二分图带权匹配(推箱子问题的思考)
转载请附上原文链接: http://blog.csdn.net/u013351484/article/details/51598270
二分图带权匹配(也叫二分图最优(最佳)匹配,Kuhn-Munkres 算法)
预备知识:二分图最大匹配,二分图完备(完美)匹配
二分图带权匹配,可以把它看作集合 X 的每个顶点到集合 Y 的每个顶点均有边的二分图(设权重均为正数,则原来分别在集合 X 与集合 Y 中没边的顶点 xi,yi 就可以添加一条权重为 0 的边,即 w[xi,yi] = 0);这样的二分图必定存在完备匹配。
接下来求解二分图最大权值匹配过程的所有内容都将以下面这个例子展开:
设有二分图 G:
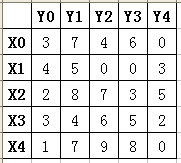
最好把这个表画在纸上 :)
首先要有顶标的概念:
二分图最大权值匹配通过给集合 X 和集合 Y 的每个顶点定义一个值,称为顶标;可以设集合 X 里的顶点 xi 的顶标为 lx[i],集合 Y 同理。算法执行过程中确保 lx[i] + ly[j] >= w[xi, yj] 成立(只有这式子成立,才能证明 km 算法的正确性)。
图 G 在算法刚开始执行时要满足 lx[i] + ly[j] >= w[xi, yj] 的要求可以这样设定:lx[i] 等于 xi 与集合 Y 中所有顶点连线的最大值;即 lx[i] = max{w[xi, yj]},j = {0, ... , 4},ly[i] 全为 0;因此,一开始的图可以是这样:
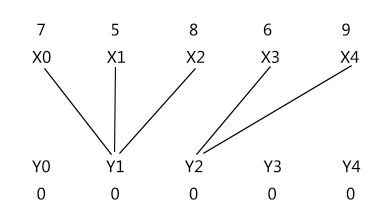
接着要有相等子图的概念:
二分图中满足 lx[i] + ly[j] = w[xi,yj] 的边称为等边,而由等边构成的子图称为相等子图。如上图就是一个相等子图;上图去掉任意边(至少保留一条)仍为相等子图;但上图增加任意边就不是相等子图了,因为增加任意边都会使得新增加的边的 lx[i] + ly[j] > w[xi, yj]。
接着就会有:
如果二分图的相等子图存在完备匹配,那这个完备匹配就是二分图的最大权值匹配。因为对于二分图的任意一个匹配,如果它包含于相等子图,那么它的边权和等于所有顶点的顶标和;如果它有的边不包含于相等子图,那么它的边权和小于所有顶点的顶标和。所以相等子图的完备匹配一定是二分图的最大权匹配。看不懂没关系,把整个过程搞一遍再回来看看也许就理解了。
因此,二分图最大权值匹配的过程其实就是通过修改集合 X 与集合 Y 的顶标使得二分图里 lx[i] + ly[j] = w[xi, yi] 的边不断增多,也即相等子图不断扩大,直到相等子图出现完备匹配为止;而此完备匹配就是所求。
km 算法流程基本基于下图:
再接着就会有:怎样修改顶标?什么情况下要修改顶标?带着这个疑问往下走~
有了以上的概念(虽然可能还是模模糊糊),我们尝试找出二分图 G 的最大权值匹配。
为了理解方便,求解过程都是基于 DFS 的顺序。
那~,开始了:
1)
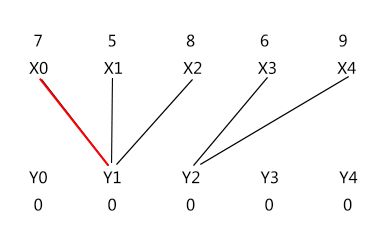
为 X0 找交错路,X0 -> Y1;这一步是没有问题的。
2)
为 X1 找交错路,X1 -> Y1 -> X0;终点不在集合 Y,说明目前的相等子图不能为 X0,X1(目前遍历到它们)都找到各自的匹配;接着自然想到需要往当前相等子图里面添加新的等边使匹配成为可能。
哪些边可以进入相等子图呢?必须满足这两个条件:
1、任何时候必须确保二分图里所有顶点满足 lx[i] + ly[j] >= w[xi, yj]。
2、新加入的边必须是等边,因为只有等边才属于相等子图的边集。
其实在不修改顶标的情况下,条件 1 是肯定满足的;如果不考虑其他,直接把边加进去,像这样:

我们加入了边 [x1, y2],确实能使得 X0,X1 找到各自的匹配(X0 -> Y1;X1 -> Y2)但此边 lx[1] + ly[2] = 5 > w[x1,y2] = 0;因此它并不包含于相等子图中,这将导致求解错误(km 算法原理就是在相等子图里找到完备匹配,若匹配里含有非相等子图里的边,自然错误)。因此,我们必须通过修改 lx[] 或 ly[] 的顶标使得合适的边加入到相等子图,使匹配成为可能,同时又能满足上面两个条件。
来一些新的概念:
当集合 X 里的某个点 xi 在相等子图里匹配失败的时候,从 xi 出发的所有交错路可以组成一颗交错树(匈牙利树);我们把交错树里属于 X 集合的所有元素定义为集合 S;属于 Y 集合的所有元素定义为集合 T。因此,把集合 X 里不属于集合 S 的所有元素定义为集合 notS;把集合 Y 里不属于集合 T 的所有元素定义为集合 notT。
回到 X1 匹配失败的时候,有交错路 X1 -> Y1 ->X0;所以 S = {X0, X1},T = {Y1}。我们修改顶标的方法是通过把 S 里的所有顶点的顶标减去一个值 d,且 d 为正数(先别管它怎样来),把 T 里的所有顶点的顶标加上 d。这样做会使得原来相等子图发生什么变化?
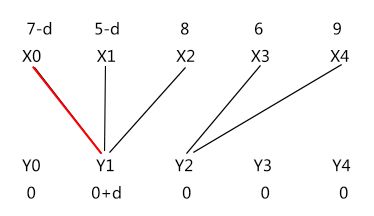
1、对于在交错树(即 xi 属于 S,yi 属于 T)的边,各自的顶标 (lx[i] - d) + (ly[j] + d) = lx[i] + ly[j] 没有变;也就是这些边原来在相等子图里,修改了顶标后仍在相等子图里。如图中的边 X0 - Y1 和边 X1 - Y1。
2、对于 xi 属于 notS,yi 属于 notT 的边,它们各自的顶标并没有改变,lx[i] + ly[j] 没有变;也就是这些边原来不在相等子图里,修改了顶标后仍然不在相等子图里,即这些边不会被加入相等子图。
3、对于 xi 属于 notS,yi 属于 T 的边,各自的顶标 lx[i] + (ly[j] + d) 变大,这说明如果这些边原来在相等子图里的话,修改了顶标后,这些边会退出相等子图,比如图中的边 Y1 - X2(因为事实是这样,我是这样理解的~)。如果这些边原来就不在相等子图里的话,修改了顶标后,就更不可能被加入相等子图。
4、对于 xi 属于 S,yi 属于 notT 的边,这就不一样了,这会有 (lx[i] - d) + ly[j],而修改顶标前为 lx[i] + ly[j] > w[xi,yj];也即是修改顶标后这些边各自的顶标会减小!我们令新顶标 lx[i] = lx[i] - d,ly[j] = ly[j];这意味着这些边各自新的顶标可能会使得 lx[i] + ly[j] = w[xi,yj] 成立,这表示使等式成立的边可以加入到相等子图里!使匹配成功成为可能。
接下来,d 怎样来?km 算法里是这样算的:
d = min{lx[i] + ly[j] - w[xi,yj]},其中 xi 属于 S,yj 属于 notT
so why ? 为什么要这样算?先跳过,算一遍再说:
d = lx[0] + ly[0] - w[x0,y0] = 4 d = lx[1] + ly[0] - w[x1,y0] = 1
d = lx[0] + ly[2] - w[x0,y2] = 3 d = lx[1] + ly[2] - w[x1,y2] = 5
d = lx[0] + ly[3] - w[x0,y3] = 1 d = lx[1] + ly[3] - w[x1,y3] = 5
d = lx[0] + ly[4] - w[x0,y4] = 7 d = lx[1] + ly[4] - w[x1,y4] = 2
嗯,最小的是 d = 1;修改顶标后的相等子图为:
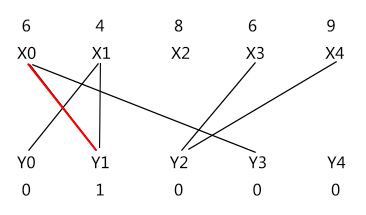
可以发现多了两条边(X0 - Y3 和 X1 - Y0),同时少了一条边(X2 - Y1)。
多的两条边恰好是上面 8 条式子中满足 d = 1 的两条式子的边;其实也不是那么巧,是必然!因为在修改顶标的过程中,对于边 (X0 - Y3),(lx[0] - d) + ly[3] 把 d = lx[0] + ly[3] - w[x0,y3] 代入可得 (lx[0] - d) + ly[3] = w[x0,y3],也即是新顶标满足 lx[0] + ly[3] = w[x0,y3],因此它是等边,自然也是相等子图的边;边 (X1 - Y0) 类似。
而少的那条边是因为修改顶标后 lx[2] + ly[1] = 9 > w[x2,y1] = 8,它不是等边,因此不是属于相等子图里的边,把它从相等子图里除掉。
d = min{lx[i] + ly[j] - w[xi,yj]},其中 xi 属于 S,yj 属于 notT。
再看一下这个式子,对于上面 8 条式子,如果 d 不取 1,而使 d > 1,比如 d = 2
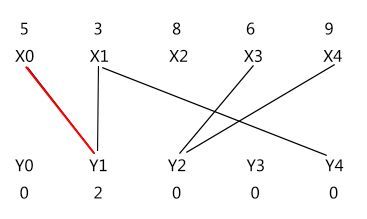
这会使 (X1 - Y4) 进入相等子图,(X2 - Y1) 退出相等子图。看起来可以有 X1 -> Y4 成立,但实际上这不满足:任何时候必须确保二分图里所有顶点满足 lx[i] + ly[j] >= w[xi, yj] 这个条件,比如 lx[0] + ly[3] = 5 < w[x0,y3] = 6,这将导致 km 算法错误。
而如果 d < 1,比如 d = 0.5,那将不会有新的边加入相等子图,因为对于唯一可能加入相等子图的边;即xi 属于 S,yi 属于 notT 的边都将有 (lx[i] - d) + ly[j] > w[xi,yj](因为 d = 1 时才使等式成立),因此不可能有等边产生。
所以有 d = min{lx[i] + ly[j] - w[xi,yj]},其中 xi 属于 S,yj 属于 notT。
3)
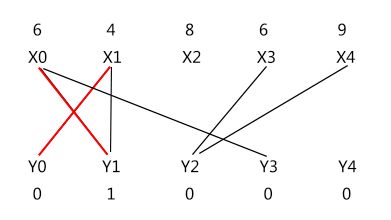
成功为 X1 找到匹配后(X1 -> Y0),接着为 X2 找交错路,也失败了,它的交错树只有 X2 顶点本身;S = {X2},T = {}。
d = lx[2] + ly[0] - w[x2,y0] = 6
d = lx[2] + ly[1] - w[x2,y1] = 1
d = lx[2] + ly[2] - w[x2,y2] = 1
d = lx[2] + ly[3] - w[x2,y3] = 5
d = lx[2] + ly[4] - w[x2,y4] = 3
可见 d = 1
下图(左)可以看到,有 (X2 - Y1 和 X2 - Y2) 两条边加入相等子图,没有边退出相等子图;需要改变的顶标只有 lx[2]。
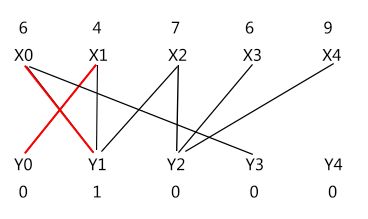
因而有交错路 X2 -> Y1 -> X0 -> Y3,对路径属性取反即可得到上图(右)的匹配。
4)
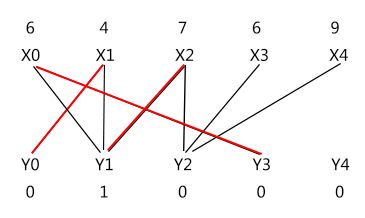
接着为 X3 找交错路,还好,一次成功 :)
5)
最后为 X4 找交错路,交错树为 X4 -> Y2 -> X3;S = {X4, X3},T = {Y2}。
d = lx[4] + ly[0] - w[x4,y0] = 8 d = lx[3] + ly[0] - w[x3,y0] = 3
d = lx[4] + ly[1] - w[x4,y1] = 3 d = lx[3] + ly[1] - w[x3,y1] = 3
d = lx[4] + ly[3] - w[x4,y3] = 1 d = lx[3] + ly[3] - w[x3,y3] = 1
d = lx[4] + ly[4] - w[x4,y4] = 9 d = lx[3] + ly[4] - w[x3,y4] = 4
d = 1
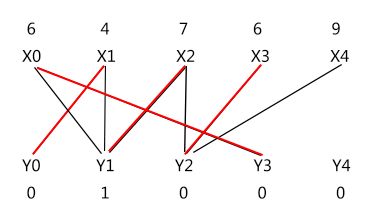
下图可以看到,有 (X4 - Y3 和 X3 - Y3) 两条边加入相等子图,边 (X2 - Y2) 退出相等子图。
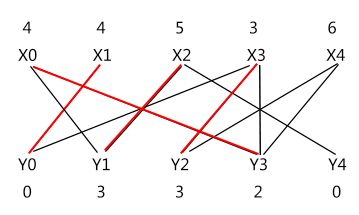
因而有交错路 X4 -> Y3 -> X0 ->Y1 -> X2,gg~,终点不属于集合 Y;不慌 :),还有另一条 X4 -> Y2 -> X3 -> Y3 -> X0 -> Y1 -> X2;完蛋,两条路都没有。只能按步骤再做一遍;注意这颗以 X4 为起点的交错树有两个分支,要把两条路的都算进来,即 S = {X0, X2, X3, X4},T = {Y1, Y2, Y3};
d = lx[0] + ly[0] - w[x0,y0] = 3 d = lx[3] + ly[0] - w[x3,y0] = 2
d = lx[0] + ly[4] - w[x0,y4] = 6 d = lx[3] + ly[4] - w[x3,y4] = 3
d = lx[2] + ly[0] - w[x2,y0] = 5 d = lx[4] + ly[0] - w[x4,y0] = 7
d = lx[2] + ly[4] - w[x2,y4] = 2 d = lx[4] + ly[4] - w[x4,y4] = 8
d = 2
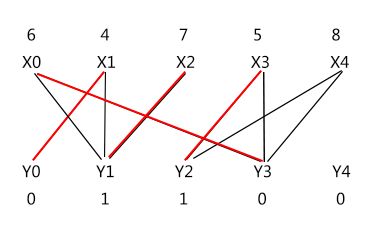
下图可以看到,有 (X2 - Y4 和 X3 - Y0) 两条边加入相等子图,边 (X1, Y1) 退出相等子图。
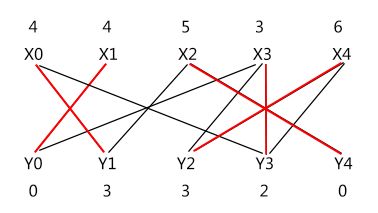
在上面(左)图中再来为 X4 找交错路 X4 -> Y2 -> X3 -> Y0 -> X1,没找到?心惊~;还有一条 X4 -> Y2 -> X3 -> Y3 -> X0 -> Y1 -> X2 -> Y4,看到了可爱的终点!路径属性取反就变成了上面(右)图。至此,集合 X 里的所有顶点都已经有对应的匹配,也就是完备匹配!也即此二分图的最大权值匹配!
X0 -> Y1
X1 -> Y0
X2 -> Y4
X3 -> Y3
X4 -> Y2
最大权值为 30
那要求最小权值匹配怎么办?很简单,在求解前把所有权值取相反数,求得的结果后再对结果取相反数就可以了。
接着谈一下复杂度,比较权威的说法是这样(如果理解了以上讲的内容,复杂度就好理解):
普通做法时间复杂度为 O(n^4) —— 需要找 O(n) 次增广路,每次增广最多需要修改 O(n) 次顶标,每次修改顶标时由于要枚举边来求 d 值,复杂度为 O(n^2)。实际上 Kuhn-Munkers 算法的复杂度是可以做到 O(n^3) 的。我们给每个 Y 顶点一个“松弛量”函数 slack ,每次开始找增广路时初始化为无穷大。在寻找增广路的过程中,检查边 (xi,yj) 时,如果它不在相等子图中,则让 slack[j] 变成原值与 lx[i] + ly[j] - w[xi,yj] 的较小值。这样,在修改顶标时,取所有不在交错树中的 Y 顶点的 slack 值中的最小值作为 d 值即可。但还要注意一点:修改顶标后,要把所有的 slack 值都减去 d。
最后附上一个 C 代码解决这个问题,这是复杂度为 O(n^3) 的 km 算法
同样,如果理解了以上讲的内容,代码也能轻松理解。
#include
#include
#include
#include
#define N 110
const int inf = (1<<30);
int m[N][N];
int lx[N];
int ly[N];
int vx[N];
int vy[N];
int slack[N];
int link[N];
int m_count = 5;
int h_count = 5;
int row, col;
void cal_dis()
{
int i, j;
m[0][0] = 3;
m[0][1] = 7;
m[0][2] = 4;
m[0][3] = 6;
m[0][4] = 0;
m[1][0] = 4;
m[1][1] = 5;
m[1][2] = 0;
m[1][3] = 0;
m[1][4] = 3;
m[2][0] = 2;
m[2][1] = 8;
m[2][2] = 7;
m[2][3] = 3;
m[2][4] = 5;
m[3][0] = 3;
m[3][1] = 4;
m[3][2] = 6;
m[3][3] = 5;
m[3][4] = 2;
m[4][0] = 1;
m[4][1] = 7;
m[4][2] = 9;
m[4][3] = 8;
m[4][4] = 0;
/* 初始化顶标 */
for(i = 0; i < N; i++)
lx[i] = -inf;
for(i = 0; i < m_count; i++){
for(j = 0; j < h_count; j++){
if(m[i][j] > lx[i]){
lx[i] = m[i][j];
}
}
}
memset(ly, 0, sizeof(ly));
}
int dfs(int u)
{
int v;
vx[u] = 1;
for(v = 0; v < h_count; v++){
if(!vy[v]){
int t = lx[u] + ly[v] - m[u][v];
if(!t){
vy[v] = 1;
if(link[v] == -1 || dfs(link[v])){
link[v] = u;
return 1;
}
}
else
if(t < slack[v])
slack[v] = t;
}
}
return 0;
}
int km()
{
int i, j;
int ans = 0;
memset(link, -1, sizeof(link));
for(i = 0; i < m_count; i++){
while(1){
int d = inf;
for(j = 0; j < h_count; j++){
slack[j] = inf;
}
memset(vx, 0, sizeof(vx));
memset(vy, 0, sizeof(vy));
if(dfs(i))
break;
for(j = 0; j < h_count; j++){
if(!vy[j] && slack[j] < d)
d = slack[j];
}
for(j = 0; j < h_count; j++){
if(vx[j])
lx[j] -= d;
}
for(j = 0; j < h_count; j++){
if(vy[j])
ly[j] += d;
}
}
}
for(i = 0; i < h_count; i++)
ans += m[link[i]][i];
return ans;
}
int main()
{
int i;
int ans;
cal_dis();
ans = km();
printf("ans: %d\n", ans);
for(i = 0; i < 5; i++){
if(link[i] != -1){
printf("x%d -> y%d\n", link[i], i);
}
}
return 0;
}
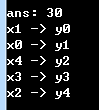
因为程序使用 DFS 求解,可见程序得到的结果跟我们的推算是一致的。
心得:
km 算法我在去年也理解过了一遍,但当时忙于刷 OJ,那时的急切心态使自己没有好好做总结。时隔一年,最近要为推箱子求解程序的 IDA* 算法设计一个比较准确的估值函数,很明显二分图最小权值匹配就能活脱脱的运用上去。然而 km 算法几乎全忘~;咬牙在网上翻了 2 天资料,成功运用在程序中后,取得了比较满意的效果;虽然对 km 算法还有一些不理解的地方,而且可能有理解不对的地方,以后有时间再补全。迅速把自己理解的过程记录下来。其实很早就有这样的意识,但很多时候都没有这样去做:对自己刚掌握的知识,如果认为这些知识对自己很有用,同时又不容易理解;那最好把自己理解它们的过程记录下来,方便以后需要的时候查阅,不然,就算一次弄明白了,往后需要就得重新在网上一阵恶啃(说真的,网上复制粘贴党还是很多的,搜索到自己需要的东西不容易)~,那样反而更耗时间,为何不稍微花点心血趁热打铁呢?
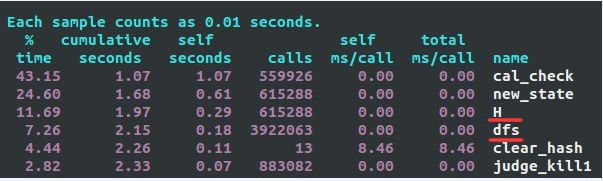
尽管 n 为箱子数,但 O(n^3) 的复杂度还是使得求解的很多时间用在二分图匹配上面~,原因是用到 km 算法的 H() 函数和 dfs() 函数调用太频繁,加起来都 4,000,000+ 次,这只是一个很小的关卡~;如果 n^3 那个 3 能减少会非常地不错。同时发现了 Linux 下为 gcc/g++ 编译器提供性能评测的 gprof 命令 及其类似命令,说真的,非常地有用。
源码地址: github.com/QYPan/sokoban4