R语言基础命令一网打尽
一、数据类型
> a<-c(35,6,3,4,6,3,67,8,56)
> a
[1] 35 6 3 4 6 3 67 8 56
> class(a)
[1] "numeric"
> a=as.integer(a)
> class(a)
[1] "integer"
> which(a>4)
[1] 1 2 5 7 8 9
> a[which(a>4)]
[1] 35 6 6 67 8 56
> a[1]
[1] 35
> is.logical(a)
[1] FALSE
> a<-c(35,6,3,4,6,3,67,8,56)
> a[1]
[1] 35
> is.logical(a)
[1] FALSE
> which(a>10)
[1] 1 7 9
> class(a)
[1] "numeric"
> a<-factor(a)
> a
[1] 35 6 3 4 6 3 67 8 56
Levels: 3 4 6 8 35 56 67
> class(a)
[1] "factor"
> levels(a)
[1] "3" "4" "6" "8" "35" "56" "67"
> y<-c('python','java','r','spark')
> class(y)
[1] "character"
> length(y)
[1] 4
> class(y)
[1] "character"
> length(y)
[1] 4
> nchar(y)
[1] 6 4 1 5
> y=='r'
[1] FALSE FALSE TRUE FALSE
> s<-factor(c(1,1,1,0,0,1),levels=c(0,1),labels=c('male','female'))
> s
[1] female female female male male female
Levels: male female
> class(s)
[1] "factor"
> num<-factor(c('a','b','c','d'))
> num
[1] a b c d
Levels: a b c d
> class(num)
[1] "factor"
> as.numeric(num)
[1] 1 2 3 4
> num+1
[1] NA NA NA NA
Warning message:
In Ops.factor(num, 1) : ‘+’ not meaningful for factors
> as.numeric(num)+2
[1] 3 4 5 6
二、数据基本信息
> library(MASS)
> data("airquality")
> head(airquality)
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
6 28 NA 14.9 66 5 6
> dim(airquality)
[1] 153 6
> airquality[2:4,]
Ozone Solar.R Wind Temp Month Day
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
> tail(airquality,3)
Ozone Solar.R Wind Temp Month Day
151 14 191 14.3 75 9 28
152 18 131 8.0 76 9 29
153 20 223 11.5 68 9 30
> names(airquality)
[1] "Ozone" "Solar.R" "Wind" "Temp" "Month" "Day"
> colnames(airquality)
[1] "Ozone" "Solar.R" "Wind" "Temp" "Month" "Day"
> nrow(airquality);ncol(airquality)
[1] 153
[1] 6
> var=c('Ozone','Wind','Temp','Month','Day')
> airquality[3:6,var]
Ozone Wind Temp Month Day
3 12 12.6 74 5 3
4 18 11.5 62 5 4
5 NA 14.3 56 5 5
6 28 14.9 66 5 6
> head(airquality$Wind)
[1] 7.4 8.0 12.6 11.5 14.3 14.9
> class(airquality$Temp);class(airquality$Wind)
[1] "integer"
[1] "numeric"
> is.character(airquality$Wind)
[1] FALSE
> is.integer(airquality$Month)
[1] TRUE
> is.integer(airquality$Wind)
[1] FALSE
> is.numeric(airquality$Wind)
[1] TRUE
> unique(airquality$Month)
[1] 5 6 7 8 9
三、数据抽样
继续使用上面的例子:
1、sample简单随机抽样
随机抽取10行数据。
> sub<-sample(nrow(airquality),10,replace=TRUE) #实际采用FALSE,避免重复抽样
> sub
[1] 84 85 131 31 63 16 67 97 66 29
> airquality[sub,]
Ozone Solar.R Wind Temp Month Day
84 NA 295 11.5 82 7 23
85 80 294 8.6 86 7 24
131 23 220 10.3 78 9 8
31 37 279 7.4 76 5 31
63 49 248 9.2 85 7 2
16 14 334 11.5 64 5 16
67 40 314 10.9 83 7 6
97 35 NA 7.4 85 8 5
66 64 175 4.6 83 7 5
29 45 252 14.9 81 5 29
2、复杂抽样strata()和cluster()
分层抽样
> install.packages('sampling')
> library(sampling)
> sub<-strata(airquality,stratanames="Month",size=c(2,3,1,4,3),method='srswor')
> sub
Month ID_unit Prob Stratum
11 5 11 0.06451613 1
28 5 28 0.06451613 1
32 6 32 0.10000000 2
45 6 45 0.10000000 2
56 6 56 0.10000000 2
86 7 86 0.03225806 3
96 8 96 0.12903226 4
117 8 117 0.12903226 4
119 8 119 0.12903226 4
123 8 123 0.12903226 4
129 9 129 0.10000000 5
135 9 135 0.10000000 5
152 9 152 0.10000000 5
> getdata(airquality,sub)
Ozone Solar.R Wind Temp Day Month ID_unit Prob Stratum
11 7 NA 6.9 74 11 5 11 0.06451613 1
28 23 13 12.0 67 28 5 28 0.06451613 1
32 NA 286 8.6 78 1 6 32 0.10000000 2
45 NA 332 13.8 80 14 6 45 0.10000000 2
56 NA 135 8.0 75 25 6 56 0.10000000 2
86 108 223 8.0 85 25 7 86 0.03225806 3
96 78 NA 6.9 86 4 8 96 0.12903226 4
117 168 238 3.4 81 25 8 117 0.12903226 4
119 NA 153 5.7 88 27 8 119 0.12903226 4
123 85 188 6.3 94 31 8 123 0.12903226 4
129 32 92 15.5 84 6 9 129 0.10000000 5
135 21 259 15.5 76 12 9 135 0.10000000 5
152 18 131 8.0 76 29 9 152 0.10000000 5
整群抽样
> sub<-cluster(airquality,clustername='Month',size=2,method='srswor',description=TRUE)
Number of selected clusters: 2
Number of units in the population and number of selected units: 153 61
> getdata(airquality,sub)
Ozone Solar.R Wind Temp Day Month ID_unit Prob
89 82 213 7.4 88 28 7 89 0.4
90 50 275 7.4 86 29 7 90 0.4
91 64 253 7.4 83 30 7 91 0.4
92 59 254 9.2 81 31 7 92 0.4
84 NA 295 11.5 82 23 7 84 0.4
85 80 294 8.6 86 24 7 85 0.4
86 108 223 8.0 85 25 7 86 0.4
篇幅限制,省略部分数据
3、训练数据和测试数据的抽样划分
> train_sub<-sample(nrow(airquality),3/4*nrow(airquality))
> test_data=airquality[-train_sub,]
> train_sub<-sample(nrow(airquality),3/4*nrow(airquality))
> train_data=airquality[train_sub,]
> test_data=airquality[-train_sub,]
> dim(train_data);dim(test_data)
[1] 114 6
[1] 39 6
四、数据获取
1、内置数据集
> data(package='datasets')
部分结果如下

> ?swiss 
2、软件包的数据集
> data(package=.packages(all.available = TRUE))
> library(arules)
> data("Groceries")
> head(Groceries)
transactions in sparse format with
6 transactions (rows) and
169 items (columns)
3、获取其它格式数据
读取csv文件
> setwd('d://R') #设定工作环境
> write.csv(airquality,'aqi.csv')
> aqi<-read.csv('aqi.csv')
> head(aqi)
X Ozone Solar.R Wind Temp Month Day
1 1 41 190 7.4 67 5 1
2 2 36 118 8.0 72 5 2
3 3 12 149 12.6 74 5 3
4 4 18 313 11.5 62 5 4
5 5 NA NA 14.3 56 5 5
6 6 28 NA 14.9 66 5 6
读取txt文件
> write.table(Insurance,'in.txt')
> insur_txt<-read.table('in.txt')
> head(insur_txt)
District Group Age Holders Claims
1 1 <1l <25 197 38
2 1 <1l 25-29 264 35
3 1 <1l 30-35 246 20
4 1 <1l >35 1680 156
5 1 1-1.5l <25 284 63
6 1 1-1.5l 25-29 536 84
读取Excel文件
> library(RODBC)
> channel=odbcConnectExcel2007('jdstock.xlsx')
> channel
RODBC Connection 3
Details:
case=nochange
DBQ=d:\R\jdstock.xlsx
DefaultDir=d:\R
Driver={Microsoft Excel Driver (*.xls, *.xlsx, *.xlsm, *.xlsb)}
DriverId=1046
MaxBufferSize=2048
PageTimeout=5
> sqlTables(channel)
TABLE_CAT TABLE_SCHEM TABLE_NAME TABLE_TYPE REMARKS
1 d:\\R\\jdstock.xlsx <NA> data$ SYSTEM TABLE <NA>
> a<-sqlFetch(channel,'data')
> odbcClose(channel)
> head(a)
JD 13 四月 17 32#74 32#47 32#45 32#87 3013600
1 JD 2017-04-12 32.31 32.71 32.31 32.88 6818000
2 JD 2017-04-11 32.70 32.30 32.22 33.28 8054200
3 JD 2017-04-10 32.16 32.67 32.15 32.92 8303800
4 JD 2017-04-07 32.20 32.01 31.57 32.25 5651000
5 JD 2017-04-06 31.69 32.23 31.49 32.26 5840700
6 JD 2017-04-05 31.58 31.53 31.44 32.06 5368400
获取其它软件的数据
> library(foreign)
> a<-read.spss(file='xxx.sav')
4、获取数据库数据
使用前需要在windows管理工具下设置ODBC数据源。
> library(RODBC)
> odbcDataSources() #查看可用数据源
dBASE Files Excel Files
"Microsoft Access dBASE Driver (*.dbf, *.ndx, *.mdx)" "Microsoft Excel Driver (*.xls, *.xlsx, *.xlsm, *.xlsb)"
MS Access Database mysql
"Microsoft Access Driver (*.mdb, *.accdb)" "MySQL ODBC 5.3 Unicode Driver"
Sample Amazon Redshift DSN
"Amazon Redshift (x64)"
> connect=odbcConnect('mysql',uid='******',pwd='*****') #建立连接,星号代表账号和密码
> s=sqlFetch(connect,sqtable ='kuaidaili1') #读取数据
> head(s)
ID IP PORT 匿名度 类型 location responseSpeed lastValidated
1 31 183.146.156.29 9999 ??? HTTP ?????? ?? 3? 2019-11-25 22:31:01
2 32 47.107.38.138 8000 ??? HTTP ?????? ??? 3? 2019-11-25 21:31:02
3 33 110.243.31.209 9999 ??? HTTP ?????? ?? 1? 2019-11-25 20:31:01
4 34 183.166.119.224 9999 ??? HTTP ?????? ?? 3? 2019-11-25 19:31:01
5 35 117.26.44.63 9999 ??? HTTP ?????? ?? 3? 2019-11-25 18:31:01
6 36 123.163.97.154 9999 ??? HTTP ?????? ?? 2? 2019-11-25 17:31:02
> dim(s)
[1] 1500 8
更多信息,查询:
> RShowDoc('RODBC',package='RODBC')
5、获取网页数据
> library(XML)
> tables=readHTMLTable(url)
五、探索性数分析
变量概况
> attributes(airquality)
$names
[1] "Ozone" "Solar.R" "Wind" "Temp" "Month" "Day"
$class
[1] "data.frame"
$row.names
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
[30] 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58
[59] 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87
[88] 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116
[117] 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145
[146] 146 147 148 149 150 151 152 153
> str(airquality)
'data.frame': 153 obs. of 6 variables:
$ Ozone : int 41 36 12 18 NA 28 23 19 8 NA ...
$ Solar.R: int 190 118 149 313 NA NA 299 99 19 194 ...
$ Wind : num 7.4 8 12.6 11.5 14.3 14.9 8.6 13.8 20.1 8.6 ...
$ Temp : int 67 72 74 62 56 66 65 59 61 69 ...
$ Month : int 5 5 5 5 5 5 5 5 5 5 ...
$ Day : int 1 2 3 4 5 6 7 8 9 10 ...
> summary((airquality))
Ozone Solar.R Wind Temp Month Day
Min. : 1.00 Min. : 7.0 Min. : 1.700 Min. :56.00 Min. :5.000 Min. : 1.0
1st Qu.: 18.00 1st Qu.:115.8 1st Qu.: 7.400 1st Qu.:72.00 1st Qu.:6.000 1st Qu.: 8.0
Median : 31.50 Median :205.0 Median : 9.700 Median :79.00 Median :7.000 Median :16.0
Mean : 42.13 Mean :185.9 Mean : 9.958 Mean :77.88 Mean :6.993 Mean :15.8
3rd Qu.: 63.25 3rd Qu.:258.8 3rd Qu.:11.500 3rd Qu.:85.00 3rd Qu.:8.000 3rd Qu.:23.0
Max. :168.00 Max. :334.0 Max. :20.700 Max. :97.00 Max. :9.000 Max. :31.0
NA's :37 NA's :7
> library(Hmisc)
> describe(airquality)
airquality
6 Variables 153 Observations
--------------------------------------------------------------------------------------------------------------------------
Ozone
n missing distinct Info Mean Gmd .05 .10 .25 .50 .75 .90 .95
116 37 67 0.999 42.13 35.28 7.75 11.00 18.00 31.50 63.25 87.00 108.50
lowest : 1 4 6 7 8, highest: 115 118 122 135 168
--------------------------------------------------------------------------------------------------------------------------
Solar.R
n missing distinct Info Mean Gmd .05 .10 .25 .50 .75 .90 .95
146 7 117 1 185.9 102.7 24.25 47.50 115.75 205.00 258.75 288.50 311.50
lowest : 7 8 13 14 19, highest: 320 322 323 332 334
--------------------------------------------------------------------------------------------------------------------------
Wind
n missing distinct Info Mean Gmd .05 .10 .25 .50 .75 .90 .95
153 0 31 0.997 9.958 3.964 4.60 5.82 7.40 9.70 11.50 14.90 15.50
lowest : 1.7 2.3 2.8 3.4 4.0, highest: 16.1 16.6 18.4 20.1 20.7
--------------------------------------------------------------------------------------------------------------------------
Temp
n missing distinct Info Mean Gmd .05 .10 .25 .50 .75 .90 .95
153 0 40 0.999 77.88 10.74 60.2 64.2 72.0 79.0 85.0 90.0 92.0
lowest : 56 57 58 59 61, highest: 92 93 94 96 97
--------------------------------------------------------------------------------------------------------------------------
Month
n missing distinct Info Mean Gmd
153 0 5 0.96 6.993 1.608
lowest : 5 6 7 8 9, highest: 5 6 7 8 9
Value 5 6 7 8 9
Frequency 31 30 31 31 30
Proportion 0.203 0.196 0.203 0.203 0.196
--------------------------------------------------------------------------------------------------------------------------
Day
n missing distinct Info Mean Gmd .05 .10 .25 .50 .75 .90 .95
153 0 31 0.999 15.8 10.26 2.0 4.0 8.0 16.0 23.0 28.0 29.4
lowest : 1 2 3 4 5, highest: 27 28 29 30 31
--------------------------------------------------------------------------------------------------------------------------
> library(fBasics)
载入需要的程辑包:timeDate
载入需要的程辑包:timeSeries
> basicStats(airquality)
Ozone Solar.R Wind Temp Month Day
nobs 153.000000 153.000000 153.000000 153.000000 153.000000 153.000000
NAs 37.000000 7.000000 0.000000 0.000000 0.000000 0.000000
Minimum 1.000000 7.000000 1.700000 56.000000 5.000000 1.000000
Maximum 168.000000 334.000000 20.700000 97.000000 9.000000 31.000000
1. Quartile 18.000000 115.750000 7.400000 72.000000 6.000000 8.000000
3. Quartile 63.250000 258.750000 11.500000 85.000000 8.000000 23.000000
Mean 42.129310 185.931507 9.957516 77.882353 6.993464 15.803922
Median 31.500000 205.000000 9.700000 79.000000 7.000000 16.000000
Sum 4887.000000 27146.000000 1523.500000 11916.000000 1070.000000 2418.000000
SE Mean 3.062848 7.453288 0.284818 0.765222 0.114519 0.716654
LCL Mean 36.062398 171.200384 9.394804 76.370509 6.767209 14.388033
UCL Mean 48.196223 200.662629 10.520229 79.394197 7.219719 17.219811
Variance 1088.200525 8110.519414 12.411539 89.591331 2.006536 78.579721
Stdev 32.987885 90.058422 3.523001 9.465270 1.416522 8.864520
Skewness 1.209866 -0.419289 0.341028 -0.370507 -0.002345 0.002600
Kurtosis 1.112243 -1.004058 0.028865 -0.462893 -1.316746 -1.222441
稀疏性
> library(Matrix)
> j<-sample(1:20,15)
> i<-sample(1:20,15)
> i;j
[1] 19 13 5 7 3 10 6 14 2 11 15 16 1 4 12
[1] 14 16 11 5 4 10 8 3 2 9 18 19 20 15 17
> a<-sparseMatrix(i,j,x=3)
> a
19 x 20 sparse Matrix of class "dgCMatrix"
[1,] . . . . . . . . . . . . . . . . . . . 3
[2,] . 3 . . . . . . . . . . . . . . . . . .
[3,] . . . 3 . . . . . . . . . . . . . . . .
[4,] . . . . . . . . . . . . . . 3 . . . . .
[5,] . . . . . . . . . . 3 . . . . . . . . .
[6,] . . . . . . . 3 . . . . . . . . . . . .
[7,] . . . . 3 . . . . . . . . . . . . . . .
[8,] . . . . . . . . . . . . . . . . . . . .
[9,] . . . . . . . . . . . . . . . . . . . .
[10,] . . . . . . . . . 3 . . . . . . . . . .
[11,] . . . . . . . . 3 . . . . . . . . . . .
[12,] . . . . . . . . . . . . . . . . 3 . . .
[13,] . . . . . . . . . . . . . . . 3 . . . .
[14,] . . 3 . . . . . . . . . . . . . . . . .
[15,] . . . . . . . . . . . . . . . . . 3 . .
[16,] . . . . . . . . . . . . . . . . . . 3 .
[17,] . . . . . . . . . . . . . . . . . . . .
[18,] . . . . . . . . . . . . . . . . . . . .
[19,] . . . . . . . . . . . . . 3 . . . . . .
缺失值
> library(mice)
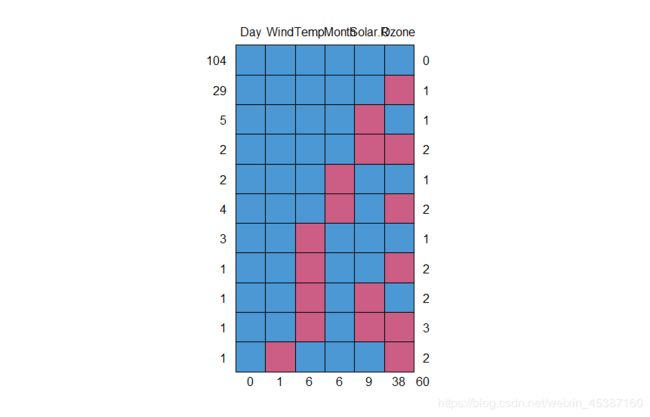
> for (i in 1:10){row=sample(1:60,1);col=sample(1:5,1);airquality[row,col]=NA}
> md.pattern(airquality) #说明:第一列表示数据集中的属于第一列后相应格式的总行数。格式中1代表无缺失,0代表缺失。最后一列代表某行数据中的缺失个数。最后一行代表各变量有缺失的样本个数及总和(最后一个数字)。
Day Wind Temp Month Solar.R Ozone
104 1 1 1 1 1 1 0
29 1 1 1 1 1 0 1
5 1 1 1 1 0 1 1
2 1 1 1 1 0 0 2
2 1 1 1 0 1 1 1
4 1 1 1 0 1 0 2
3 1 1 0 1 1 1 1
1 1 1 0 1 1 0 2
1 1 1 0 1 0 1 2
1 1 1 0 1 0 0 3
1 1 0 1 1 1 0 2
0 1 6 6 9 38 60
相关性
> data("trees")
> head(trees)
Girth Height Volume
1 8.3 70 10.3
2 8.6 65 10.3
3 8.8 63 10.2
4 10.5 72 16.4
5 10.7 81 18.8
6 10.8 83 19.7
> plot(trees)
> dim(trees)
[1] 31 3
> cor(trees$Height,trees$Volume)
[1] 0.5982497
可视化探索
直方图
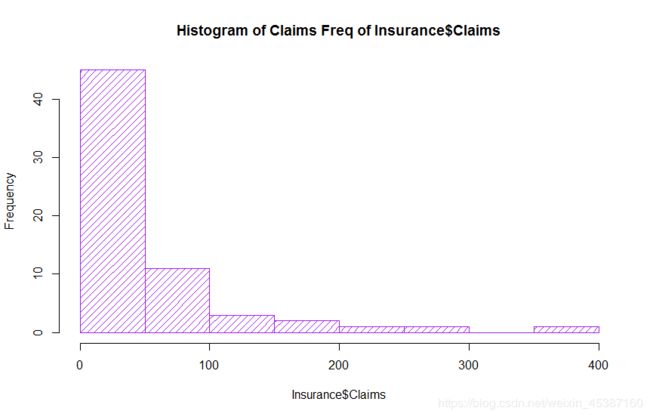
> hist(Insurance$Claims,breaks = 10,freq=TRUE,col='purple',densit=15,main='Histogram of Claims Freq of Insurance$Claims')
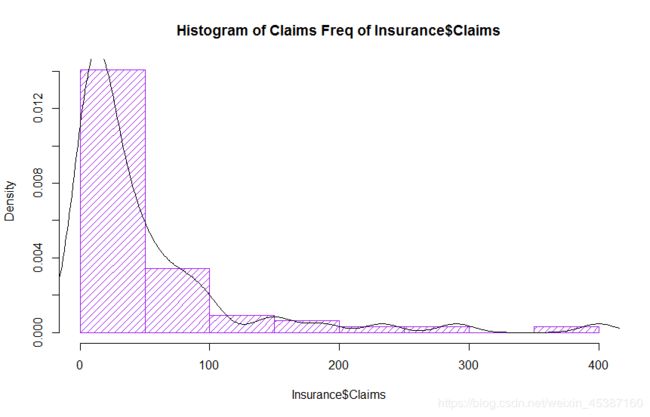
freq参数设为FALSE,则为密度直方图。
> hist(Insurance$Claims,breaks = 10,freq=FALSE,col='purple',densit=15,main='Histogram of Claims Freq of Insurance$Claims')
> lines(density(Insurance$Claims))
累积分布图
> library(Hmisc)
> data(Insurance)
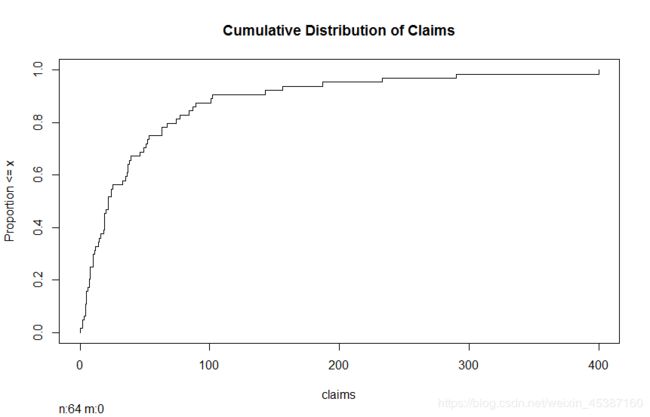
> Ecdf(Insurance$Claims,xlab='claims',main='Cumulative Distribution of Claims')
> data_plot<-with(Insurance,rbind(data.frame(var1=Insurance$Claims[Age=="<25"],var2="<25"),data.frame(var1=Insurance$Claims[Age=="25-29"],var2="25-29"),data.frame(var1=Insurance$Claims[Age=="30-35"],var2="30-35"),data.frame(var1=Insurance$Claims[Age==">35"],var2=">35")))
> class(data_plot)
[1] "data.frame"
> Ecdf(data_plot$var1,group=data_plot$var2,label.curves = 1:4,xlab='Claims',lty=2,main='Cumulative Distribution of Claims by Age') #按照年龄分组作累积图
> Ecdf(Insurance$Claims,add=TRUE) #添加总体分布图以便观察
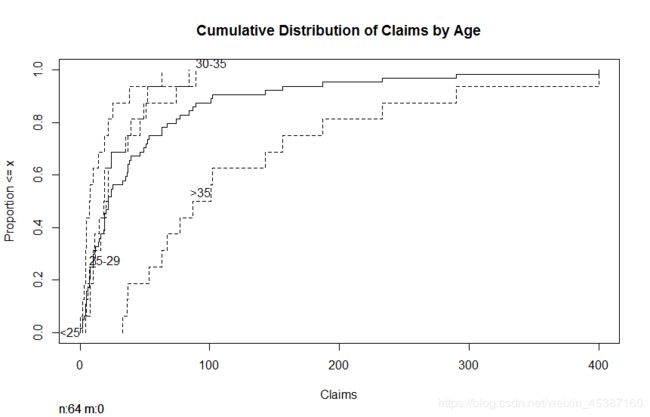
以上代码可以简化为:
Ecdf(Insurance$Claims,group=Insurance$Age,main='Cumulative Distribution of Claims by Age',xlab='Claims',lty=4)
箱型图
> library(MASS)
> data(Insurance)
> claim_bp<-boxplot(Insurance$Claims)
> claim_bp
$stats
[,1]
[1,] 0
[2,] 9
[3,] 22
[4,] 58
[5,] 102
attr(,"class")
1
"integer"
$n
[1] 64
$conf
[,1]
[1,] 12.3225
[2,] 31.6775
$out
[1] 156 400 233 290 143 187
$group
[1] 1 1 1 1 1 1
$names
[1] "1"
> class(claim_bp)
[1] "list"
> claims.unusual<-Insurance$Claims[which(Insurance$Claims>102)]
> claims.unusual
[1] 156 400 233 290 143 187
> claims_points<-as.matrix(claims.unusual,6)#转化成矩阵,以便使用rbind拼接如下数据
> claims_text<-rbind(claims_points,mean(Insurance$Claims),claim_bp$stats) #数据拼接
> points(x=1,y=mean(Insurance$Claims),pch=2)
> for(i in 1:length(claims_text))text(x=1.1,y=claims_text[i,],labels=claims_text[i,]) #text用于标注,参数lables
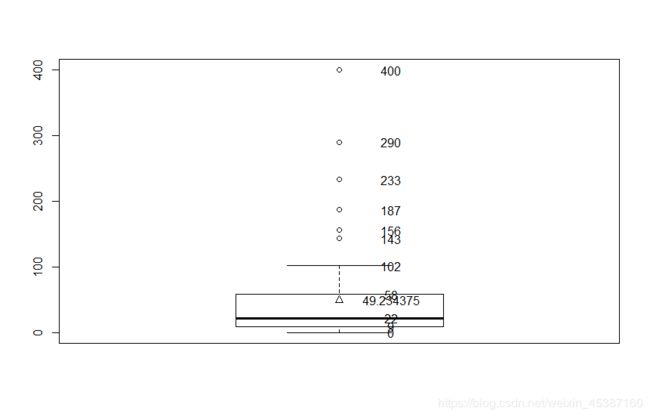
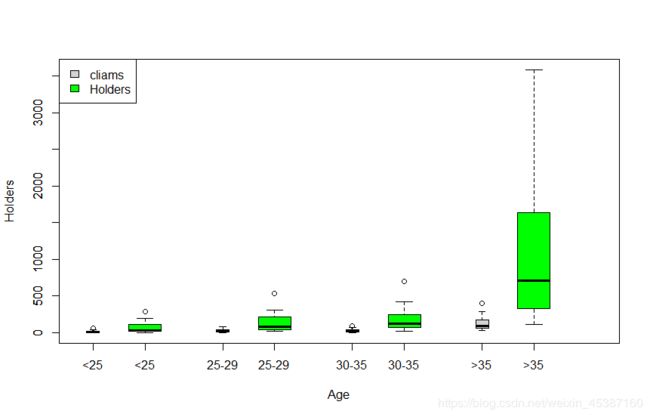
> boxplot(var1~var2,data=data_plot,horizontal = TRUE,main='Distrubution of Claims by Age',xlab="Claims",ylab='Age') #按年龄分组作图,使用上述data_plot数据,注意此处函数格式
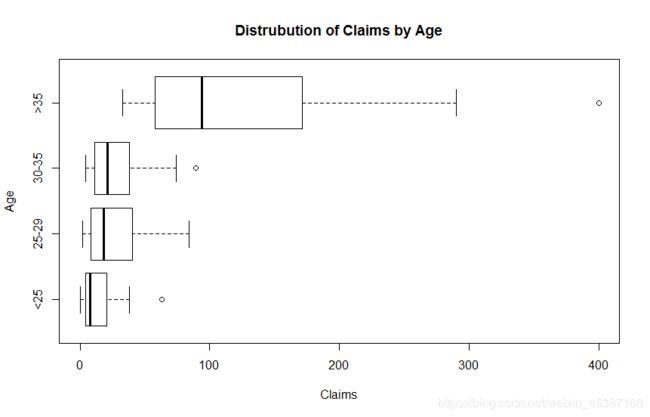
或直接用如下语句:
boxplot(Insurance$Claims~Insurance$Age,horizontal = TRUE,main='Distrubution of Claims by Age',xlab="Claims",ylab = 'Age')
> boxplot(Holders~Age,data=Insurance,boxwex=0.25,at=1:4+0.2,col='green',main="Distruibuton of Claims&Holders by Age")#加入Holders变量观察。
> boxplot(var1~var2,data=data_plot,boxwex=0.1,add=TRUE,at=1:4-0.2,xlab='Age',ylab='Claims&Holders',col='lightgrey')
> legend(x='topleft',c('cliams','Holders'),fill=c("lightgrey","green"))
条形图
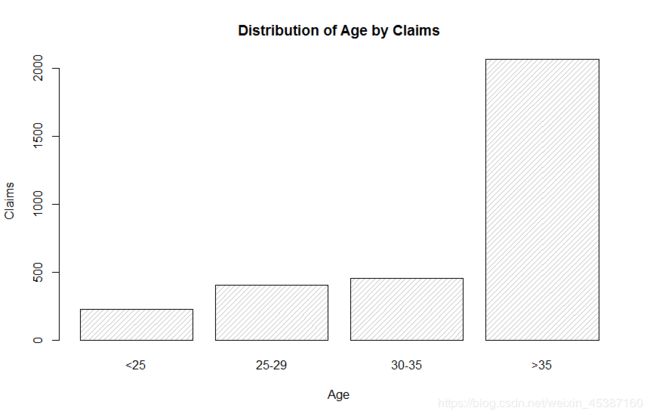
> Claims_age=with(Insurance,c(sum(Claims[which(Age=='<25')]),sum(Claims[which(Age=='25-29')]),sum(Claims[which(Age=='30-35')]),sum(Claims[which(Age=='>35')])))
> Claims_age
[1] 229 404 453 2065
> barplot(Claims_age,names.arg=c("<25","25-29","30-35",">35"),main='Distribution of Age by Claims',density=rep(20,4),xlab='Age',ylab='Claims') #参数names.arg
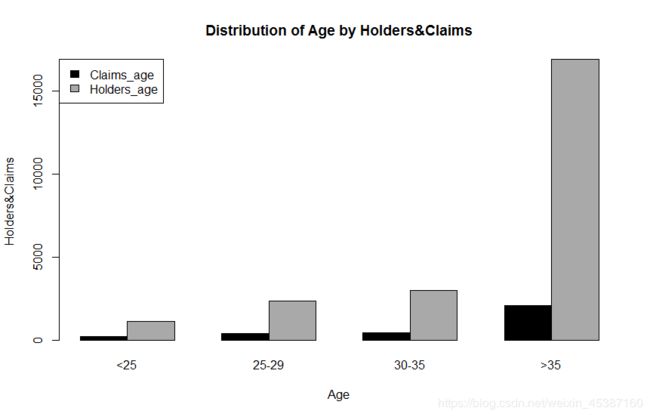
> Holders_age=with(Insurance,c(sum(Holders[which(Age=='<25')]),sum(Holders[which(Age=='25-29')]),sum(Holders[which(Age=='30-35')]),sum(Holders[which(Age=='>35')])))
> data_bar=rbind(Claims_age,Holders_age)
> barplot(data_bar,xlab='Age',ylab='Holders&Claims',beside=TRUE,main='Distribution of Age by Holders&Claims',names.arg=c("<25","25-29","30-35",">35"),col=c('black','darkgrey'))
> legend(x='topleft',rownames(data_bar),fill=c('black','darkgrey'))
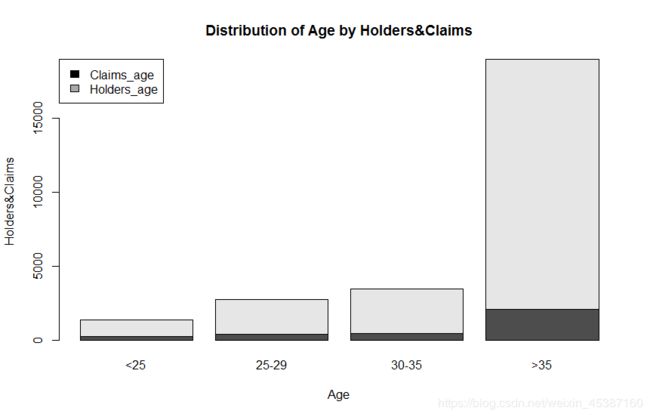
> barplot(data_bar,xlab='Age',ylab='Holders&Claims',beside=FALSE,main='Distribution of Age by Holders&Claims',names.arg=c("<25","25-29","30-35",">35")) #beside FALSE为堆叠图
> legend(x='topleft',rownames(data_bar),fill=c('black','darkgrey'))
> dotchart(data_bar,xlab='Claims&Holders',pch=1:2,main='Age Distributio by Claims and Holders')
> legend(x=14000,y=15,'<25',bty='n')
> legend(x=14000,y=11,'25-29',bty='n')
> legend(x=14000,y=7,'30-35',bty='n')
> legend(x=14000,y=3,'>35',bty='n')

六、数据预处理
1、数据加载
> data("nhanes2")
> head(nhanes2)
age bmi hyp chl
1 20-39 NA <NA> NA
2 40-59 22.7 no 187
3 20-39 NA no 187
4 60-99 NA <NA> NA
5 20-39 20.4 no 113
6 60-99 NA <NA> 184
> dim(nhanes2)
[1] 25 4
> md.pattern(nhanes2)
age hyp bmi chl
13 1 1 1 1 0
3 1 1 1 0 1
1 1 1 0 1 1
1 1 0 0 1 2
7 1 0 0 0 3
0 8 9 10 27
> attributes(nhanes2)
$names
[1] "age" "bmi" "hyp" "chl"
$row.names
[1] "1" "2" "3" "4" "5" "6" "7" "8" "9" "10" "11" "12" "13" "14" "15" "16" "17" "18" "19" "20" "21" "22" "23"
[24] "24" "25"
$class
[1] "data.frame"
> str(nhanes2)
'data.frame': 25 obs. of 4 variables:
$ age: Factor w/ 3 levels "20-39","40-59",..: 1 2 1 3 1 3 1 1 2 2 ...
$ bmi: num NA 22.7 NA NA 20.4 NA 22.5 30.1 22 NA ...
$ hyp: Factor w/ 2 levels "no","yes": NA 1 1 NA 1 NA 1 1 1 NA ...
$ chl: num NA 187 187 NA 113 184 118 187 238 NA ...
> summary(nhanes2)
age bmi hyp chl
20-39:12 Min. :20.40 no :13 Min. :113.0
40-59: 7 1st Qu.:22.65 yes : 4 1st Qu.:185.0
60-99: 6 Median :26.75 NA's: 8 Median :187.0
Mean :26.56 Mean :191.4
3rd Qu.:28.93 3rd Qu.:212.0
Max. :35.30 Max. :284.0
NA's :9 NA's :10
2、数据清理
用统计图来探索数据规律,审核数据质量。
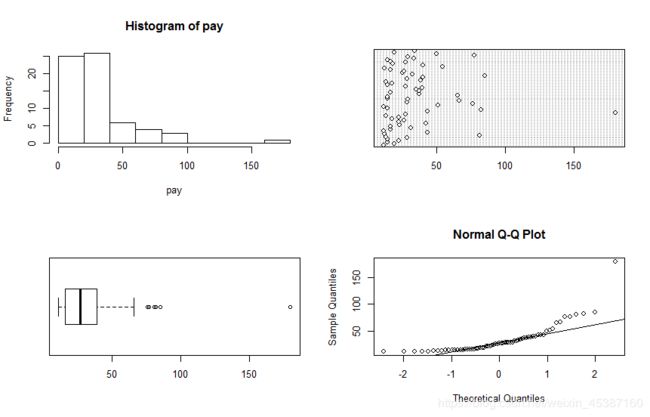
> pay<-c(11,19,14,22,14,28,13,81,12,43,11,16,31,16,23,42,22,26,17,22,13,27,180,43,82,14,11,51,76,28,66,29,14,14,65,37,16,37,35,39,27,14,17,13,38,28,40,85,32,25,26,16,12,54,40,18,27,16,14,33,29,77,50,19,34)
> par(mfrow=c(2,2))
> hist(pay)
> dotchart(pay)
> boxplot(pay,horizontal=TRUE)
> qqnorm(pay);qqline(pay)
从图中很容易看出明显有问题的数据
缺失值:
缺失值判断
> sum(is.na(nhanes2))
[1] 27
> sum(complete(nhanes2))
Error in complete(nhanes2) : 'data' not of class 'mids'
> sum(complete.cases(nhanes2))
[1] 13
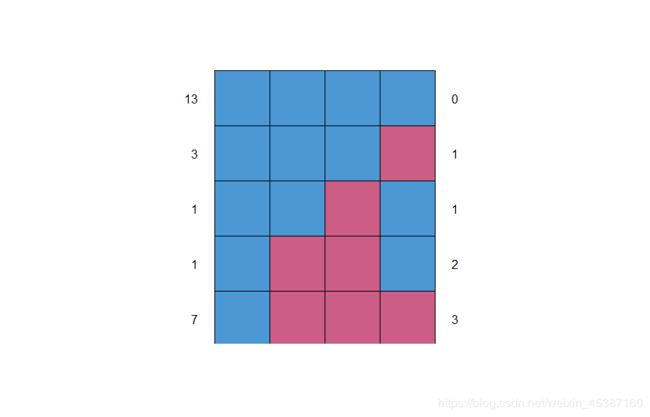
> md.pattern(nhanes2) #参考上文提及处
age hyp bmi chl
13 1 1 1 1 0
3 1 1 1 0 1
1 1 1 0 1 1
1 1 0 0 1 2
7 1 0 0 0 3
0 8 9 10 27
缺失值处理:
删除或者插补,如均值茶茶布,回顾插补,二阶插补,抽样填补等。
噪声数据
> library(outliers)
> outlier(pay)
[1] 180
> outlier(pay,opposite = FALSE)
[1] 180
> outlier(pay,opposite = TRUE)
[1] 11
> outlier(pay,logical=TRUE)
[1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[20] FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[39] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[58] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
去掉噪声:
> set.seed(1);s1=.Random.seed
> x=rnorm(20)
> x
[1] -0.62645381 0.18364332 -0.83562861 1.59528080 0.32950777 -0.82046838 0.48742905 0.73832471 0.57578135
[10] -0.30538839 1.51178117 0.38984324 -0.62124058 -2.21469989 1.12493092 -0.04493361 -0.01619026 0.94383621
[19] 0.82122120 0.59390132
> x=sort(x)
> x
[1] -2.21469989 -0.83562861 -0.82046838 -0.62645381 -0.62124058 -0.30538839 -0.04493361 -0.01619026 0.18364332
[10] 0.32950777 0.38984324 0.48742905 0.57578135 0.59390132 0.73832471 0.82122120 0.94383621 1.12493092
[19] 1.51178117 1.59528080
> dim(x)=c(4,5)
> x[1,]=apply(x,1,mean)[1] #用第一行均值代替第一行的数据
> x[2,]=apply(x,1,mean)[2] #用第二行均值代替第二行的数据
> x[3,]=apply(x,1,mean)[3] #用第三行均值代替第三行的数据
> x[4,]=apply(x,1,mean)[4] #用第四行均值代替第四行的数据
> x
[,1] [,2] [,3] [,4] [,5]
[1,] -0.2265359 -0.2265359 -0.2265359 -0.2265359 -0.2265359
[2,] 0.1814646 0.1814646 0.1814646 0.1814646 0.1814646
[3,] 0.3549094 0.3549094 0.3549094 0.3549094 0.3549094
[4,] 0.4522574 0.4522574 0.4522574 0.4522574 0.4522574