论文阅读 Object Detection in 20 Years: A Survey
原文:https://arxiv.org/abs/1905.05055v2
翻译:https://blog.csdn.net/clover_my/article/details/92794719
对入门来说是很有用的一篇综述,总结了目标检测近二十年的发展,阅读后可以清晰地获得目标检测方向的轮廓。(回顾了400余篇论文)甚至可以作为字典来查询。
本文涵盖了许多主题,包括历史上的里程碑检测器、检测数据集、度量、检测系统的基本构件、加速技术以及最新的检测方法。本文还综述了行人检测、人脸检测、文本检测等重要的检测应用,并对其面临的挑战以及近年来的技术进步进行了深入分析。
Object Detection :what object are where?
the basis of CV tasks :
- instance segmention
- image captioning
- object tracking
two research topics:
- general object detection: detect different types of objects under a unified framework to simulate the human vision and cognition
- detection application :the detection under specific application scenarios, such as pedestrian detection, face detection, text detection
A comprehensive review in the light of technical evolutions
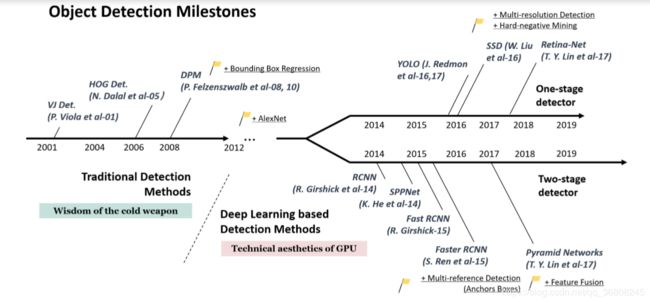
the early object detection algorithms:
- based on handcrafted features
- sophisticated feature representations
- a variety of speed up skills(limited computing resources)
VJ Det.
- sliding windows: to go through all possible locations and scales in an image to see if any window contains a human face.
- improve its detection speed : “integral image”, “feature selection”, and “detection cascades”.
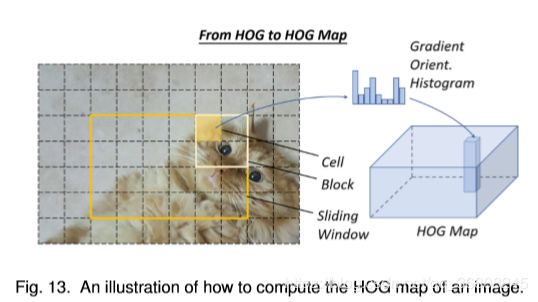
HOG Det.Histogram of Oriented Gradients方向梯度直方图
- an important improvement of the scale-invariant feature transform [33, 34] and shape contexts [35] of its time.
- improve accuracy:compute on a dense grid of uniformly spaced cells & use overlapping local contrast normalization (on “blocks”). balance the feature invariance (including translation, scale, illumination, etc) and the nonlinearity(on discriminating different objects categories)为了平衡特征不变性 ( 包括平移、尺度、光照等 ) 和非线性 ( 区分不同对象类别 ),将HOG描述符设计为在密集的均匀间隔单元网格上计算,并使用重叠局部对比度归一化 ( 在“块”上 ) 来提高精度。
- pedestrian detection
- To detect objects of different sizes, the HOG detector rescales the input image for multiple times while keeping the size of a detection window unchanged.
DPM
- “divide and conquer”, where the training can be simply considered as the learning of a proper way of decomposing an object, and the inference can be considered as an ensemble of detections on different object parts.
- “star-model”-> “mixture models”
- a root-filter and a number of part-filters:a weakly supervised learning method (all configurations of part filters can be learned automatically as latent variables) 所有零件滤波器的配置都可以作为潜在变量自动学习
- “hard negative mining”, “bounding box regression”, and “context priming” “硬负挖掘”、“边界框回归”、“上下文启动”
deep learning era:
- “two-stage detection” “coarseto-fine”
- “one-stage detection”“complete in one step”
RCNN
- It starts with the extraction of a set of object proposals (object candidate boxes) by selective search [42].
- Then each proposal is rescaled to a fixed size image and fed into a CNN model trained on ImageNet (say, AlexNet [40]) to extract features.
- Finally, linear SVM classifiers are used to predict the presence of an object within each region and to recognize object categories.
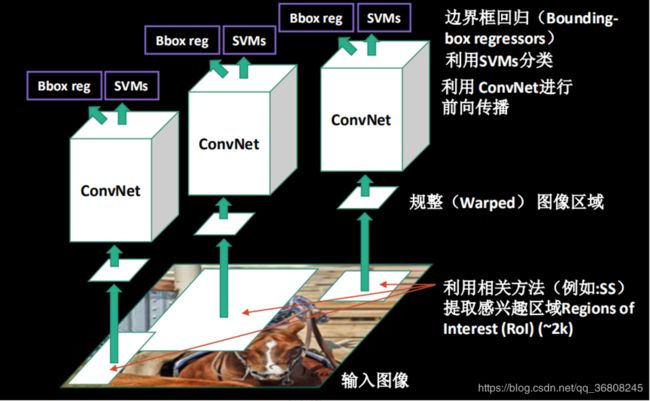
drawbacks : the redundant feature computations on a large number of overlapped proposals
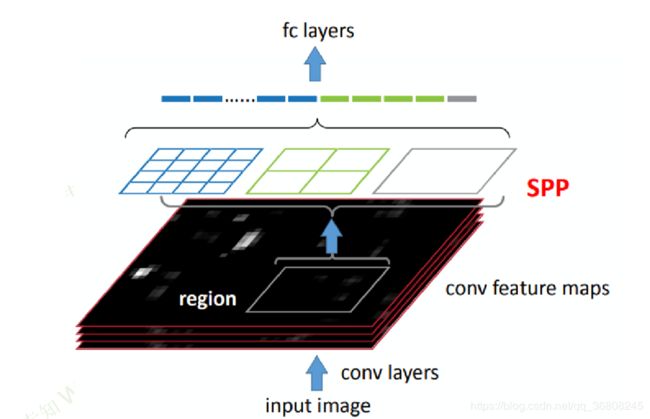
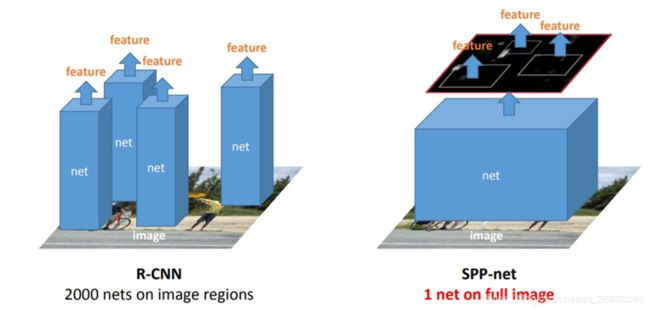
SPPNet
Spatial Pyramid Pooling (SPP) layer空间金字塔池化(SPP)层
- enables a CNN to generate a fixed-length representation regardless of the size of image/region of interest without rescaling it.
- the feature maps can be computed from the entire image only once, and then fixedlength representations of arbitrary regions 生成任意区域的定长表示can be generated for training the detectors, which avoids repeatedly computing the convolutional features.
- drawbacks: first, the training is still multi-stage,second, SPPNet only fine-tunes its fully connected layers while simply ignores all previous layers.第一,训练仍然是多阶段的,第二,SPPNet只对其全连接层进行微调,而忽略了之前的所有层
Fast RCNN
- simultaneously train a detector and a bounding box regressor under the same network configurations.在相同的网络配置下同时训练检测器和边界框回归器
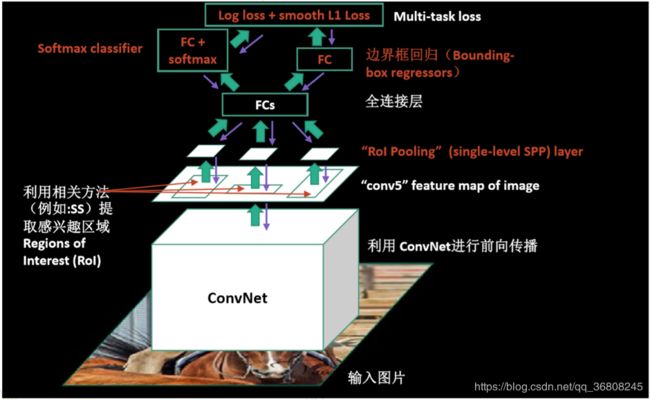
drawbacks:generate object proposals with a CNN model
most individual blocks of an object detection system, e.g., proposal detection, feature extraction, bounding box regression, etc, have been gradually integrated into a unified, end-to-end learning framework.
Faster RCNN
- the first end-to-end, and the first near-realtime deep learning detector
- Region Proposal Network (RPN) that enables nearly cost-free region proposals.
- drawbacks: computation redundancy at subsequent detection stage在后续的检测阶段仍然存在计算冗余
most of the deeplearning based detectors run detection only on a network’s top layer. Although the features in deeper layers of a CNN are beneficial for category recognition, it is not conducive to localizing objects.
Feature Pyramid Networks 特征金字塔网络 ( FPN )
- a topdown architecture with lateral connections(building high-level semantics at all scales). Since a CNN naturally forms a feature pyramid through its forward propagation, the FPN shows great advances for detecting objects with a wide variety of scales. 开发了具有横向连接的自顶向下体系结构,用于在所有级别构建高级语义。由于CNN通过它的正向传播,自然形成了一个特征金字塔,FPN在检测各种尺度的目标方面显示出了巨大的进步。
FPN has now become a basic building block of many latest detectors.
CNN based One-stage Detectors
You Only Look Once (YOLO)
- the first one-stage detector in deep learning era [20].
- YOLO is extremely fast:
- completely abandoned the previous detection paradigm of “proposal detection + verification”
- apply a single neural network to the full image.该网络将图像分割成多个区域,同时预测每个区域的边界框和概率。
- This network divides the image into regions and predicts bounding boxes and probabilities for each region simultaneously.
- suffers from a drop of the localization accuracy compared with two-stage detectors, especially for some small objects.
Single Shot MultiBox Detector (SSD)
- the multi-reference and multi-resolution detection techniques多参考和多分辨率检测技术, which significantly improves the detection accuracy of a one-stage detector, especially for some small objects.
- detection speed and accuracy:different scales on different layers of the network, while the latter ones only run detection on their top layers.
RetinaNet
- claimed that the extreme foreground-background class imbalance encountered during training of dense detectors is the central cause. 在密集探测器训练过程中所遇到的极端的前景-背景阶层不平衡是主要原因。
- a new loss function named “focal loss” by reshaping the standard cross entropy loss so that detector will put more focus on hard, misclassified examples during training. (Focal Loss enables the one-stage detectors to achieve comparable accuracy of two-stage detectors while maintaining very high detection speed.) 新的损失函数 “ 焦损失(focal loss)”,通过对标准交叉熵损失的重构,使检测器在训练过程中更加关注难分类的样本
Datasets
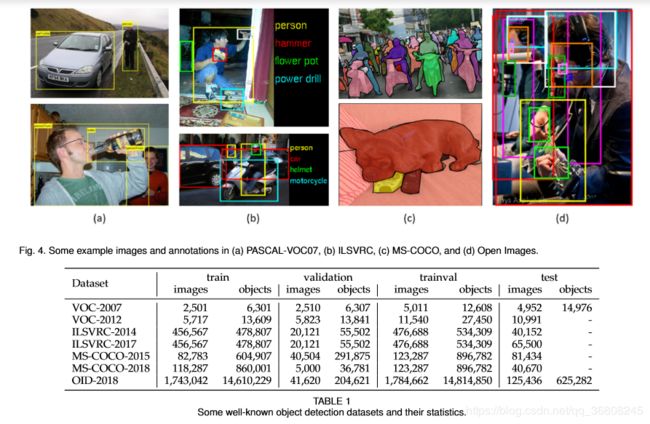
The popular datasets of some detection tasks:pedestrian detection, face detection, text detection, traffic sign/light detection, and remote sensing target detection. (Table2-6)
Metrics:FPPW-FPPI 、AP-mAP(0.5IoU)
To evaluate the effectiveness of an object detector
false positives per-window 》》false positives perimage .
每个窗口的漏报率与误报率 - 每图像的漏报率与误报率
An in-depth exploration of the key technologies and the recent state of the arts
这里专业名词变多啦!中文跟上。
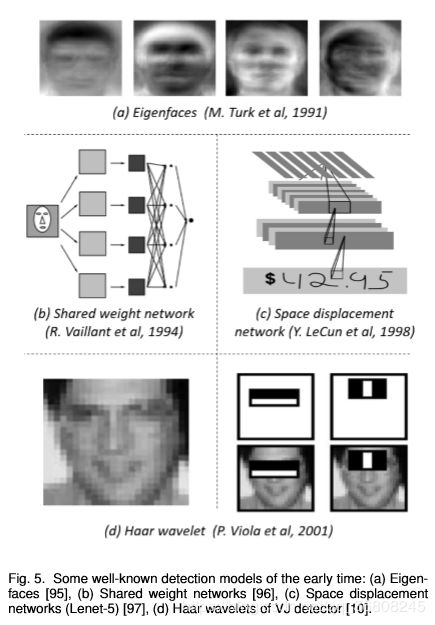
the statistical models of appearance (before 1998)
wavelet feature representations (1998-2005)
gradient-based representations (2005-2012)
基于机器学习的检测经历了包括外观统计模型在内的多个阶段 ( 1998年以前 ) 、小波特征表示 ( 1998-2005 ) 和基于梯度的表示 ( 2005-2012 )。
a:建立对象的统计模型 特征面(Eigenfaces)[95,106]如图5 (a)所示,是目标检测历史上第一波基于学习的方法。1991年,M.Turk等人利用特征脸分解技术在实验室环境中实现了实时人脸检测[95]。与当时基于规则或模板的方法相比[107,108],统计模型通过从数据中学习特定于任务的知识,更好地提供了对象外观的整体描述。
自2000年以来,小波特征变换开始主导视觉识别和目标检测。这组方法的本质是通过将图像从像素点转换为一组小波系数来学习。其中,Haar小波由于其计算效率高,被广泛应用于一般目标检测[29]、人脸检测[10,11,109],行人检测[30,31]等目标检测任务中。图5 (d)为VJ检测器学习到的一组用于人脸的Haar小波基[10, 11]。
Y. LeCun等人进行了一系列改进,如 “ 共享权值复制神经网络(shared-weight replicated neural network) ” [96]和 “ 空间位移网络(space displacement network) ” [97]通过扩展卷积网络的每一层,覆盖整个输入图像,减少计算量,如图5(b) - (c)所示。这样,只需一次网络的正向传播,就可以提取出整个图像任意位置的特征。这可以看作是当今全卷积网络 ( FCN ) 的原型[110,111],FCN 几乎是在20年后提出的。CNN也被应用于其他任务,如人脸检测[112,113]和手势实时跟踪[114](hand tracking of its time)。

特征金字塔和滑动窗口(2014年前) 专门针对具有 “ 固定长宽比 ” ( 如人脸和直立的行人 )的对象,只需构建特征金字塔,并在其上滑动固定大小检测窗口。当时没有考虑检测 “ 各种纵横比 ”通过训练多个模型来检测不同纵横比的物体
导致更加复杂的检测模型
基于对象建议的检测(2010-2015年) 引用一组可能包含任何对象的与类无关的候选框。
目标/对象建议检测算法应满足以下三个要求:1) 高召回率,2) 高定位准确率,3) 在前两个要求的基础上,提高精度,减少处理时间。
现代的建议检测方法可以分为三类:1) 分割分组方法[42, 117-119], 2) 窗口评分方法[116,120-122],3) 基于神经网络的方法[123-128]。
随着深度CNN在视觉识别领域的普及,基于自上而下学习的方法在这个问题上开始显示出更多的优势[19,121,123,124]。从那时起,对象建议检测就从自下而上的视觉演化为 “ 对一组特定对象类的过度拟合 ”,检测器与建议生成器之间的区别也变得模糊
深度回归(2013-2016)
近年来,随着GPU计算能力的提高,人们处理多尺度检测的方式变得越来越直接和暴力。使用深度回归来解决多尺度问题的思想非常简单,即,基于深度学习特征直接预测边界框的坐标[20,104]。这种方法的优点是简单易行,缺点是定位不够准确,特别是对于一些小对象。“ 多参考检测 ” 解决了这一问题。
多参考检测( multi-reference detection,2015年后 )
主要思想是在图像的不同位置预先定义一组不同大小和宽高比的参考框(即锚框),然后根据这些参考框预测检测框。
每个预定义锚框的典型损失包括两部分:1) 类别识别的交叉熵损失;2) 目标定位的L1/L2回归损失。
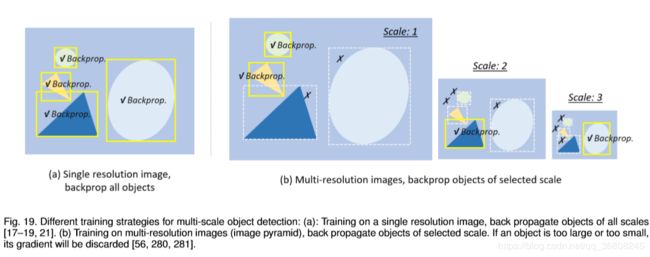
多分辨率检测( multi-resolution detection,2016年后 )
在网络的不同层检测不同尺度的目标。由于CNN在正向传播过程中自然形成了一个特征金字塔,更容易在较深的层中检测到较大的物体,在较浅的层中检测到较小的物体。多参考和多分辨率检测已成为当前最先进的目标检测系统的两个基本组成部分。
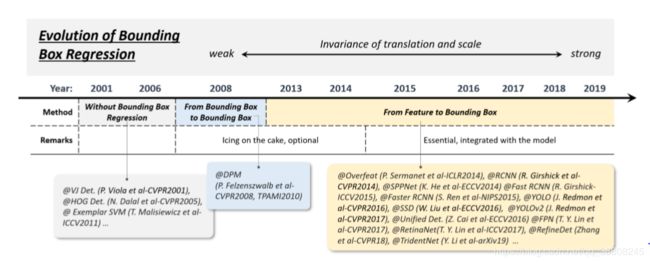
第一次将BB回归引入目标检测系统是在 DPM [15]中。那时的 BB 回归通常作为一个后处理块,因此它是可选的。第一次将BB回归引入目标检测系统是在 DPM [15]中。那时的 BB 回归通常作为一个后处理块,因此它是可选的。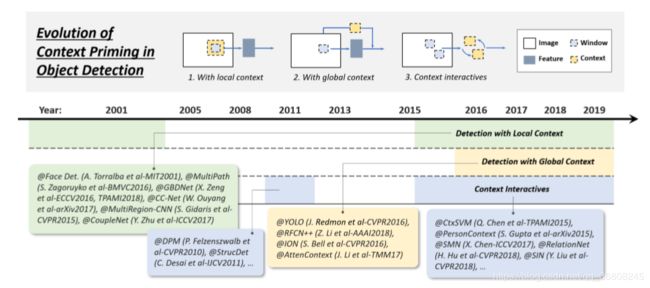 视觉对象通常嵌入到与周围环境一起的典型上下文中。我们的大脑利用物体和环境之间的联系来促进视觉感知和认知[160]。长期以来,上下文启动(Context priming)一直被用来改进检测。在其进化过程中,常用的方法有三种:1) 局部上下文检测,2) 全局上下文检测,3) 上下文交互。
视觉对象通常嵌入到与周围环境一起的典型上下文中。我们的大脑利用物体和环境之间的联系来促进视觉感知和认知[160]。长期以来,上下文启动(Context priming)一直被用来改进检测。在其进化过程中,常用的方法有三种:1) 局部上下文检测,2) 全局上下文检测,3) 上下文交互。

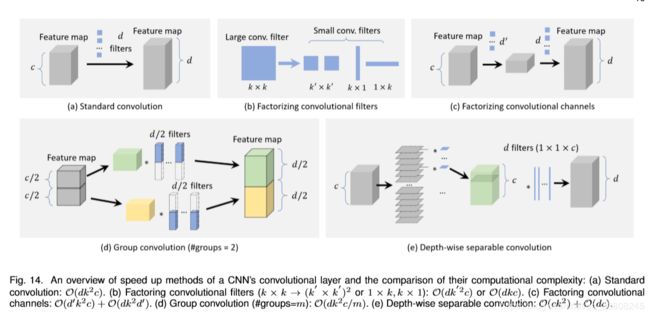
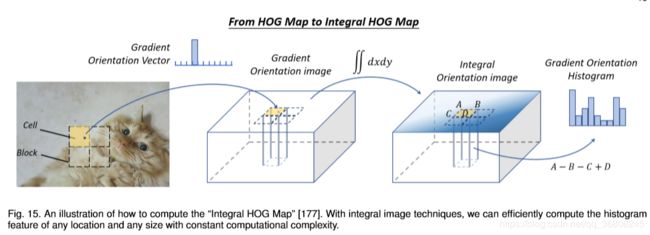
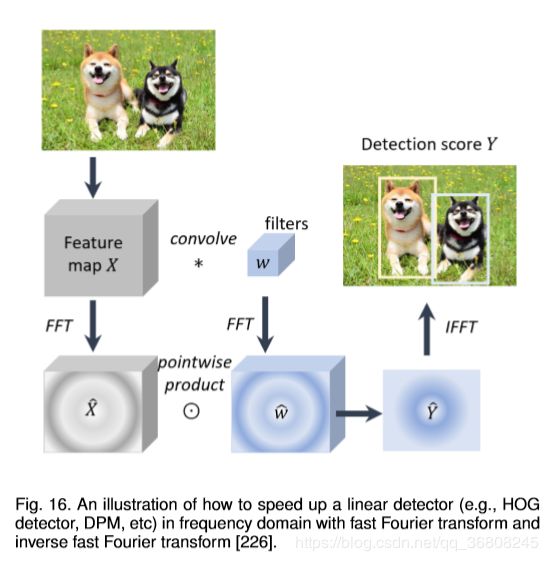
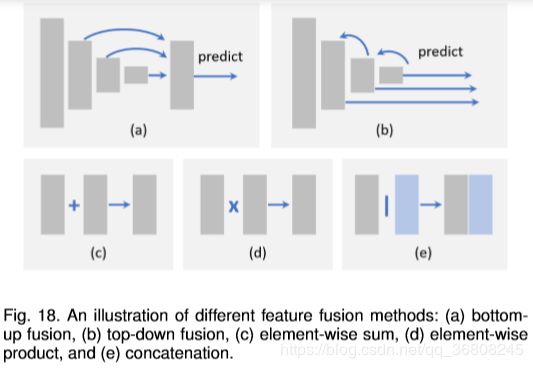
A comprehensive analysis of detection speed up techniques
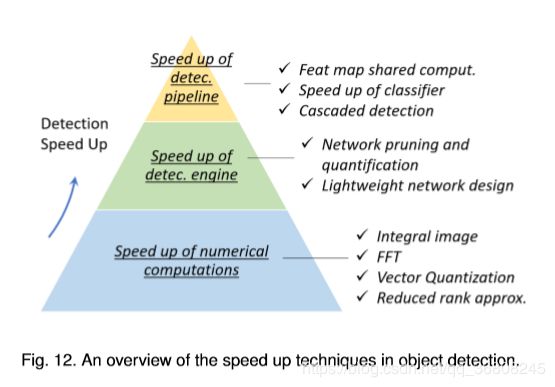
Difficulties and Challenges in Object Detection :
- object rotation and scale changes (e.g., small objects),
- accurate object localization,
- dense and occluded object detection,
- speed up of detection