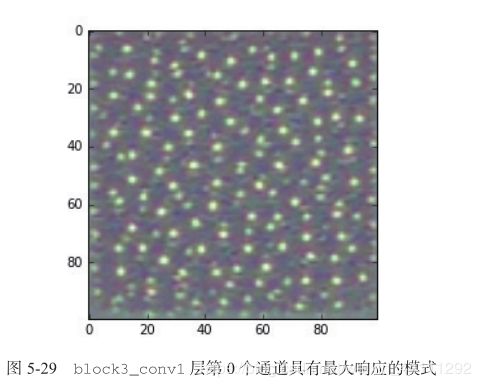
看起来, block3_conv1 层第 0 个过滤器响应的是波尔卡点(polka-dot)图案。下面来看有趣的部分:我们可以将每一层的每个过滤器都可视化。为了简单起见,我们只查看每一层的前 64 个过滤器,并只查看每个卷积块的第一层(即 block1_conv1 、 block2_conv1 、block3_conv1 、 block4_ conv1 、 block5_conv1 ) 。我们将输出放在一个 8×8 的网格中,每个网格是一个 64 像素×64 像素的过滤器模式,两个过滤器模式之间留有一些黑边(见图 5-30 ~ 图 5-33) 。


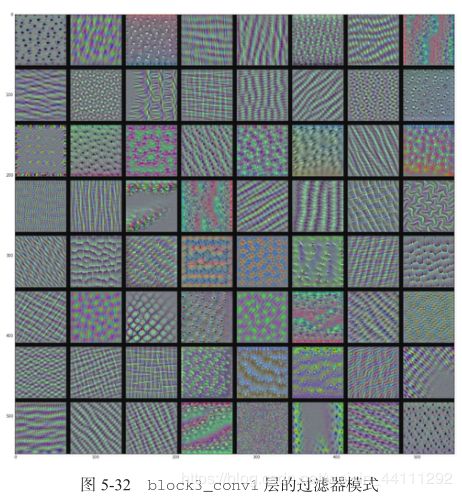

这些过滤器可视化包含卷积神经网络的层如何观察世界的很多信息:卷积神经网络中每一层都学习一组过滤器,以便将其输入表示为过滤器的组合。这类似于傅里叶变换将信号分解为一组余弦函数的过程。随着层数的加深,卷积神经网络中的过滤器变得越来越复杂,越来越精细。
-
模型第一层( block1_conv1 )的过滤器对应简单的方向边缘和颜色(还有一些是彩色边缘) 。
-
block2_conv1 层的过滤器对应边缘和颜色组合而成的简单纹理。
-
更高层的过滤器类似于自然图像中的纹理:羽毛、眼睛、树叶等。
5.4.3 可视化类激活的热力图
我还要介绍另一种可视化方法,它有助于了解一张图像的哪一部分让卷积神经网络做出了最终的分类决策。 这有助于对卷积神经网络的决策过程进行调试, 特别是出现分类错误的情况下。
这种方法还可以定位图像中的特定目标。这种通用的技术叫作类激活图(CAM,class activation map)可视化,它是指对输入图像生成类激活的热力图。类激活热力图是与特定输出类别相关的二维分数网格,对任何输入图像的每个位置都要进行计算,它表示每个位置对该类别的重要程度。 举例来说,对于输入到猫狗分类卷积神经网络的一张图像,CAM 可视化可以生成类别“猫”的热力图,表示图像的各个部分
与“猫”的相似程度, CAM 可视化也会生成类别“狗”的热力图, 表示图像的各个部分与“狗”的相似程度。
我们将使用的具体实现方式是“Grad-CAM: visual explanations from deep networks via gradient-based localization” 这篇论文中描述的方法。这种方法非常简单: 给定一张输入图像, 对于一个卷积层的输出特征图,用类别相对于通道的梯度对这个特征图中的每个通道进行加权。直观上来看,理解这个技巧的一种方法是,你是用“每个通道对类别的重要程度”对“输入图像对不同通道的激活强度”的空间图进行加权,从而得到了“输入图像对类别的激活强度”的空间图。
我们再次使用预训练的 VGG16 网络来演示此方法。
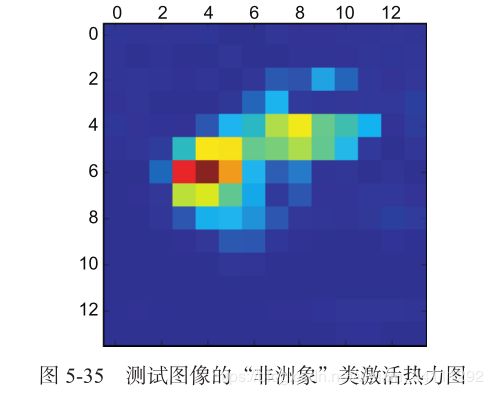
图 5-34 显示了两只非洲象的图像 ,可能是一只母象和它的小象,它们在大草原上漫步。我们将这张图像转换为 VGG16 模型能够读取的格式:模型在大小为224×224 的图像上进行训练,这些训练图像都根据keras.applications.vgg16.preprocess_
input 函数中内置的规则进行预处理。因此,我们需要加载图像,将其大小调整为 224×224,然后将其转换为 float32 格式的 Numpy 张量,并应用这些预处理规则。

对这张图像预测的前三个类别分别为:
- 非洲象(African elephant,92.5% 的概率)
- 长牙动物(tusker,7% 的概率)
印度象(Indian elephant,0.4% 的概率)网络识别出图像中包含数量不确定的非洲象。 预测向量中被最大激活的元素是对应 “非洲象”类别的元素,索引编号为 386。
为了展示图像中哪些部分最像非洲象,我们来使用 Grad-CAM 算法。
为了便于可视化,我们还需要将热力图标准化到 0~1 范围内。得到的结果如图 5-35 所示。
最后,我们可以用 OpenCV 来生成一张图像,将原始图像叠加在刚刚得到的热力图上(见图 5-36) 。

这种可视化方法回答了两个重要问题:
- 网络为什么会认为这张图像中包含一头非洲象?
- 非洲象在图像中的什么位置?
尤其值得注意的是,小象耳朵的激活强度很大,这可能是网络找到的非洲象和印度象的不同之处。