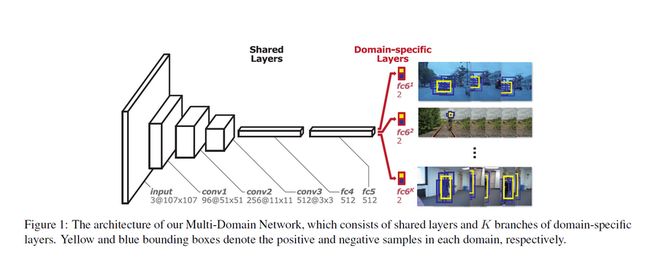
方法:主要逻辑关系+函数调用关系+图形和语言描述=把握好主要思想和脉络
MDnet--master 源代码目录
--dataset (存放数据集的文件夹)
--matconvnet (这个不用说了,是matlab下的CNN框架)
--models (存放已训练模型的文件夹)
--pretraining (实现模型训练功能模块的文件夹)
-seqList (存放otb或者vot数据集的子序列名称列表)
-demo_pretraining (训练网络的demo:
1、调用mdnet_prepare_model,准备CNN网络模型;
2、调用mdnet_pretrain,完成网络的训练和保存)
-mdnet_prepare_model (为MDnet准备初始的卷积网络模型:
1、conv1-3直接采用VGG-M的结构和初始化权重,注意新的网络结构里filters对应原weight{1},
biases对应weight{2};pad由原来的格式[0,0,0,0],变换为0。
2、添加fc4层和相应的relu和dropout层,fc5层和相应的relu和dropout层,fc6层和softmax层,
fc4-6随机初始化,fc6构造为K个分支
注意:fc层的stride为数字1,conv层的stride为数组[1,1],
为了保证fc层的更新,还要设置w和B的倍乘速率和decay)
-mdnet_pretrain (三个参数:seqslist、outFile、roiDir
首先设置各种参数opts,
然后通过调用mdnet_setup_data获得所有图像序列的图像列表以及正负样本bb,保存为roidb,
初始化mdnet,设置fc6的1×1×K×2结构,设置最后一层为softmax_k
训练mdnet,调用的函数为mdnet_train,过程中嵌套调用了生成minibatch的函数getBatch;
最后,调用mdnet_finish_train,将fc6还原为1×1×1×2结构,保存网络到layers
-getBatch(输入为:1、roidb某个子序列所有的图像路径,正样本和负样本bb;
2、img_idx为了组成一个minibatch抽到的8帧图像标号;
3、batch_pos-已设置为32;batch_neg已设置为96;opts代表各个参数结构体
中间变量含义:pos_boxes表示正样本的组合:8帧图像,每帧50个正样本,一共400个正样本
然后从0-400随机抽取32个序号idx,得到长度为32的pos_boxes,
再用pos_idx来标记其所在帧处于8帧里的第几个。
同样的方法得到一个minibatch里的96个负样本,然后正负样本拼接起来;
调用get_batch函数生成minibatch
输出为:128个im和对应的labels,数字2代表正,1为负)
-mdnet_train(输入:net,roidb,getBatch函数
首先,网络参数初始化设定
然后,按照每个序列8帧一个batch,一个序列迭代100次来计算,打乱序列的图像次序后组一个800帧的序列,保存在frame_list里
接着,是训练过程:
外循环是cycle100,内循环是子序列总数K
在内循环里,首先得到每一个batch里乱序8帧的编号,调用getBatch生成图像和label;
然后是backprop,将label送入loss层,调用mdnet_simplenn,实现网络的前向反向计算
注意:mdnet_simplenn中softmax_k是作者自己定义的层,是为fc6的多域设计的
接着是梯度更新
最后是打印训练中的信息
-get_batch(输入:8张图像的列表images,正负样本bb和对应帧1-8编号组成的数组boxes,varargin
输出:128张107×107×3的图像组)
--tracking
-mdnet_run(主代码-实现tracking
1、调用mdnet_init执行初始化
2、bbox回归训练
1.调用gen_samples,生成10000个回归样本
2.调用overlap_ratio计算样本与gt的重叠率
3.选出重叠率大于0.6的样本,随机从中选择1000个作为正样本
4.调用mdnet_features_convX得到正样本经过卷积层处理后的特征图表示
5.将第4步的结果进行维度变换并拉伸为一行,输入到tran_bbox_regressor训练回归模型
3、提取第一帧图像的正负样本经过三层卷积后的特征
4、调用mdnet_finetune_hnm选出hard负样本,并和正样本一起微调net的fc层
5、为在线更新做好数据样本准备
6、从第二帧开始进入主循环
1.在当前帧调用gen-sample选出256个candidate样本,得到卷积后特征;
2.送入fc层,得到fc6二进制输出,正得分最高的五个取平均如果大于0,则为最佳结果,否则,扩大搜索范围
3.bounding box回归调整最后结果
4.做下一帧的数据样本准备,保存正负样本的特征)
-mdnet_finetune_hnm(用hard minibatch来训练CNN:
输入:要微调的net部分(fc层),正样本特征,负样本特征,其他参数
注意hard体现在负样本的选择上,从1024个负样本选出得分最高的96个
输出:微调后的net,以及所有选中的正负样本序号
-mdnet_features_convX(提取输入图像样本bbox的卷积特征:
输入:卷积层、图像、该图像样本box、参数opts
调用mdnet_extract_regions得到样本图像,然后将这些样本图像送入网络vl_simplenn
输出:计算得到其经过卷积层处理后的特征图)
-mdnet_extract_regions(从输入图像提取bounding box regions并调用im_crop去均值并resize到107×107:
输入:图像、该图像样本bbox、参数opts
输出:resize后的各样本图像)
-mdnet_init(初始化tracker:
输入:图像序列image、已训练好的网络net
几乎所有参数的设置都在这里,返回卷积层net_conv,全连接层net_fc,学习和跟踪过程中各
参数的结构体opts)
-gen_samples(根据第一个输入参数决定采样方式,返回采样得到的矩阵box
gaussian,uniform,uniform_aspect,whole四种类型,针对采样的不同需求,如样本正/负)
--utils(一些用来支撑算法实现的函数)
-parseImage(得到图像列表imgList)
-genConfig(得到图像信息conf:
conf.dataset:数据集(是otb/vot)
conf.seqName:序列名称('divng'/'Divid')
conf.imgDir:图像所在目录
conf.imgList:图像列表(../../0001.jpg)
conf.gt:ground truth列表(double类型数组))
-overlap_ratio(计算图像块的重叠率overlap)
-im_crop(-----这是RCNN里的函数------
对输入图像按照图像样本box crop,减去均值(默认128),然后按照比例resize到统一大小107
因边界条件不足比例的补0
输入中有参数padding目前只看到其会影响bbox的尺度,即按照padding扩大区域后再处理)
-train_bbox_regressor(-----这是rcnn里的函数----
输入:每一个3×3的特征图都拉伸为一行,512个拼接成一行X;采样的bbox;groundtruth
输出:一个结构体包含训练好的model和参数-*
SANet基于MDNet,代码有很大的相似性。
utils完全一样、tracking完全一样、pretraining完全一样
datasets数据集格式有些不同
models不同
多了一个rnn模块。
也就是基本逻辑清楚后,需要在数据集的处理和变化的模块上下功夫。代码哪块儿多,哪块儿少?