单目深度估计 | Real-Time Monocular Depth Estimation using Synthetic Data 学习笔记
文章目录
- 1. 摘要
- 2. 创新点和局限性
- 3 研究
- 3.1 阶段1-单目深度估计模型。
- 3.1.1 损失函数
- 3.1.2 训练细节
- 3.2 阶段2-通过风格迁移的域自适应
- 3.2.1 损失函数
- 3.2.2 训练细节
- 5 结论
- 深度估计系列文章:
会议:CVPR 2018
标题:《Real-Time Monocular Depth Estimation using Synthetic Data with Domain Adaptation via Image Style Transfer》
论文链接: http://openaccess.thecvf.com/content_cvpr_2018/papers/Atapour-Abarghouei_Real-Time_Monocular_Depth_CVPR_2018_paper.pdf
本文仅作为个人学习笔记分享,图片来自于论文,如有侵权,请联系删除。
1. 摘要
基于学习的方法预测单目相机的深度,这些年逐渐的呈上升趋势。然而这些方法要么依赖于大量已标定的深度数据,或者使用二次监控信号预测差距作为中间步骤,会导致模糊和伪影等其他现象。 利用完美像素点的合成数据训练一个深度预测模型能够解决这些问题但是会引入信号-偏差的问题。这就是为什么不能将基于合成数据训练的模型运用到实际情况。 随着图像风格迁移的发展以及它和领域适应(domain adaptation)间的联系,我们利用的风格迁移和对抗训练经过在大量生成数据上训练模型,之后从单张真实世界的彩色图片预测图片每个像素点的深度。实验结果表明,我们的方法比当今最先进的技术效果更好。
2. 创新点和局限性
论文的创新点主要为:
-
- synthetic depth prediction, 一个具有跳跃连接的轻量级网络直接监督训练的模型,可以根据高质量的合成的综合深度训练数据来预测深度。
-
- domain adaptation via style transfer,通过风格迁移进行域自适应。通过样式转换来解决域偏差问题。
-
- efficacy, 一种新的高效的估计像素深度的单眼相机深度估计方法。
-
- reproducibility,再现性。基于公开易获取的数据集,算法简单高效。
局限性:
光照突然变化和风格迁移的饱和度突然变化时,效果不太好。
相关工作包括单目深度估计,域自适应 和 图像风格迁移三个方面

3 研究
我们的研究包括两个阶段,分别为两个同时训练的独立的模型。
3.1 阶段1-单目深度估计模型。
基于为游戏应用程序设计的图形化城市环境图片合成数据集训练深度估计模型。
3.1.1 损失函数

重建损失函数,生产优化模糊平均所有可能的值,为不是选择一个锐度。

3.1.2 训练细节
通过Pytorch上实现训练,参数为(momentum β1 = 0.5, β2 = 0.999, initial learning rate α = 0.0002),联合损失系数公式中λ = 0.99。
3.2 阶段2-通过风格迁移的域自适应
3.2.1 损失函数


3.2.2 训练细节
此网络由两个卷积层,9个残差模块和两个up卷积将图像变换到原始的输入尺寸。
通过Pytorch上实现训练了,参数为(momentum β1 = 0.5, β2 = 0.999, and initial learning rate α = 0.0001),联合损失系数从公式7中得到。这里λ = 10。


4 实验结果
实验环境:GeForce GTX 1080 Ti, 耗时22.7ms, 帧率约为44fps




图7 模型结合后,使用在本地城市环境中捕获的数据,我们在不进行任何数据训练的情况下生成了清晰、连贯、可信的视觉深度图。
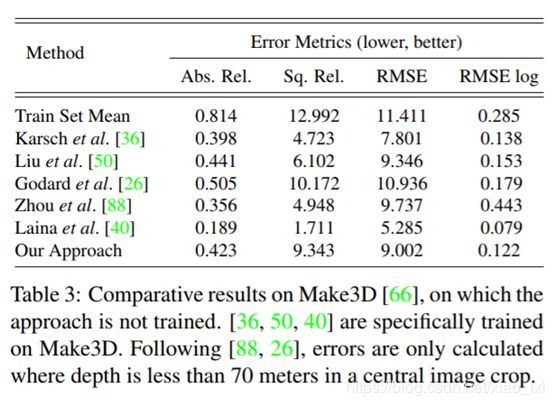

Table3 是将我们的模型与目前最先进的几个基于Make3D数据集进行训练的单目深度估计模型对比,我们的方法在数值上不占优势。
图8,我们训练好的模型在Make3D数据集上测试结果。尽管这个数据集和我们训练所用的数据集不同,但效果还是很好的。

图9 失败的例子,大多是因为曝光过强和阴影区,说明光照突然变化和风格迁移的饱和度突然变化时,效果不太好。
5 结论
我们曾经提出了一种基于学习的单目深度估计方法。利用为游戏应用程序设计的图形化城市环境图片合成数据,以监督的方式训练出一个高效的深度估计模型。然而,由于这两组数据所属的域分布大不相同,这个模型不能很好的预测真实场景。依靠风格迁移和分布之间的距离这些新的理论,我们提出了一种基于GAN风格迁移的算法,调整我们的真实数据来适合深度估计模型中生成器近似的分布。虽然一些孤立的问题仍然存在,实验结果证明我们的方法在处理同一问题上比目前最先进的方法效果更好。
深度估计系列文章:
单目深度估计 | Learning Depth from Monocular Videos using Direct Methods
单目深度估计 | Real-Time Monocular Depth Estimation using Synthetic Data with Domain Adaptation via Image
单目深度估计 | Depth from Videos in the Wild: Unsupervised Monocular Depth Learning from Unknown Cameras