数据结构与算法--基础篇
阅读目录
- 引入概念
- 时间复杂度和大“O”记法
- Python内置类型性能分析
- timeit模块
- list的操作测试
- dict字典内置操作的时间复杂度
- 数据结构与ADT
- 抽象数据类型(Abstract Data Type)
- 算法与数据结构的区别
- 算法与数据结构大致分类
- 线性结构
- 非线性结构
- 需要学习的
引入概念
# 如果 a+b+c=1000,且a^2+b^2=c^2,求所有的a.b.c的组合可能
# 普通的循环方法:
import time
start_time = time.time()
# 注意是三重循环
for a in range(0, 1001):
for b in range(0, 1001):
for c in range(0, 1001):
if a ** 2 + b ** 2 == c ** 2 and a + b + c == 1000:
print("a, b, c: %d, %d, %d" % (a, b, c))
end_time = time.time()
print("elapsed: %f" % (end_time - start_time))
print("complete!")

重要的是思想,而不是靠哪种语言实现
每台机器执行的总时间不同,但是执行的基本预算量大体相同
# 第二次尝试
import time
start_time = time.time()
# 注意是两重循环
for a in range(0, 1001):
for b in range(0, 1001 - a):
c = 1000 - a - b
if a ** 2 + b ** 2 == c ** 2:
print("a, b, c: %d, %d, %d" % (a, b, c))
end_time = time.time()
print("elapsed: %f" % (end_time - start_time))
print("complete!")
'''
a, b, c: 0, 500, 500
a, b, c: 200, 375, 425
a, b, c: 375, 200, 425
a, b, c: 500, 0, 500
elapsed: 1.356157
complete!
'''
时间复杂度和大“O”记法
时间复杂度,就是要计算的步骤基本数量总和

如何理解大“O”记法

最坏时间复杂度

时间复杂度的几条基本计算规则

# 第一次尝试
for a in range(0, 1001):
for b in range(0, 1001):
for c in range(0, 1001):
if a**2 + b**2 == c**2 and a+b+c == 1000:
print("a, b, c: %d, %d, %d" % (a, b, c))
# 时间复杂度:T(n) = O(n*n*n) = O(n3)
# 第二次尝试
for a in range(0, 1001):
for b in range(0, 1001-a):
c = 1000 - a - b
if a**2 + b**2 == c**2:
print("a, b, c: %d, %d, %d" % (a, b, c))
# 时间复杂度:T(n) = O(n*n*(1+1)) = O(n*n) = O(n2)
常见的时间复杂度

常见时间复杂度之间的关系

Python内置类型性能分析
timeit模块
'''
timeit模块可以用来测试一小段Python代码的执行速度。
class timeit.Timer(stmt='pass', setup='pass', timer=)
Timer是测量小段代码执行速度的类。
stmt参数是要测试的代码语句(statment);
setup参数是运行代码时需要的设置;
timer参数是一个定时器函数,与平台有关。
timeit.Timer.timeit(number=1000000)
Timer类中测试语句执行速度的对象方法。number参数是测试代码时的测试次数,默认为1000000次。方法返回执行代码的平均耗时,一个float类型的秒数。
'''
list的操作测试
from timeit import Timer # 从timeit模块中导入Timer类
def t1():
l = []
for i in range(1000):
l = l + [i] # 列表加操作
# l+=[i] 用简写方式会更快
def t2():
l = []
for i in range(1000):
l.append(i) # 调用函数添加
def t3():
l = [i for i in range(1000)] # 列表生成器
def t4():
l = list(range(1000)) # 将可迭代对象直接生成列表
def t5():
l = []
for i in range(10000):
l.extend([i]) # extend 将整个可变对象添加进去
from timeit import Timer
t1 = Timer("t1()", "from __main__ import t1")
print("concat ", t1.timeit(number=1000), "seconds")
t2 = Timer("t2()", "from __main__ import t2")
print("append ", t2.timeit(number=1000), "seconds")
t3 = Timer("t3()", "from __main__ import t3")
print("comprehension ", t3.timeit(number=1000), "seconds")
t4 = Timer("t4()", "from __main__ import t4")
print("list range ", t4.timeit(number=1000), "seconds")
t5 = Timer("t5()", "from __main__ import t5")
print("extend", t5.timeit(number=1000), "seconds")
# ('concat ', 1.7890608310699463, 'seconds')
# ('append ', 0.13796091079711914, 'seconds')
# ('comprehension ', 0.05671119689941406, 'seconds')
# ('list range ', 0.014147043228149414, 'seconds')
# test5 extend 比单独的加 会更快一点
list中 append 和 insert的快慢
def t6():
li = []
for i in range(10000):
li.append(i)
def t7():
li = []
for i in range(10000):
li.insert(0, i) # 在前面添加一个元素的方法
timer6 = Timer("t6()", "from __main__ import t6")
print("append", timer6.timeit(1000))
timer7 = Timer("t7()", "from __main__ import t7")
print("append", timer7.timeit(1000))
# append 更快,往后面添加数据更快,因为列表是栈数据类型的
pop操作测试
x = range(2000000)
pop_zero = Timer("x.pop(0)", "from __main__ import x")
print("pop_zero ", pop_zero.timeit(number=1000), "seconds")
x = range(2000000)
pop_end = Timer("x.pop()", "from __main__ import x")
print("pop_end ", pop_end.timeit(number=1000), "seconds")
# ('pop_zero ', 1.9101738929748535, 'seconds')
# ('pop_end ', 0.00023603439331054688, 'seconds')
# 从结果可以看出,pop最后一个元素的效率远远高于pop第一个元素
list内置操作的时间复杂度

'''
index[] 索引取值
index assignment 按照索引的方式赋值
pop(i) 从指定位置剔除, 最坏复杂度,所以是O(n)
del 代表一个元素一个元素都要去清空
iteration 迭代 如使用for操作
contains(in) 使用in 操作符,也需要遍历一遍
get slice[x:y] 取切片 O(k) 先定位x只需要O(1),在定位到Y,这时只跟距离有关系,和n没关系
del slice 删除后,会将元素往前移
set slice 设置 会先删除,然后再补充,所以是O(n+k)
# li=[1,2,3,4,5,6]
# li[0:3]=[8,9,10,11] 切片赋值
reverse 逆置
concatenate 加的操作,将第二个列表中的元素补充进去,
指的是第二个列表中有多少个元素,所以只和K有关
'''
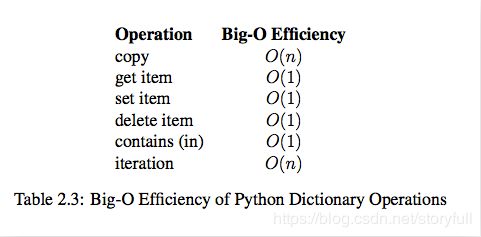
dict字典内置操作的时间复杂度
数据结构与ADT
抽象数据类型(Abstract Data Type)
'''
抽象数据类型(ADT)的含义是指一个数学模型以及定义在此数学模型上的一组操作。
即把数据类型和数据类型上的运算捆在一起,进行封装。
引入抽象数据类型的目的是把数据类型的表示和数据类型上运算的实现与这些数据类型和运算在程序中的引用隔开,使它们相互独立。
最常用的数据运算有五种:
插入、删除、修改、查找、排序
class Stus(object):
def adds(self)
def pop:
def sort
def modify
# 先定义好数据结构sturs将数据保存好,看这个数据结构支持哪些操作、
定义出来(相当于提供接口)
这样的整个过程就是抽象数据类型(ADT)
'''
解决一组数据如何保存,它的保存形式是怎么样的,
数据结构就是对 基本数据类型的一次封装
'''
name age hometown
# 如果用列表来存
[("zhangsan", 24, "beijing"),
("zhangsan", 24, "beijing"),
("zhangsan", 24, "beijing"),
]
# 如何取出
for stu in stus:
if stu(0)== "zhangsan":
# 第二种,列表中嵌套字典
[{"name":"zhangsan","age":23,"hometown":"beijing"},]
#用字典来存
{"zhangsan":{"age":24,"hometown":""},}
# 取出,直接用键就可以了
stus["zhangsan"]
'''
算法与数据结构的区别
'''
数据结构只是静态的描述了数据元素之间的关系。
高效的程序需要在数据结构的基础上设计和选择算法。
程序 = 数据结构 + 算法
总结:算法是为了解决实际问题而设计的,数据结构是算法需要处理的问题载体
'''
算法与数据结构大致分类
线性结构

非线性结构
二维数组,多为数组,广义表,树结构,图结构
需要学习的
'''
稀疏SPARSEARRAY数组 和 队列
链表:
单链表;双链表
JOSEPHU问题(单向环形列表)
栈:
递归:
排序算法:
冒泡;选择;插入;希尔;快速;归并;基数
查找算法:
二分查找;插值查找;斐波那契查找
哈希表:
树结构基础:
二叉树;顺序存储二叉树;线索化二叉树
树结构实例应用:
堆排序;赫夫曼树;赫夫曼编码;二叉排序树;平衡二叉树(AVL树)
多路查找树:
二叉树与B树;2-3树;B树、B+树和B*树
——————————
图:
——————————
程序员常用的10种算法:
二分查找;分治算法;动态规划算法;KMP算法;贪心算法;
普里姆算法;克鲁斯卡尔算法;迪杰斯特拉算法;弗洛伊德算法;
马踏棋盘算法
'''