Flink使用Broadcast State实现流处理配置实时更新
来源链接:http://shiyanjun.cn/archives/1857.html,感谢 Yanjun 的分享。
Broadcast State是Flink支持的一种Operator State。使用Broadcast State,可以在Flink程序的一个Stream中输入数据记录,然后将这些数据记录广播(Broadcast)到下游的每个Task中,使得这些数据记录能够为所有的Task所共享,比如一些用于配置的数据记录。这样,每个Task在处理其所对应的Stream中记录的时候,读取这些配置,来满足实际数据处理需要。
另外,在一定程度上,Broadcast State能够使得Flink Job在运行过程中与外部的其他系统解耦合。比如,通常Flink会使用YARN来管理计算资源,使用Broadcast State就可以不用直接连接MySQL数据库读取相关配置信息了,也无需对MySQL做额外的授权操作。因为在一些场景下,会使用Flink on YARN部署模式,将Flink Job运行的资源申请和释放交给YARN去管理,那么就存在Hadoop集群节点扩缩容的问题,如新加节点可能需要对一些外部系统的访问,如MySQL等进行连接操作授权,如果忘记对MysQL访问授权,Flink Job被调度到新增的某个新增节点上连接并读取MySQL配置信息就会出错。
Broadcast State API
通常,我们首先会创建一个Keyed或Non-Keyed的Data Stream,然后再创建一个Broadcasted Stream,最后通过Data Stream来连接(调用connect方法)到Broadcasted Stream上,这样实现将Broadcast State广播到Data Stream下游的每个Task中。
如果Data Stream是Keyed Stream,则连接到Broadcasted Stream后,添加处理ProcessFunction时需要使用KeyedBroadcastProcessFunction来实现,下面是KeyedBroadcastProcessFunction的API,代码如下所示:
public abstract class KeyedBroadcastProcessFunction extends BaseBroadcastProcessFunction {
public abstract void processElement(final IN1 value, final ReadOnlyContext ctx, final Collector out) throws Exception;
public abstract void processBroadcastElement(final IN2 value, final Context ctx, final Collector out) throws Exception;
} 上面泛型中的各个参数的含义,说明如下:
- KS:表示Flink程序从最上游的Source Operator开始构建Stream,当调用keyBy时所依赖的Key的类型;
- IN1:表示非Broadcast的Data Stream中的数据记录的类型;
- IN2:表示Broadcast Stream中的数据记录的类型;
- OUT:表示经过KeyedBroadcastProcessFunction的processElement()和processBroadcastElement()方法处理后输出结果数据记录的类型。
如果Data Stream是Non-Keyed Stream,则连接到Broadcasted Stream后,添加处理ProcessFunction时需要使用BroadcastProcessFunction来实现,下面是BroadcastProcessFunction的API,代码如下所示:
public abstract class BroadcastProcessFunction extends BaseBroadcastProcessFunction {
public abstract void processElement(final IN1 value, final ReadOnlyContext ctx, final Collector out) throws Exception;
public abstract void processBroadcastElement(final IN2 value, final Context ctx, final Collector out) throws Exception;
} 上面泛型中的各个参数的含义,与前面KeyedBroadcastProcessFunction的泛型类型中的后3个含义相同,只是没有调用keyBy操作对原始Stream进行分区操作,就不需要KS泛型参数。
具体如何使用上面的BroadcastProcessFunction,接下来我们会在通过实际编程,来以使用KeyedBroadcastProcessFunction为例进行详细说明。
使用场景实践
用户购物路径长度跟踪场景描述
我们先描述一下使用Broadcast State的场景:
针对用户在手机App上操作行为的事件,通过跟踪用户操作来实时触发指定的操作。假设我们关注一个用户在App上经过多次操作之后,比如浏览了几个商品、将浏览过的商品加入购物车、将购物车中的商品移除购物车等等,最后发生了购买行为,那么对于用户从开始到最终达成购买所进行操作的行为的次数,我们定义为用户购物路径长度,通过这个概念假设可以通过推送优惠折扣权限、或者适时地提醒用户使用App等运营活动,能够提高用户的复购率,这个是我们要达成的目标。
事件均以指定的格式被实时收集上来,我们统一使用JSON格式表示,例如,一个用户在App上操作行为我们定义有如下几种:
- VIEW_PRODUCT
- ADD_TO_CART
- REMOVE_FROM_CART
- PURCHASE
可以很容易根据上面的事件类型定义,理解每种类型的含义。用户在最终达成下单购买操作过程中,会经过一系列操作:VIEW_PRODUCT、ADD_TO_CART、REMOVE_FROM_CART的不同组合,每个也可以重复操作多次,最终发生购买类型PURCHASE的行为,然后我们对该用户计算其购物路径长度,通过计算该度量来为外部业务系统提供运营或分析活动的基础数据,外部系统可以基于该数据对用户进行各种运营活动。
例如,下面是几个示例事件的记录,如下所示:
{"userId":"d8f3368aba5df27a39cbcfd36ce8084f","channel":"APP","eventType":"VIEW_PRODUCT","eventTime":"2018-06-12_09:27:11","data":{"productId":196}}
{"userId":"d8f3368aba5df27a39cbcfd36ce8084f","channel":"APP","eventType":"ADD_TO_CART","eventTime":"2018-06-12_09:43:18","data":{"productId":126}}
{"userId":"d8f3368aba5df27a39cbcfd36ce8084f","channel":"APP","eventType":"VIEW_PRODUCT","eventTime":"2018-06-12_09:27:11","data":{"productId":126}}
{"userId":"d8f3368aba5df27a39cbcfd36ce8084f","channel":"APP","eventType":"PURCHASE","eventTime":"2018-06-12_09:30:28","data":{"productId":196,"price":600.00,"amount":600.00}}另外,因为App注册用户很多,不可能所有的用户发生的购物行为路径都能满足特定条件,假设对于购物路径长度很短的,很可能该用户使用App时目的性很强,很快就下单购买,对于这类用户我们暂时先不想对他们做任何运营活动,所以进行流数据处理时需要输入对应的路径长度的配置值,来限制这种情况。而且,随着时间的推移,该值可能会根据实际业务需要而发生变化,我们希望整个Flink计算程序能够动态获取并更新对应的配置值,配置字符串也是JSON格式,示例如下:
{"channel":"APP","registerDate":"2018-01-01","historyPurchaseTimes":0,"maxPurchasePathLength":3}这时,使用Flink提供的Broadcast State特性就非常方便。另外,我们可以假设存在多个不同的渠道,这里只会以APP渠道为例进行说明实践。
假设满足大于配置的最大购物路径长度的用户,我们计算出该用户购物的路径长度,同时将其输出到另一个指定的Kafka Topic中,以便其它系统消费该Topic,从而对这些用户进行个性化运营。例如,计算得到的结果格式,除了一个购物路径长度外,还分别统计了达成购买过程中各个操作行为的个数,JSON格式字符串如下所示:
{"userId":"a9b83681ba4df17a30abcf085ce80a9b","channel":"APP","purchasePathLength":9,"eventTypeCounts":{"ADD_TO_CART":1,"PURCHASE":1,"VIEW_PRODUCT":7}}后续外部系统如何使用该结果数据,我们暂时不去过多考虑。
基本设计
基于上面描述的使用场景,为了直观表达系统的技术架构、基本组件和数据处理流程,基本设计如下图所示:
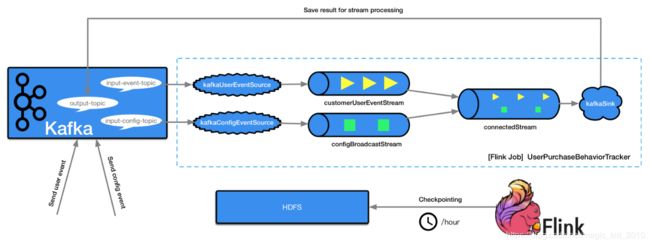
如上图所示,正是我们计划实现流处理流程,对应的核心要点,描述如下:
- 用户操作行为事件实时写入到Kafka的Topic中,通过input-event-topic参数指定。
- 基于input-event-topic参数指定的Topic,创建一个Flink Source Operator,名称为kafkaUserEventSource。
- 基于kafkaUserEventSource创建一个Data Stream,名称为customerUserEventStream。
- 渠道配置信息,根据实际业务需要更新,并实时写入到Kafka的Topic中,通过input-config-topic参数指定。
- 基于input-config-topic参数指定的Topic,创建一个Flink Source Operator,名称为kafkaConfigEventSource。
- 基于kafkaConfigEventSource创建一个Broadcast Stream,名称为configBroadcastStream。
- 将上述创建的两个Stream,通过customerUserEventStream连接到configBroadcastStream,得到新的connectedStream。
- 基于connectedStream设置ProcessFunction实现,来处理新的Stream中的数据记录,可以在每个Task中基于获取到统一的配置信息,进而处理用户事件。
- 将处理结果发送到Flink Sink Operator,名称为kafkaSink。
- kafkaSink将处理的结果,保存到Kafka的Topic中,通过output-topic指定Topic名称。
另外,在Flink Job中开启Checkpoint功能,每隔1小时对Flink Job中的状态进行Checkpointing,以保证流处理过程发生故障后,也能够恢复。
实现Flink Job主流程处理
我们把输入的用户操作行为事件,实时存储到Kafka的一个Topic中,对于相关的配置也使用一个Kafka Topic来存储,这样就会构建了2个Stream:一个是普通的Stream,用来处理用户行为事件;另一个是Broadcast Stream,用来处理并更新配置信息。计算得到的最终结果,会保存到另一个Kafka的Topic中,供外部其他系统消费处理以支撑运营或分析活动。
- 输入参数
Flink程序的输入参数格式,代码如下所示:
LOG.info("Input args: " + Arrays.asList(args));
// parse input arguments
final ParameterTool parameterTool = ParameterTool.fromArgs(args);
if (parameterTool.getNumberOfParameters() < 5) {
System.out.println("Missing parameters!\n" +
"Usage: Kafka --input-event-topic --input-config-topic --output-topic " +
"--bootstrap.servers " +
"--zookeeper.connect --group.id ");
return;
} 其中对应上面描述的3个Topic,配置Key分别为input-event-topic、input-config-topic、output-topic,另外还有与Kafka集群建立连接所必需bootstrap.servers和zookeeper.connect这2个参数,具体含义不再详述,可以参考其他文档。
- 配置Flink环境
需要对Flink的相关运行配置进行设置,包括Checkpoint相关配置,代码如下所示:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new FsStateBackend(
"hdfs://namenode01.td.com/flink-checkpoints/customer-purchase-behavior-tracker"));
CheckpointConfig config = env.getCheckpointConfig();
config.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
config.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
config.setCheckpointInterval(1 * 60 * 60 * 1000);
env.getConfig().setGlobalJobParameters(parameterTool); // make parameters available in the web interface
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);指定Flink Job运行过程中开启Checkpoint功能,并且Checkpoint数据存储到指定的HDFS路径hdfs://namenode01.td.com/flink-checkpoints/customer-purchase-behavior-tracker下面,并且Checkpoint时间间隔为1小时。Flink处理过程中使用的TimeCharacteristic,我们使用了TimeCharacteristic.EventTime,也就是根据事件本身自带的时间来进行处理,用来生成Watermark时间戳,对应生成Watermark的实现我们使用了BoundedOutOfOrdernessTimestampExtractor,即设置一个容忍事件乱序的最大时间长度,实现代码如下所示:
private static class CustomWatermarkExtractor extends BoundedOutOfOrdernessTimestampExtractor {
public CustomWatermarkExtractor(Time maxOutOfOrderness) {
super(maxOutOfOrderness);
}
@Override
public long extractTimestamp(UserEvent element) {
return element.getEventTimestamp();
}
} - 创建用户行为事件Stream
创建一个用来处理用户在App上操作行为事件的Stream,并且使用map进行转换,使用keyBy来对Stream进行分区,实现代码如下所示:
// create customer user event stream
final FlinkKafkaConsumer010 kafkaUserEventSource = new FlinkKafkaConsumer010<>(
parameterTool.getRequired("input-event-topic"),
new SimpleStringSchema(), parameterTool.getProperties());
// (userEvent, userId)
final KeyedStream customerUserEventStream = env
.addSource(kafkaUserEventSource)
.map(new MapFunction() {
@Override
public UserEvent map(String s) throws Exception {
return UserEvent.buildEvent(s);
}
})
.assignTimestampsAndWatermarks(new CustomWatermarkExtractor(Time.hours(24)))
.keyBy(new KeySelector() {
@Override
public String getKey(UserEvent userEvent) throws Exception {
return userEvent.getUserId();
}
}); 上面从Kafka的Topic中读取的事件都是JSON格式字符串,我们调用map将其转换成UserEvent对象,继续调用assignTimestampsAndWatermarks()方法设置Watermark,调用keyBy()方法设置根据用户ID(userId)来对Stream中的数据记录进行分区,即属于同一个用户的操作行为事件会发送到同一个下游的Task中进行处理,这样可以在Task中完整地保存某个用户相关的状态信息,从而等到PURCHASE类型的购物操作事件到达后进行一次计算,如果满足配置条件则处理缓存的事件并输出最终结果。
- 创建配置事件Stream
创建一个用来动态读取Kafka Topic中配置的Broadcast Stream,它是基于Flink的Broadcast State特性,实现代码如下所示:
// create dynamic configuration event stream
final FlinkKafkaConsumer010 kafkaConfigEventSource = new FlinkKafkaConsumer010<>(
parameterTool.getRequired("input-config-topic"),
new SimpleStringSchema(), parameterTool.getProperties());
final BroadcastStream configBroadcastStream = env
.addSource(kafkaConfigEventSource)
.map(new MapFunction() {
@Override
public Config map(String value) throws Exception {
return Config.buildConfig(value);
}
})
.broadcast(configStateDescriptor); 上面代码中,最后一行调用了broadcast()方法,用来指定要广播的状态变量,它在Flink程序运行时会发送到下游每个Task中,供Task读取并使用对应配置信息,下游Task可以根据该状态变量就可以获取到对应的配置值。参数值configStateDescriptor是一个MapStateDescriptor类型的对象,定义并初始化,代码如下所示:
private static final MapStateDescriptor configStateDescriptor =
new MapStateDescriptor<>(
"configBroadcastState",
BasicTypeInfo.STRING_TYPE_INFO,
TypeInformation.of(new TypeHint() {})); 它使用事件中的channel(渠道)字段作为Key,也就是不同渠道对应的配置是不同的,实现了对渠道配置的灵活性。而对应的Value则是我们定义的Config,该类中定了如下几个属性:
private String channel;
private String registerDate;
private int historyPurchaseTimes;
private int maxPurchasePathLength;具体含义可以从属性名称命名得知,广播后下游的每个Task都可以读取到这些配置属性值。
- 连接两个Stream并实现计算处理
我们需要把最终的计算结果保存到一个输出的Kafka Topic中,所以先创建一个FlinkKafkaProducer010,代码如下所示:
final FlinkKafkaProducer010 kafkaProducer = new FlinkKafkaProducer010<>(
parameterTool.getRequired("output-topic"),
new EvaluatedResultSchema(),
parameterTool.getProperties());然后,再调用customerUserEventStream的connect()方法连接到configBroadcastStream,从而获取到configBroadcastStream中对应的配置信息,进而处理实际业务逻辑,代码如下所示:
// connect above 2 streams
DataStream connectedStream = customerUserEventStream
.connect(configBroadcastStream)
.process(new ConnectedBroadcastProcessFuntion());
connectedStream.addSink(kafkaProducer);
env.execute("UserPurchaseBehaviorTracker"); 用户操作行为事件Stream调用connect()方法,参数是Broadcast Stream,就可以生成一个新的BroadcastConnectedStream类型的Stream,再调用process()方法,并增加对该Stream中数据记录处理的逻辑。
对BroadcastConnectedStream进行处理
BroadcastConnectedStream调用process()方法,参数类型为KeyedBroadcastProcessFunction或者BroadcastProcessFunction,我们这里实现类为ConnectedBroadcastProcessFuntion,它继承自KeyedBroadcastProcessFunction抽象类。通过前面Broadcast State API部分,我们已经了解到,需要实现processBroadcastElement()和processElement()这两个处理方法,一个是处理Broadcast Stream,另一个是处理用户操作行为事件Stream。我们首先在ConnectedBroadcastProcessFuntion中定义了一个用来存储用户操作行为事件的状态变量,代码如下:
// (channel, Map)
private final MapStateDescriptor> userMapStateDesc =
new MapStateDescriptor<>(
"userEventContainerState",
BasicTypeInfo.STRING_TYPE_INFO,
new MapTypeInfo<>(String.class, UserEventContainer.class)); 上面代码中,userMapStateDesc是一个Map结构,Key是渠道(channel),Value又是一个包含用户ID(userId)和UserEventContainer的Map结构。UserEventContainer内部封装了一个List,用来保存属于同一个用户的UserEvent列表。
我们先看一下processBroadcastElement()方法实现,代码如下所示:
@Override
public void processBroadcastElement(Config value, Context ctx, Collector out)
throws Exception {
String channel = value.getChannel();
BroadcastState state = ctx.getBroadcastState(configStateDescriptor);
final Config oldConfig = ctx.getBroadcastState(configStateDescriptor).get(channel);
if(state.contains(channel)) {
LOG.info("Configured channel exists: channel=" + channel);
LOG.info("Config detail: oldConfig=" + oldConfig + ", newConfig=" + value);
} else {
LOG.info("Config detail: defaultConfig=" + defaultConfig + ", newConfig=" + value);
}
// update config value for configKey
state.put(channel, value);
} 通过调用ctx.getBroadcastState(configStateDescriptor),根据上面定义的MapStateDescriptor可以获取到对应的BroadcastState,其中包括渠道(channel)和Config对象。上面实现逻辑包含了,如果更新对应配置变更的操作,更新后的配置信息会存储到BroadcastState中,它其实就是一个Map结构,通过Key就可以获取到对应最新的配置Value(这里Key是渠道,Value是Config对象)。
再看一下processElement()方法的实现,它的实现才是业务处理最核心的部分,代码如下所示:
@Override
public void processElement(UserEvent value, ReadOnlyContext ctx,
Collector out) throws Exception {
String userId = value.getUserId();
String channel = value.getChannel();
EventType eventType = EventType.valueOf(value.getEventType());
Config config = ctx.getBroadcastState(configStateDescriptor).get(channel);
LOG.info("Read config: channel=" + channel + ", config=" + config);
if (Objects.isNull(config)) {
config = defaultConfig;
}
final MapState> state =
getRuntimeContext().getMapState(userMapStateDesc);
// collect per-user events to the user map state
Map userEventContainerMap = state.get(channel);
if (Objects.isNull(userEventContainerMap)) {
userEventContainerMap = Maps.newHashMap();
state.put(channel, userEventContainerMap);
}
if (!userEventContainerMap.containsKey(userId)) {
UserEventContainer container = new UserEventContainer();
container.setUserId(userId);
userEventContainerMap.put(userId, container);
}
userEventContainerMap.get(userId).getUserEvents().add(value);
// check whether a user purchase event arrives
// if true, then compute the purchase path length, and prepare to trigger predefined actions
if (eventType == EventType.PURCHASE) {
LOG.info("Receive a purchase event: " + value);
Optional result = compute(config, userEventContainerMap.get(userId));
result.ifPresent(r -> out.collect(result.get()));
// clear evaluated user's events
state.get(channel).remove(userId);
}
} 通过调用ctx.getBroadcastState(configStateDescriptor).get(channel)就获取到了Broadcast Stream中某个渠道最新的配置Config对象,然后就可以在处理事件过程中使用该配置信息。配置信息一旦变更,这里面也会实时地获取到由processBroadcastElement()方法处理并更新的配置值。到达的每个用户的操作行为事件,会首先保存到userMapStateDesc这个MapStateDescriptor类型的状态变量中,不断累积缓存,一旦该用户的一个PURCHASE类型的购物事件到达,则调用compute()方法计算结果数据,最后结果数据EvaluatedResult会被输出到Sink Operator对应的Task中,保存到Kafka Topic中。上面代码中调用了compute()方法,具体实现如下所示:
private Optional compute(Config config, UserEventContainer container) {
Optional result = Optional.empty();
String channel = config.getChannel();
int historyPurchaseTimes = config.getHistoryPurchaseTimes();
int maxPurchasePathLength = config.getMaxPurchasePathLength();
int purchasePathLen = container.getUserEvents().size();
if (historyPurchaseTimes < 10 && purchasePathLen > maxPurchasePathLength) {
// sort by event time
container.getUserEvents().sort(Comparator.comparingLong(UserEvent::getEventTimestamp));
final Map stat = Maps.newHashMap();
container.getUserEvents()
.stream()
.collect(Collectors.groupingBy(UserEvent::getEventType))
.forEach((eventType, events) -> stat.put(eventType, events.size()));
final EvaluatedResult evaluatedResult = new EvaluatedResult();
evaluatedResult.setUserId(container.getUserId());
evaluatedResult.setChannel(channel);
evaluatedResult.setEventTypeCounts(stat);
evaluatedResult.setPurchasePathLength(purchasePathLen);
LOG.info("Evaluated result: " + evaluatedResult.toJSONString());
result = Optional.of(evaluatedResult);
}
return result;
} 上面代码使用配置对象Config来判断是否需要输出该用户对应的计算结果,如果是,则计算购物路径长度,并统计该用户操作行为事件类型的个数。
提交运行Flink Job
我们需要创建对应Topic,创建命令参考如下:
./bin/kafka-topics.sh --zookeeper 172.23.4.138:2181,172.23.4.139:2181,172.23.4.140:2181/kafka --create --topic user_events --replication-factor 1 --partitions 1
./bin/kafka-topics.sh --zookeeper 172.23.4.138:2181,172.23.4.139:2181,172.23.4.140:2181/kafka --create --topic app_config --replication-factor 1 --partitions 1
./bin/kafka-topics.sh --zookeeper 172.23.4.138:2181,172.23.4.139:2181,172.23.4.140:2181/kafka --create --topic action_result --replication-factor 1 --partitions 1
上面程序开发完成后,需要进行编译打包,并提交Flink Job到Flink集群,执行如下命令:
bin/flink run -d -c org.shirdrn.flink.broadcaststate.UserPurchaseBehaviorTracker ~/flink-app-jobs.jar --input-event-topic user_events --input-config-topic app_config --output-topic action_result --bootstrap.servers 172.23.4.138:9092 --zookeeper.connect zk01.td.com:2181,zk02.td.com:2181,zk03.td.com:2181/kafka --group.id customer-purchase-behavior-trackerFlink Job正常运行后,我们向Kafka的app_config这个Topic中模拟发送配置事件记录:
./bin/kafka-console-producer.sh --topic app_config --broker-list 172.23.4.138:9092输入如下配置事件JSON字符串:
{"channel":"APP","registerDate":"2018-01-01","historyPurchaseTimes":0,"maxPurchasePathLength":6}向Kafka的user_events这个Topic中模拟发送用户操作行为事件记录:
./bin/kafka-console-producer.sh --topic app_config --broker-list 172.23.4.138:9092./bin/kafka-console-producer.sh --topic app_config --broker-list 172.23.4.138:9092分别依次输入如下用户的每个操作行为事件JSON字符串:
{"userId":"a9b83681ba4df17a30abcf085ce80a9b","channel":"APP","eventType":"VIEW_PRODUCT","eventTime":"2018-06-12_08:45:24","data":{"productId":126}}
{"userId":"a9b83681ba4df17a30abcf085ce80a9b","channel":"APP","eventType":"VIEW_PRODUCT","eventTime":"2018-06-12_08:57:32","data":{"productId":273}}
{"userId":"a9b83681ba4df17a30abcf085ce80a9b","channel":"APP","eventType":"VIEW_PRODUCT","eventTime":"2018-06-12_09:21:08","data":{"productId":126}}
{"userId":"a9b83681ba4df17a30abcf085ce80a9b","channel":"APP","eventType":"VIEW_PRODUCT","eventTime":"2018-06-12_09:21:49","data":{"productId":103}}
{"userId":"a9b83681ba4df17a30abcf085ce80a9b","channel":"APP","eventType":"VIEW_PRODUCT","eventTime":"2018-06-12_09:21:59","data":{"productId":157}}
{"userId":"a9b83681ba4df17a30abcf085ce80a9b","channel":"APP","eventType":"VIEW_PRODUCT","eventTime":"2018-06-12_09:27:11","data":{"productId":126}}
{"userId":"a9b83681ba4df17a30abcf085ce80a9b","channel":"APP","eventType":"ADD_TO_CART","eventTime":"2018-06-12_09:43:18","data":{"productId":126}}
{"userId":"a9b83681ba4df17a30abcf085ce80a9b","channel":"APP","eventType":"VIEW_PRODUCT","eventTime":"2018-06-12_09:27:11","data":{"productId":126}}
{"userId":"a9b83681ba4df17a30abcf085ce80a9b","channel":"APP","eventType":"PURCHASE","eventTime":"2018-06-12_09:30:28","data":{"productId":126,"price":299.00,"amount":260.00}}
可以看到,输入每个事件,都会在Task中接收到并处理。在输入到最后一个用户购买事件时,触发了计算并输出结果,可以在另一个输出Kafka Topic action_result中看到结果,如下所示:
{"userId":"a9b83681ba4df17a30abcf085ce80a9b","channel":"APP","purchasePathLength":9,"eventTypeCounts":{"ADD_TO_CART":1,"PURCHASE":1,"VIEW_PRODUCT":7}}如果我们将前面的配置内容,再改成如下内容:
{"channel":"APP","registerDate":"2018-01-01","historyPurchaseTimes":0,"maxPurchasePathLength":20}同样输入上述用户操作行为事件记录,由于maxPurchasePathLength=20,所以没有触发对应结果计算和输出,因为用户的purchasePathLength=9,可见配置动态变更生效。
具体代码见 github:
https://github.com/shirdrn/flink-app-jobs/blob/master/src/main/java/org/shirdrn/flink/jobs/streaming/UserPurchaseBehaviorTracker.java