本章为查找图中的所有三角形
查找三角形的算法的思想

绘图1.png
本章实现方式
- 1.基于MapReduce实现
- 2.基于spark来实现
- 3.基于传统Scala来实现
++基于传统MapReduce来实现++
1. MapReduce实现的过程

image
2. MapReduce的实现类

image
3. Map端代码实现
public class GraphEdgeMapper extends Mapper{
LongWritable k2 = new LongWritable();
LongWritable v2 = new LongWritable();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String edge = value.toString().trim();
String[] nodes = StringUtils.split(edge, " ");
long nodeA = Long.parseLong(nodes[0]);
long nodeB = Long.parseLong(nodes[1]);
k2.set(nodeA);
v2.set(nodeB);
//生成两个相对边的集合
context.write(k2,v2);
context.write(v2,k2);
}
}

image
4. Reduce端代码实现
public class GraphEdgeReducer extends Reducer {
PairOfLongs k2 = new PairOfLongs();
LongWritable v2 = new LongWritable();
//这个类发出{(key,value),1} 的对和{(value1,value2),key}的对
@Override
protected void reduce(LongWritable key, Iterable values, Context context) throws IOException, InterruptedException {
ArrayList list = new ArrayList<>();
v2.set(0);
for(LongWritable value : values){
list.add(value.get());
k2.set(key.get(),value.get());
context.write(k2,v2);
}
Collections.sort(list);
v2.set(key.get());
for(int i=0;i 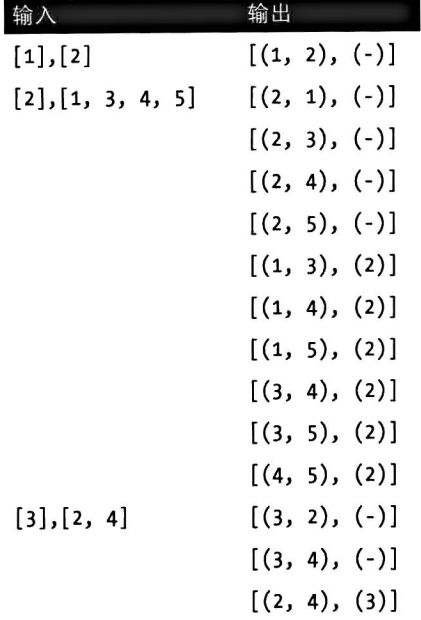
image
public class TriadsReducer extends Reducer {
static final Text EMPTY = new Text("");
@Override
protected void reduce(PairOfLongs key, Iterable values, Context context) throws IOException, InterruptedException {
ArrayList list = new ArrayList<>();
boolean haveSeenSpecialNodeZero = false;
for(LongWritable value : values){
long node = value.get();
if(node ==0){
haveSeenSpecialNodeZero = true;
}else{
list.add(node);
}
}
if(haveSeenSpecialNodeZero){
if (list.isEmpty()){return;}
Text triangle = new Text();
for(long node : list){
String triangleAsString = key.getLeftElement()+","+key.getRightElement()+","+node;
triangle.set(triangleAsString);
context.write(triangle,EMPTY);
}
}
else {
// no triangles found
return;
}
}
}

image
5.最后对三角形的中重复值去重即可
++基于传统spark来实现++
JavaSparkContext ctx = SparkUtil.createJavaSparkContext("count-triangles");
JavaRDD lines = ctx.textFile(inputPath);
JavaPairRDD edges = lines.flatMapToPair(new PairFlatMapFunction() {
@Override
public Iterator> call(String s) throws Exception {
String[] tokens = s.split(",");
long start = Long.parseLong(tokens[0]);
long end = Long.parseLong(tokens[1]);
//返回两组边的集合
return Arrays.asList(new Tuple2(start, end), new Tuple2(end, start)).iterator();
}
});
//对key进行排序
JavaPairRDD> triads = edges.groupByKey();
//发出三角形表的对
JavaPairRDD, Long> possibleTriads = triads.flatMapToPair(new PairFlatMapFunction>, Tuple2, Long>() {
@Override
public Iterator, Long>> call(Tuple2> s) throws Exception {
Iterable values = s._2;
List, Long>> result = new ArrayList, Long>>();
for (Long value : values) {
Tuple2 k2 = new Tuple2<>(s._1, value);
Tuple2, Long> k2v2 = new Tuple2, Long>(k2, 0l);
result.add(k2v2);
}
ArrayList valuesCopy = new ArrayList<>();
for (Long item : values) {
valuesCopy.add(item);
}
Collections.sort(valuesCopy);
for (int i = 0; i < valuesCopy.size(); i++) {
for (int j = i + 1; j < valuesCopy.size(); j++) {
Tuple2 k2 = new Tuple2<>(valuesCopy.get(i), valuesCopy.get(j));
Tuple2, Long> k2v2 = new Tuple2, Long>(k2, s._1);
result.add(k2v2);
}
}
return result.iterator();
}
});
JavaPairRDD, Iterable> triadsGrouped = possibleTriads.groupByKey();
JavaRDD> trianglesWithDuplicates = triadsGrouped.flatMap(new FlatMapFunction, Iterable>, Tuple3>() {
@Override
public Iterator> call(Tuple2, Iterable> s) throws Exception {
Tuple2 key = s._1;
Iterable values = s._2;
List list = new ArrayList<>();
boolean haveSeenSpecialNodeZero = false;
for (Long node : values) {
if (node == null) {
haveSeenSpecialNodeZero = true;
} else {
list.add(node);
}
}
List> result = new ArrayList>();
if (haveSeenSpecialNodeZero) {
if (list.isEmpty()) {
return result.iterator();
}
for (Long node : list) {
long[] aTraingle = {key._1, key._2, node};
Tuple3 t3 = new Tuple3(aTraingle[0],
aTraingle[1],
aTraingle[2]);
result.add(t3);
}
} else {
return result.iterator();
}
return result.iterator();
}
});
JavaRDD> uniqueTriangeles = trianglesWithDuplicates.distinct();
ctx.close();
System.exit(0);
++基于传统Scala来实现++
val sparkConf = new SparkConf().setAppName("CountTriangles")
val sc = new SparkContext(sparkConf)
val input = args(0)
val output = args(1)
val lines = sc.textFile(input)
//对边生成序列
val edges = lines.flatMap(line =>{
val tokens = line.split("\\s+")
val start = tokens(0).toLong
val end = tokens(1).toLong
(start,end)::(end,start):: Nil
})
val triads = edges.groupByKey();
val possibleTriads = triads.flatMap(tuple =>{
val values = tuple._2.toList
val result = values.map(v=>{
((tuple._1,v),0L)
})
//对后面的value进行排序
val sorted = values.sorted
val combinations = sorted.combinations(2).map{case Seq(a,b)=>(a,b)}.toList
combinations.map((_,tuple._1)) ::: result
})
val triadsGrouped =possibleTriads.groupByKey()
val triangleWithDuplicates = triadsGrouped.flatMap(tg =>{
val key = tg._1
val value = tg._2
val list = value.filter(_ !=0)
if(value.exists(_ ==0)){
if (list.isEmpty) Nil
list.map(l =>{
val sorteTriangle = (key._1 :: key._2 :: Nil).sorted
(sorteTriangle(0),sorteTriangle(1),sorteTriangle(2))
})
}else Nil
})
val uniqueTriangles = triangleWithDuplicates distinct
// For debugging purpose
uniqueTriangles.foreach(println)
uniqueTriangles.saveAsTextFile(output)
// done
sc.stop()