C-COT
C-COT算法:连续空间域的卷积操作
- 发表于: 2017-04-20
- 分类: 深度学习, 目标跟踪, 首页展示
- 标签: c-cot, ccot, eco, tracking
C-COT算法是DCF(KCF)算法的又一重要演进算法,该算法在VOT-16上取得了不错的成绩。C-COT使用深度神经网络VGG-net提取特征,通过立方插值,将不同分辨率的特征图插值到连续空间域,再应用Hessian矩阵可以求得亚像素精度的目标位置(就和SURF、SIFT里面获取亚像素精度特征点的思想类似)。确定插值方程之后,还解决了在连续空间域进行训练的问题。C-COT的代码结合了deepSRDCF、SRDCFdeno的样本进化,和C-COT进行插值等算法。这里面博主也有许多地方没有理解,毕竟Martin的数学功底大家都明白,这里就当时写一下自己的理解了。文章代码
除了Paper之外,这篇博客主要基于一下几份文档:
Martin的PPT:C-COT_VOT16_slides.pdf
知乎专栏:Beyond Correlation Filters:Learning Continuous Convolution Operators for Visual Tracking
博主就着Martin的PPT说好了,省的敲公式。
- 介绍
- 纵览
- 插值操作
- 连续空间域训练
- 亚像素精度的位置
- 对比SRDCF
- 实验结果
- 后作:ECO
介绍
DCF算法因为极致的速度和优异的表现,在目标识别、目标检测和目标跟踪方面得到了广泛的应用。KCF算法、SRDCF算法、DSST算法、HCF算法、Staple算法等许多算法中都使用了DCF。Martin今年来一直在DCF算法方面进行挖掘,SRDCF算法通过空间正则化减小循环平移的边缘效应,deepSRDCF采用深度神经网络提取特征,SRDCFdeno算法将样本权重优化融合进了Loss方程,DSST着重解决目标尺度变化的问题,C-COT将学习检测过程推广到连续空间域(使用插值方法),可以获得亚像素精度的位置。ECO算法(下一作)在C-COT的基础上将速度提升到了60fps,并且将样本分组解决过拟合问题,效果更好了。这篇Paper: Beyond Correlation Filters:Learning Continuous Convolution Operators for Visual Tracking,就是C-COT算法。
纵览
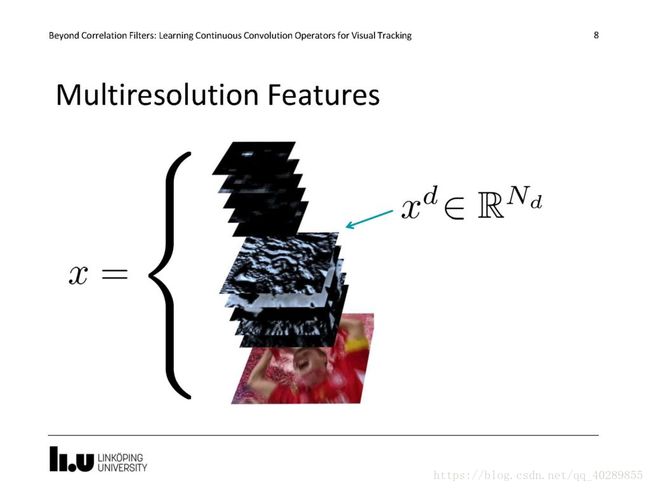
下面这张图是C-COT的Paper里唯一一张解释原理的图。在最左边的是我们选取的特征,C-COT使用VGG-Net(一个预训练好的深度神经网络)来提取特征,下图就是最终作者公布的代码中C-COT使用的特征,作者使用了原始的彩色图像(如果原图是灰度,就复制三个通道成为彩色)和两个卷积层的输出通道作为特征。其中分别使用了五个分辨率(代码中是0.96,0.98,1.00,1.02,1.04五种缩放倍率)的图像进行特征提取,最终得到了下图中的数个通道的特征图。
第二列,就是训练得到的连续卷积操作滤波器,每个通道对应一个滤波器,原始图像是彩色,有三个通道,对应了三个滤波器,使用这些滤波器对得到的特征图进行卷积操作就得到了第三列的响应图。将第三列的响应图进行加权平均,就得到了第四列的结果,响应图极大值位置就是预测的目标位置。

为什么要这么做(使用多分辨率特征)呢?因为单个分辨率的输出结果存在扰动,可能是由于目标尺度变化引起的,如下图。所以要融合多个分辨率的特征图。

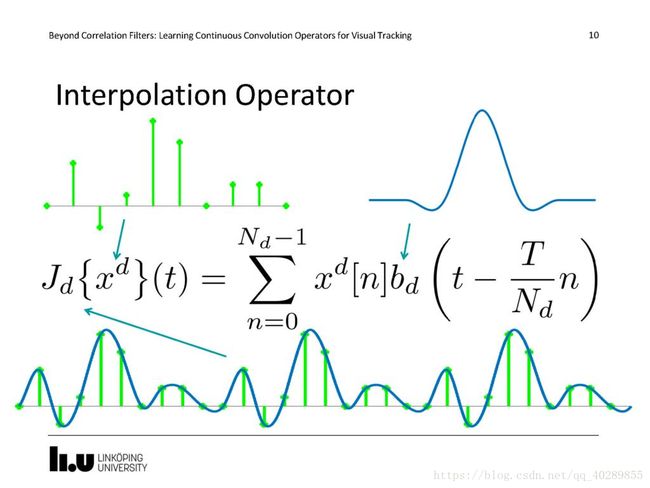
插值操作
我们现在拥有五个(Paper中的数值)分辨率的图像和特征图,如果我们想获取连续空间域的特征图应该怎么做呢?首先想到的就是插值操作了,一个细节就是在代码中使用的是三次立方插值来获取的连续空间分辨率的特征图,为此我们还特别定义了一个插值运算符J。

连续空间域训练
博主数学功底不行,前面的分析将细致一点,后面的训练优化求解博主就说下自己的理解吧(SRDCF的时候还能考代码来理解,现在代码都看不太懂了 0.0)。
训练的Loss还是和原来定义的一样,由于C-COT使用的是SRDCF的框架,所以后边有一个空间正则化项。

现在,将LossFunction变换到频域(因为DCF就是在频域进行快速操作的),后面的X[k]是表示傅里叶级数。根据我们要最小化的LossFunction,构造出原始线性回归方程,该LossFunction的最优化问题就等价成了一个线性方程的求解问题。
下面的式子可以使用共轭梯度法进行优化。

亚像素精度的位置
文中说应用Hessian矩阵可以求得亚像素精度的目标位置(个人理解就和SURF、SIFT里面获取亚像素精度特征点的思想类似),本质也是一个插值过程。
那么再回过头来说连续卷积操作的意义。深度神经网络不通层次输出的特征意义是不一样的,底层的特征更有利于确定精确的位置,越深层特征越包含语义信息。同时,通过多分辨率的特征图,结合多分辨率的滤波模板进行训练和检测,可以获得更加精确的位置和更好的鲁棒性。应用三次线性内插值进行目标位置亚像素精度的定位。

下面这张图展示了位置细化的过程是一个迭代的过程,代码中有一个迭代次数设置,在代码中设置为1,也就是使用最初的位置(换句话说,在当前长时间跟踪算法本身误差之下,更精细的位置意义不到)。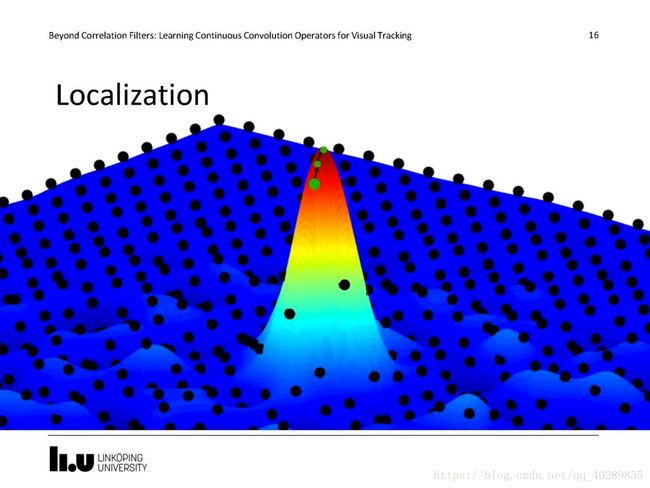
对比SRDCF

实验结果
实验了使用不同特征图时候的效果,最后使用了原始图像和第一层、第五层的输出结果。

在VOT-2016上取得不错的成绩(事实上前几名都差不多,速度很慢很慢) 博主在自己的i5 6600k(4.5GHz)上测试速度1.05fps。作者说这个算法如果使用Hog特征是可以达到实时的,不过效果和SRDCF一样,这个改进就显得鸡肋了。 

后作:ECO
这篇博客原本是为之前一篇介绍ECO算法的博客写的,C-COT效果好而速度慢,C-COT的下一个演进版本是ECO(CVPR17),ECO以C-COT为基础,达到了60fps的速度。有办法解决速度问题,C-COT连续空间域卷积操作的发展空间更加广阔了。