Udacity Self-Driving自动驾驶目标检测数据集使用指南
一、dataset1
下载dataset1,该数据集大小为1.5G,共有9420张图像。label格式如下图所示,共有Car、Truck、Pedestrian三类。(使用数据格式转化工具可直接实现voc格式的转化,参考博客LITTI、VOC、Udacity等自动驾驶数据集下载及格式转化)

实现:
python main.py --from udacity-crowdai --from-path -crowdai --to voc --to-path datasets
生成类别为:car、truck、person
二、dataset2
下载dataset2,该数据集大小为3.3G,共有15000张图像。label格式如下图所示,共有Car、Truck、Pedestrian、trafficLight(Red、RedLeft、Green、Yellow、YellowLeft)、biker这些类别。其中,有标签的图片共有13063张,暂时不用管,在转化voc过程中,可直接实现无标签图像的清除。
原label的格式如下图
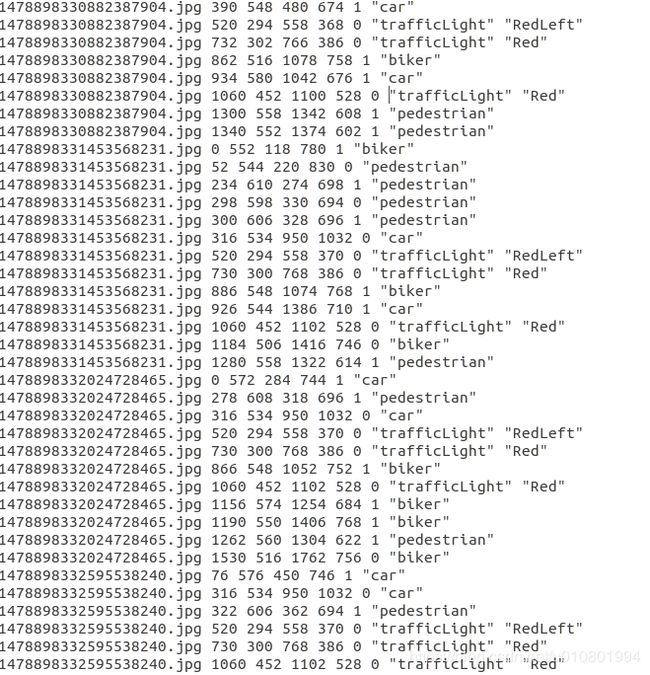
在trafficLight标签类别下,由于想要选取最后一列字符串作为标签label,对该格式文件进行预处理,生成新的格式统一的标签label文件,preprocess.py代码如下:
# preprocess.py
file = open('labels.csv', 'r').readlines()
fileout = open('labels1.csv', 'w')
for line in file:
while line[6] != None:
fileout.write(line.replace('"trafficLight" ', ''))
break
fileout.close()
结果如下:

这里的处理,是为了使用格式转化工具实现udacity到voc的数据转化,实现类别有:car、truck、person、red、green、yellow、trafficLight、biker共8个类别。
修改格式转化工具中的voc.py中的VOCEgestor类函数如下,注:经验得,label的首字母不能是大写的,否则xml文件无法生成该类别label;如果类别label是大写,可通过下面的期望类别修改生成。
class VOCEgestor(Egestor):
def expected_labels(self):
return {
'aeroplane': [],
'bicycle': [],
'bird': [],
'boat': [],
'bottle': [],
'bus': [],
'car': [],
'cat': [],
'chair': [],
'cow': [],
'diningtable': [],
'dog': [],
'horse': [],
'motorbike': [],
'person': ['pedestrian'],
'pottedplant': [],
'sheep': [],
'sofa': [],
'train': [],
'tvmonitor': [],
'red': ['Red', 'RedLeft'],
# 'redLeft': ['RedLeft'],
'green': ['Green', 'GreenLeft'],
# 'greenLeft': ['GreenLeft'],
'yellow': ['Yellow', 'YellowLeft'],
# 'yellowLeft': ['YellowLeft'],
'trafficLight': [],
'biker': ['biker']
}
实现:
python main.py --from udacity-autti --from-path object-dataset --to voc --to-path datasets

生成的文件夹中,JPEGImages和Annotations中含有13063个文件。生成的ImageSets中含有一个txt文件,trainval.txt,为了生成train.txt/val.txt,可参考博客数据整理部分生成所需文件。
参考博客:https://blog.csdn.net/jesse_mx/article/details/72599220