Linux安装hadoop配置完全分布式
搭建hadoop完全分布式
工具:
CentOS6.5
jdk8
hadoop2.7.6
安装包都是.tar.gz后缀
三台虚拟机
192.168.136.133 Master
192.168.136.134 Slave1
192.168.136.135 Slave2
在每个虚拟机上添加ip映射的主机名
$ sudo vim /etc/hosts
127.0.0.1 localhost
192.168.136.133 Master
192.168.136.134 Slave1
192.168.136.135 Slave2
关闭防火墙,和selinux
$ sudo chkconfig iptables off
$ sudo chkconfig ip6tables off
关闭selinux,将/etc/sysconfig/selinux文件中的selinux=enforcing注释掉,添加一句selinux=disable
$ sudo vim /etc/sysconfig/selinux
#selinux=enforcing
selinux=disable
修改完后,重启虚拟机,使防火墙关闭生效。
一、安装jdk
hadoop使用java编写的,所以运行hadoop需要jvm。
我登录linux的用户名是hadoop
$ 表示 普通用户下命令界面
在家目录下创建software文件夹
$ cd /home/hadoop
$ mkdir software
把压缩包全部放在此文件夹下。
进入software文件夹,解压jdk到software文件夹中
$ cd software
$ tar -zxvf jdk-8u171-linux-x64.tar.gz -C /home/hadoop/software
给jdk文件夹重命名,并修改所有者权限
$ mv jdk1.8.0 jdk
$ chown -R hadoop:hadoop jdk
给jdk文件夹建一个软连接,以后更改jdk时,不用再修改配置文件,只需要将软连接重新指
jdk的文件夹
$ ln -s jdk jdk.soft
修改配置文件(需要管理员权限,可以用sudo,也可以切换root用户,记得改完后切换回普通用户)
在文件最上方或最下方加入以下内容
$ sudo vim /etc/profile
添加的内容:
#------------------------
# properties jdk
#------------------------
export JAVA_HOME=/home/hadoop/software/jdk.soft
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar:${JRE_HOME}/lib
export PATH=${PATH}:${JAVA_HOME}/bin:${JRE_HOME}/bin
使文件生效,输入java -version或javac -version查看jdk是否配置成功。
$ source /etc/profile
$ java -version
$javac -version
到此,jdk就安装完成了。
二、ssh免密码登录
在Master主机上,生成秘钥
$ ssh-keygen -t rsa
这一步需要输入大概4个回车键,出现图案说明秘钥已经生成了。
进入/home/hadoop目录下,发现有.ssh目录,进入该目录(.ssh是隐藏文件,需要用ls -a才可以看见)
$ cd /home/hadoop
$ ls -a
$ cd .ssh
给本机配置免密码登录,将id_rsa.pub公钥内的文件,追加到authorized_keys中
$ cat id_rsa.pub >> authorized_keys
注意:
.ssh 文件夹权限必须为 700
authorized_keys 文件权限必须为 600
如果不是需要用chmod修改文件权限
在Slave1,Slave2虚拟机上的家目录下创建.ssh文件夹,和.ssh文件内创建authorized_keys文件
(并修改他们的权限)
$ cd /home/hadoop
$ mkdir .ssh
$ chmod 700 .ssh
$ cd .ssh
$ touch authorized_keys
$ chmod 600 authorized_keys
回到Master虚拟机,把id_rsa.pub传给子虚拟机Slave1,Slave2
$ cd /home/hadoop/.ssh
$ scp id_rsa.pub hadoop@Slave1:/home/hadoop/.ssh
$ scp id_rsa.pub hadoop@Slave2:/home/hadoop/.ssh
使用Slave1虚拟机,把Master公钥添加到自己的信任区
$ cd /home/hadoop/.ssh
$ cat id_rsa.pub >> authrized_keys
Slvae2同理。
到此ssh无密码登陆也配置完成了。
三、配置hadoop
会到Master虚拟机,进入software文件夹,解压hadoop
$ cd /home/hadoop/software
$ tar -zxvf hadoop-2.7.6.tar.gz -C /home/hadoop/software
$ mv hadoop-2.7.6 hadoop #修改文件名
$ chmod -R hadoop:hadoop hadoop #修改文件所有者
$ ln -s hadoop hadoop.soft #给hadoop添加软连接
给hadoop添加环境变量。在/etc/profile文件中的最上方或者最下方添加
$ sudo vim /etc/profile
添加内容:
#---------------------------
# property hadoop
#------------------------
export HADOOP_HOME=/home/hadoop/software/hadoop.soft
export PATH=${PATH}:${HADOOP_HOME}/sbin:${HADOOP_HOME}/bin
使配置文件生效,输入hadoop version查看hadoop版本。
$ hadoop version
现在开始修改hadoop的配置文件。
配置文件所在位置在hadoop安装目录下的etc/hadoop中。
需要修改的文件
slaves
hadoop-env.sh
yarn-en.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
1.修改slaves
$ cd /home/hadoop/software/hadoop/etc/hadoop
$ vim slaves
Slave1
Slave2
将里面的localhost删除,添加着两个。
2.修改hadoop-env.sh
找到JAVA_HOME=$JAVA_HOME这一行,把它注释掉,另外增加一行添加内容。
$ vim hadoop-env.sh
#JAVA_HOME=$JAVA_HOME
JAVA_HOME=/home/hadoop/software/jdk.soft
3.修改yarn-env.sh,也是找到JAVA_HOME=$JAVA_HOME这一行,把它注释掉,另外增加一行,添加内容。
$ vim yarn-env.sh
#JAVA_HOME=JAVA_HOME
JAVA_HOME=/home/hadoop/software/jdk.soft
4.修改core-site.xml,在
$ vim core-site.xml
5.修改hdfs-site.xml,同样在
6.修改mapred-site.xml文件,配置文件中没有这个文件,首先需要将mapred-site.xml.tmporary文件改名为
mapred-site.xml
$ mv mapred-site.xml.temporary mapred-site.xml
$ vim mapred-site.xml
7.修改yarn-site.xml
$ vim yarn-site.xml
到这里,Master上的hadoop配置完了。这个时候需要将hadoop这个文件夹,拷贝到Slave1,Slave2
上的/home/hadoop/software文件夹上。
$ cd /home/hadoop/software
$ scp -r hadoop hadoop@Slave1:/home/hadoop/software
$ scp -r hadoop hadoop@Slave2:/home/hadoop/software
如果没有software文件夹,需要在Slave1,Slave2虚拟机上创建该文件夹。
把jdk文件夹同样也拷贝到Slave1,Slave2上。
$ cd /home/hadoop/software
$ scp -r jdk hadoop@Slave1:/home/hadoop/software
$ scp -r jdk hadoop@Slave2:/home/hadoop/software
然后,在Slave1,Slave2上进行配置,和建立软连接,我拿Slave1举例,Slave2同理。
使用Slave1,进入software文件夹下,给hadoop,jdk文件夹建立软连接
$ cd /home/hadoop/software
$ ln -s hadoop hadoop.soft
$ ln -s jdk jdk.soft
修改系统配置文件,在文件最上方添加内容
$ sudo vim /etc/profile
添加内容
#------------------------
# properties jdk
#------------------------
export JAVA_HOME=/home/hadoop/software/jdk.soft
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar:${JRE_HOME}/lib
export PATH=${PATH}:${JAVA_HOME}/bin:${JRE_HOME}/bin
#---------------------------
# property hadoop
#------------------------
export HADOOP_HOME=/home/hadoop/software/hadoop.soft
export PATH=${PATH}:${HADOOP_HOME}/sbin:${HADOOP_HOME}/bin
使用命令使文件生效
$ source /etc/profile
$ javac -version #验证jdk
$ hadoop version #验证hadoop
最后,在Master虚拟机上执行namenode格式化
$ hdfs namenode -format
这一步,在配置完所有文件后,开启hdfs,star-dfs.sh之前。
只使用一次,之后每次开启hadoop都不需要,格式化名称节点。
如果没有格式化名称节点,就启动hadoop,start-dfs.sh,后面会出问题。
解决方法:
关闭hdfs,把tmp,logs文件删除,重新格式化namenode
$ stop-all.sh
$ cd /home/hadoop/software/hadoop
$ rm -rf tmp
$ rm -rf logs
$ hdfs namenode -format #重新格式化namenode
四、开启hadoop
在Master虚拟机上开启hadoop
$ start-all.sh
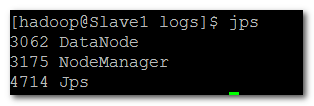
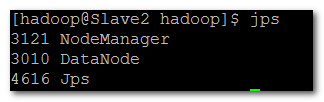
使用jps查看进程
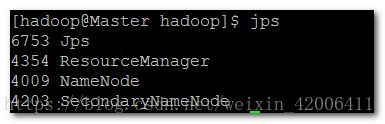
Master含有的进程:
NameNode
SecondaryNameNode
ResourceManager
Slave1,Slave2含有进程:
DataNode
NodeManager
在虚拟机内的浏览器或者windows的浏览器输入网址http://192.168.136.133:50070
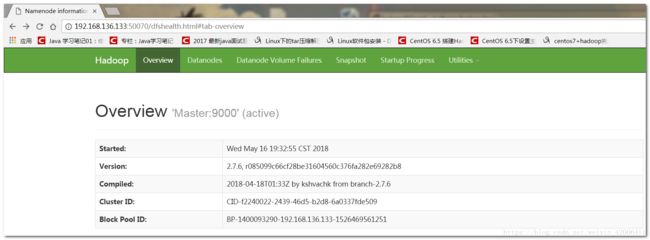
查看datanode数是不是自己配置的节点数,我配置的是2个。
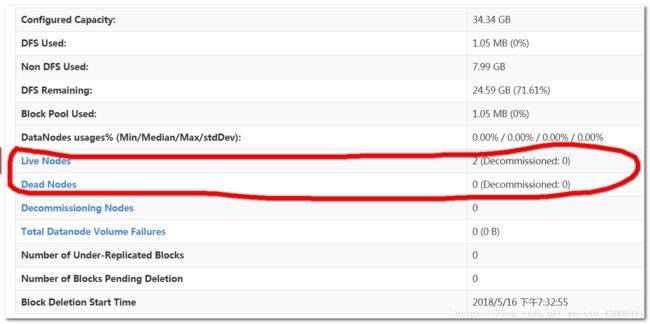
live Nodes 2个,表示hadoop完全分布式集群搭建成功了。