论文笔记 | VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE -SCALE IMAGE RECOGNITION
Authors
Karen Simonyan & Andrew Zisserman

Karen Simonyan
Abstract
In this work we investigate the effect of the convlutional network depth on its accuracy in the large-scale image recognation.
1 Introduction
A number of attempts have been made to improve the original architecture of Krizhevsky et al. in a bid to achieve better accuracy:
1. ZF(zeiler&Fergus) overFeat(Sermanet et al.) utilised smaller receptive window size and smaller stride of the first convolutional layer.
2. densely over the whole image and over multiple scales.
3. this paper: Depth
2 ConvNet configurations
2.1 Architecture
We note that none of our networks contain Local Response Normalisation (LRN), as will be shown in Sect. 4 , Such normalisation dees not imporve the performance of the ILSVRC dataset, but lead to increased memory consumption and computation time.
2.2 Configurations
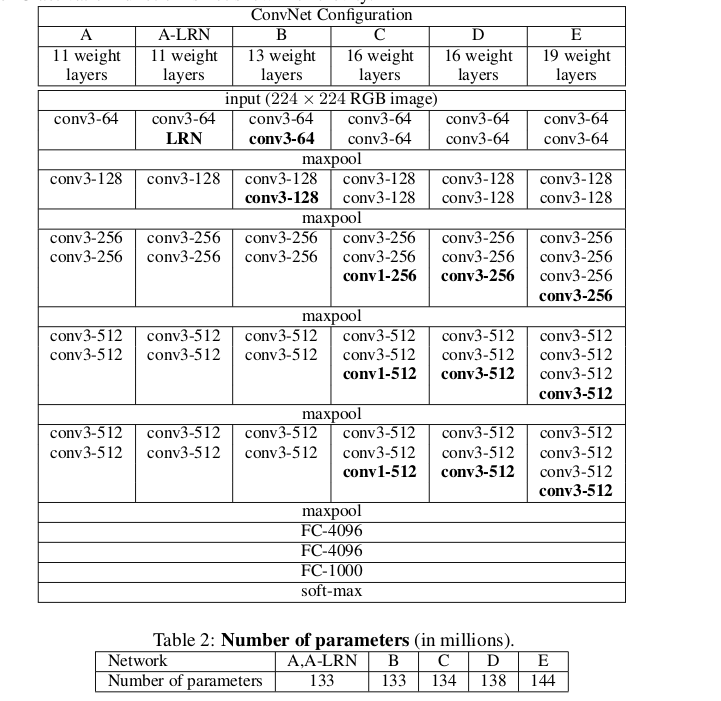
2.3 Discussion
- What we have gained by using a stack of three 3x3 conv.layers instead of a single 7x7 layer:
- we incorporate three non-linear rectification layers instead of a single one, which makes the decision function more discreiminative.
- We decrease the number of parameters, this can be seen as imposing a regularisation on the 7x7 filters, forcing them to have a decomposition through the 3x3 filters(with non-linearity injected in between)
- The incorporation of 1x1 filters is a way to increase the non-linearity of the decision function without affecting the receptive fields .
3 Classification Framework
3.1 training
batch size: 256
momentum: 0.9
L2:5e-4
fc drop :0.5
lr:0.01 then decreased by a feator of 10 when the validation set accuracy stopped after 370k
pre-initialisation: A <-random initialisation; deeper<-A’s first three and last three fc layers. but it is possible to inilialise the weights with out pre-training by using the random initialisation procedure of Glorot:
Glorot, X. and Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proc.
AISTATS, volume 9, pp. 249–256, 2010.Training Image size:
let s be the smallest side of the trining image.
We consider two approaches for setting the training scales S:
1. fix S : two scales: S=256 and 384
2. multi-scale training: each training image is individually rescaled by randomly sampling S form a certain rangesmin, smax
3.2 Testing
- rescaled to a pre-defined smallest image side ,Q, not necessarily equal to the training scale S, we can use several values of Q for each S leads to improved performance.
?
namely, the fc layers are first converted to convolutional layers.(????)
2. using a large set of crops, as done by Szegedy , can lead to improved accuracy. while, we believe that in practice the increase computation time of multiple crops does not justify the potential gains in accuracy.
3.3 implementation details
C++ caffe;
multi-GPU: exploits data parallelism, and it carried out by splitting each batch of training images into several GPU batches, processed in parallel on each GPU, and then average them to obtain the gradient of the full batch.
While more sophisticated methods of speeding up ConvNet training have been proposed, which employ models of speeding up model and data parallelism for different layers of the net.
4 Classification experiments
4.1 Single scale evaluation
- LRN does not improve on the model A without any normalisation layers;
- It is important to capture spaitial context by using conv. filters with non-trivial receptive fields: C better than B, D is better than C(c,d as the same depth ,but d use 3x3 instead of 1x1 in c)
- The error rate of our architecture saturates when the depth reaches 19 layers
- A deep net with small filters outperforms a shallow net with larger filters.
- Scale jittering at training time(s ∈ [256,512]) leads to significantly better results than training on image with fixed smalles side(s=256 or 384), even though a single scale is used at test time.

4.2 Multi-scale evaluation
We now assess the effect of scale jittering at test time.

It indicated that scale jittering in test time Lead to better performance.
4.3 Multi-crop evaluation
dese & multi-crop evaluation
(see sect.3.2 for detail)
We hypothesize that this is due to a different treatment of convolution boundary conditions.

4.4 convnet Fusion

5 conclusion
depth is important in visual representations
A localisation
We adopt the approach of overfeat.
A.1 localisation convnet
we use the last fully connected layer predicts the bounding box location instead of the class scores.
There is a choice of whether the bounding box prediction is shared across all classes(scr=single class regress )or is class-specific(per=class regress) In the former case , the last layer is 4D, while the latter is 4000D(for 1000 classes)
we did not use the multiple pooling offsets technique of overfeat
A.2 experiments
PCR outperforms the SCR
fine-tuning all layers noticeably better than fine-tuning only the fc layers
Testing at several scales and combing the predictions of multiple networks further imporves the performance.
conclusion
- Authors
- Abstract
- Introduction
- ConvNet configurations
- 1 Architecture
- 2 Configurations
- 3 Discussion
- Classification Framework
- 1 training
- 2 Testing
-
- 3 implementation details
- Classification experiments
- 1 Single scale evaluation
- 2 Multi-scale evaluation
- 3 Multi-crop evaluation
- 4 convnet Fusion
- conclusion
- A localisation
- A1 localisation convnet
- A2 experiments
- conclusion