零基础读懂分布式系统
一文读懂分布式系统究竟是什么,掌握讨论区块链的正确姿势。
撰文:李画
致谢:Genaro CTO 吴为龙
区块链是一种分布式系统。不了解分布式系统的工作原理,很难真正理解区块链。
而不理解区块链的麻烦,在于会陷入到对「去中心化」、 「无需许可」等等概念以及「TPS」、「安全」等等问题失去语境的讨论中去。这不仅无助于我们去准确地分析和判断一个区块链项目,也让我们无法认清区块链在技术上的可能的发展路线。
更直白来讲,我们需要掌握分布式系统的一些基础知识。因为这样,我们就能看到区块链本身的局限性,我们就知道任何一个真正有价值的区块链项目都应该:为了解决特定的问题,在特定的环境中,做出特定的解决方案。
单纯的指标比较并不客观,更好的判断标准是:这种方案是否适合于解决这个问题。
了解分布式系统的工作原理对区块链世界非常重要。那么现在,就让我们开启分布式系统的探索之旅吧。
计算机的作用是处理信息,我们输入条件 A 给它,它输出结果 B 给我们。如果处理信息的工作是由一台计算机完成的,这是一种中心化的结构;如果处理信息的工作是由多台独立的计算机合作完成的,我们可以称其为「分布式的系统」。
分布式系统有多种不同的架构,用以实现不同的处理信息的方法。假设系统中有十台计算机,一种架构是:我们把一个计算任务分成十份,让每台计算机独立处理一份任务,最后汇总它们的计算结果,作为输出。
还有另一种架构,就是让这十台计算机都去处理这一个计算任务,如果所有的计算机都正常工作,它们的计算结果应该是一样的,那么就把这个一致的计算结果作为输出。区块链就是这样的一种分布式系统。
很容易就能发现,这是一个「自找苦吃」的系统,它相当于把同样的工作做了十次,而且还需要额外增加不同计算机之间的沟通工作。
那为什么还需要这种系统?因为它可以让我们免除对中心化的那一台计算机,以及那台计算机背后的中心化的公司或组织的依赖。这样一来,既能避免单点故障或作恶,也能减少权力的集中及滥用。
一、分布式系统的理想目标
区块链所属的分布式系统也被称为「复制状态机模型」(Replicated State Machine),它的目标很简单:系统内全部的计算机都同意某一个输出值,也就是指:系统内所有的节点 / 计算机都有相同的初始状态,在执行完一个事务后,所有的节点都有相同的最终状态 。
如果计算机都运行良好,它们之间的通信也完全同步,实现这个目标并不困难。但现实不是如此,主要有以下两类问题:
某台 / 某些计算机出现故障,它可能无法计算出结果,也可能连接不上系统。
如果不同计算机收到事件的顺序不同,对事件的处理顺序就会不同,导致输出结果也不同。比如(a+b)×c 与 a+(b×c)就是两种不同的计算顺序,会带来不同的计算结果。
这些问题是常见且不可避免的,而一旦出现问题,就无法实现全部的计算机都同意某一个输出结果。著名的分布式系统「FLP 不可能原理」是这样描述的:在网络可靠,但允许节点失效的最小化异步模型系统中,不存在一个可以解决一致性问题的确定性共识算法。通俗而言就是:只要系统中有一台计算机出问题,该系统就无法在输出值上达成共识。
FLP 不可能原理告诉我们:不要浪费时间去为分布式系统设计面向所有场景的共识算法,那是不可能实现的。
二、分布式系统的共识算法
虽然 FLP 不可能原理很残酷,但分布式系统能够带来的好处是值得我们迎难而上的。既然不存在面向所有场景的共识算法,那么也许可以找到一些在特定场景中有效的共识算法。共识算法,是指让分布式系统达成共识的方法。
让我们看看科学家们是如何一步一步限定场景,并实现该场景下的共识算法的。
首先,如果系统中的每一台计算机都可以提出自己的结果,场面无疑是复杂的,因为我们连就哪一个结果去达成共识都无法知晓。所以解决共识问题的第一步是确定共识的到底是什么,最简单的方法就是某一台计算机说了算,它提出一个结果,其他的计算机来表态是否同意这个结果。
说了算的那台计算机被称为提案者或者领导者。虽然通过领导者来实现共识并不是唯一解决问题的方法,但绝大多数协议都是在此基础上实现的,包括区块链系统中使用的共识算法。
所以你看,并没有绝对的去中心化,实现共识的第一步就是要确定一个中心。
题外话:当我们知道这一点后,就能建立起关于去中心化的更有效的讨论,比如在此处就可以不泛泛而谈去中心化,而是:选出这个领导者的方法是否去中心化。
回到主题。需要领导者的共识算法的工作步骤大致是这样的:
选出一个领导者;
领导者提出一个结果;
追随者确定是否同意这个结果;
如果大家就结果达成了共识,系统输出最终结果;如果大家未达成共识,回到步骤 1 重新开始。
这种思路提供了一种可以达成共识的方法,但它离真正实现共识还很遥远。因为如果一台计算机连接不上系统,它就无法表决自己是否同意领导者的结果;如果出现问题的计算机恰好是领导者,情况就会更糟糕,整个系统会进入停滞状态。
三、同步性假设共识算法
如何解决上述宕机的问题?方法说起来很简单:如果一台计算机连不上系统,就忽略它,不要它参与这一轮的共识。
那么新的问题来了,我们怎么知道它是连接不上系统,还是它正在参与共识只不过速度比别的机器慢?
因此,科学家们发展出了解决共识问题的最重要的一个假设:同步性假设。同步性假设引入「超时」概念,也就是说事先设定一个时间范围,如果领导者无法在该时间范围内发出提案,就淘汰它,选出一个新的领导者。这样一来就可以容忍领导者节点出现问题。(注:同步性假设不等于同步假设)
Paxos 算法和 Raft 算法都是基于同步性假设提出来的。但这两个算法还需要对系统做另一种假设,即认为系统内所有的计算机都是「好人」,它们要么正确地响应领导者的提案,要么因为故障无法响应。
然后再制定一条规则:只要系统内过半数的计算机接受了领导者的提案,就把该提案作为系统的最终结果。这样一来,就不用等待所有的计算机都做出响应,从而可以容忍追随者节点出现问题。
于是,我们终于拥有了一个可以实现共识的分布式系统,虽然对它有严格的条件限定。
Paxos 共识算法是由莱斯利·兰伯特(Leslie Lamport)在 1990 年提出的一种基于消息传递且具有高度容错特性的一致性算法,它在分布式系统应用领域有着重要的地位,包括 Google 在内的许多公司的大型分布式系统采用的都是该算法。而我们第一阶段的探索也可以在此处结束,接下来是第二阶段。
四、解决掉系统中的「坏人」
Paxos 虽然能实现共识,但它的算法是建立在所有计算机都是「好人」的基础上的,这些计算机要么沉默,要么发出正确的声音,因此整个系统中只有一种声音,大家就这个声音达成共识即可。而如果计算机中有「坏人」,系统里就会出现坏人的声音和好人的声音,Paxos 算法无法处理这一情况。
我们需要在有坏人的情况下也可以实现共识的算法,有没有可能?莱斯利·兰伯特建立了一个模型来讨论这种可能性,该模型被称作拜占庭将军问题,其中的拜占庭节点就是坏人节点,它们会传递干扰信息阻碍整个系统达成共识。
在论文《The Byzantine Generals Problem》中,兰伯特提出了几种解决方案,其中一种可以在拜占庭节点不到 1/3 时实现系统的共识。也就是说,如果系统中坏人的数量少于 1/3,就可以通过算法实现共识。
这之后出现的 DLS 算法、PBFT 算法(实用拜占庭容错算法)都是在此基础上发展出来的。
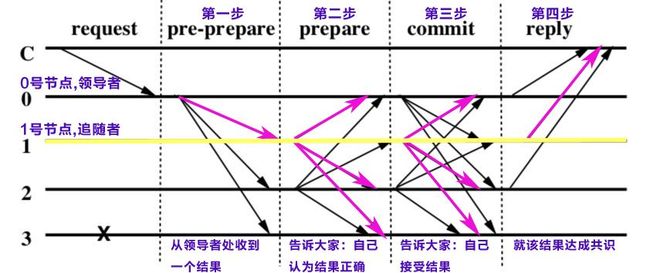
PBFT 是具有代表性的一种拜占庭容错算法,其实现过程大致如下。不理解该过程也没关系,知道通过这种沟通方式能够达成共识就可以。
pre-prepare 阶段:领导者发送结果给所有追随者。领导者在本图中是 0 号节点,它把结果发给追随者 1、2、3 号节点。
prepare 阶段:如果追随者认为结果没有错误,就告诉所有其他节点自己认可这个结果。比如 1 号节点会把自己的认可消息发给 0、2、3 号节点。
commit 阶段:如果追随者发现超过 2/3 的节点认可了领导者的结果,就告诉所有其他节点自己接受这个结果为最终结果。
reply 阶段:如果领导者和追随者发现超过 2/3 的节点接受了最终结果,就可以认为大部分节点达成了共识,就把该共识反馈给客户端;如果客户端收到超过 1/3 的节点的相同的共识,就可以认为全网达成了共识。
到此,我们就解决了有拜占庭节点的分布式系统的共识问题。不过如果系统中坏人的数量等于或多于 1/3,依然是无法达成共识的。我们能做的是通过系统的准入条件或激励措施,让坏人可以少于 1/3。
对分布式系统的第二阶段的探索到这里就结束了,接下来进入到第三阶段。
五、中本聪共识算法
不管 Paxos 还是 PBFT,都使用了同步性假设,事实上,大家对共识算法的研究几乎都是在该方向上的,直到中本聪共识的出现。中本聪共识使用的是非确定性机制。
这是什么意思呢?我们可以把一个由 12 台计算机组成的分布式系统想象成一个由 12 名陪审员组成的陪审团。我们把这 12 个人关在会议室里,递进去一张纸条阐述案情,然后坐在会议室门口等他们给出审理的结果。
这 12 个人对于如何判决会有不同的意见,随着讨论的深入也可能改变自己的立场,还有的人可能睡着了无法发表看法(参考《十二怒汉》)。那么坐在门口等的人有两种选择。第一种选择是你们去讨论吧,让我等多久都可以,但最后你们给我的必须是唯一确定的审理结果;第二种选择是我等不了,你们先把最多人同意的那个结果给我,如果之后出现一个更多人同意的结果,我再改成那个结果。
显而易见,我们只能二选一,如果要求结果确定,就不能保证一定能等到结果;如果要求拿到结果,就无法保证该结果一定是最终结果。
分布式系统就是这样,只能二选一,第一种选择被称作 Finality,即「结果的确定性」或安全性;第二种选择被称作 Liveness,即网络的活性或可用性。
这两种选择决定了分布式共识两种不同的设计思路:
追求 Finality,是优先结果,就要对网络做出要求。PBFT、Tendermint 都是这一类型的算法,它们走的是网络的同步性假设路线,使用这类算法的系统不会出现分叉。
追求 Liveness,是优先网络,就要对结果做出让步。中本聪共识是这一类型的算法,它走的是结果的非确定性路线,使用这类算法的分布式网络始终可用,而且任意节点都可以随时加入 / 离开系统。
题外话,在 Finality 和 Liveness 中二选一也是分布式系统 CAP 定理(不可能三角)的体现。该定理说的是:对于一个分布式系统来说,不可能同时满足一致性、可用性和分区容错性。因为分区容错性是指该系统要能容忍网络出现分区,而现实网络是一定会分区的,所以这个条件必须满足,那么实际上,CAP 定理说的是一个分布式系统不可能同时满足一致性和可用性,这其中,CAP 一致性体现的是 Finality,CAP 可用性体现的是 Liveness。
而不管是 FLP 不可能原理,还是 CAP 不可能定理,它们不是在告诉我们:这条路很难走通,你如果突破就是了不起的创新;它们告诉我们的是:这条路走不通,你要做的是根据需求来做权衡和选择。
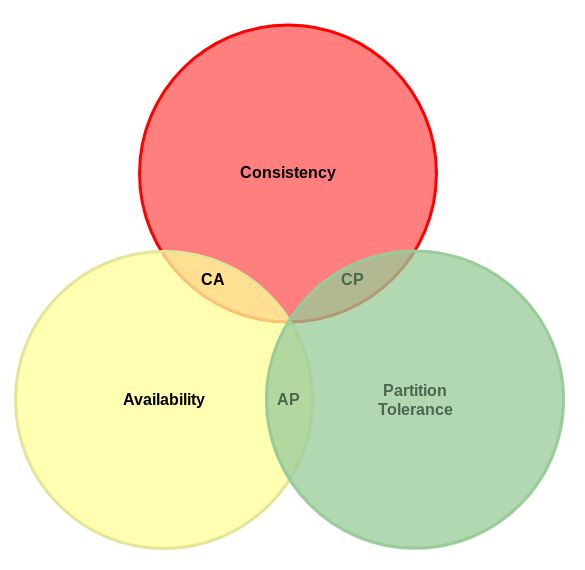
使用同步性假设的共识算法在前文已经详细地介绍过了,它们通过引入超时概念忽略出现问题的计算机,从而达成共识。
使用非确定性机制的中本聪共识描述起来也很简单:如果你看到某提议的区块拥有最多的工作量证明,就接受该区块,这也被称作最长链规则。它的具体实现过程大家都很熟悉,本文就不再赘述了。
现在,让我们看看使用同步性假设的系统(Finality,PoS 中使用较多)和使用非确定性机制的系统(Liveness,PoW 中使用较多)有什么不同。但需要提醒的是,并非所有的 PoS 都是 Finality 路线,比如 Casper FFG 就不是;而 PoW 也不是只能走 Liveness 路线,虽然并没有人设计 PoW 上的 Finality 共识。
PoW 和 PoS 的不同在于一个是 Work,一个是 Stake。之所以需要强调这一点,是因为在关于 PoW 和 PoS 的讨论中,我们往往不是在讨论 Work 机制与 Stake 机制的不同,而是在比较 Finality 系统与 Liveness 系统的不同。比如「无需许可」性,它基本是一个 Finality 系统与 Liveness 系统的话题,而不是 Work 与 Stake 的争论点。
让我们回到有 12 个评审员的会议室。为了追求 Finality,每个评审员都需要了解其他每一个人的想法,也需要把自己的想法告诉其他每一个人,因此通信复杂度会随着评审员人数的增加而迅速递增,整个系统将因此不可用,所以必须控制陪审员的数量。
那么对于一个分布式系统而言就是,只挑选少数节点进入会议室,由它们决定共识,而其他节点只接受共识。因此这种系统中有三种角色,领导者、追随者和学习者,领导者和追随者是会议室中的评审员,他们需要好好工作,不然可能导致系统无法达成共识。
中本聪共识追求的是 Liveness,节点 / 评审员不需要与其他的每一个节点沟通,它只需要与自己身边的节点交流即可,因此通信复杂度不会因为节点数量的增加而增加。你想成为评审员,就可以走进会议室成为评审员,无需许可,也不会增加陪审团达成共识的难度,同时你也可以不工作或随时离开。该系统中只有领导者和追随者两种角色,所有人都在那间会议室里参与共识。
这样看来中本聪共识似乎更符合大家对分布式系统的开放性的期望,但别忘了它之所以可以如此设计,是因为牺牲了 Finality,它的输出结果是一个概率上的最终结果。
试想,你百分百在星巴克得到一杯咖啡,但星巴克并不能百分百收到钱,这并不符合大多数人能理解的世界运转规则。所以非确定性机制有它自己的短板,以及不适合的场景。
另一方面,Finality 系统在保证了结果的确定性后,系统设计就要反过来追求 Liveness;而 Liveness 系统在保证了网络的开放性后,系统设计就要反过来追求 Finality。中本聪共识为了提高结果的确定性或安全性,就需要做出其他让步,比如 TPS。
以比特币为例。比特币可以把出块时间从 10 分钟提高到 1 分钟,TPS 会大幅提升,但 1 分钟的时间不够把消息传遍全网,系统中就会出现很多分叉,导致结果的可确定性变低;比特币也可以把区块大小从 1MB 提高到 100MB,TPS 也会提升,但大区块对网络和节点的要求高,会增加节点的进入门槛从而带来中心化,导致输出结果容易被篡改。
所以你看,设计分布式系统就像与撒旦做交易,你得到一些,必然要交出一些。没有最好的系统,只有适合解决某类问题的系统;没有单纯的指标比较,只有是在什么设定下实现这种指标。
如果你理解了这一点,这篇文章的目的就达到了,而我们对分布式系统的探索到此也就全部结束了。
六、更进一步
本文是受《How Does Distributed Consensus Work?》一文启发写成的,如果你想更进一步了解分布式系统,推荐这篇文章,它从专业的角度介绍了分布式共识;同时推荐《WHAT WE TALK ABOUT WHEN WE TALK ABOUT DISTRIBUTED SYSTEMS》,它系统地罗列出了分布式系统的经典论文。
链闻注:
- How Does Distributed Consensus Work?
https://medium.com/s/story/lets-take-a-crack-at-understanding-distributed-consensus-dad23d0dc95
- 中文译本《分布式共识的工作原理》,by EthFans
https://ethfans.org/posts/lets-take-a-crack-at-understanding-distributed-consensus-part-1
- WHAT WE TALK ABOUT WHEN WE TALK ABOUT DISTRIBUTED SYSTEMS
http://alvaro-videla.com/2015/12/learning-about-distributed-systems.html
分布式系统的另一个关键问题是时序,所有的共识算法都需要解决它,但因为是另一条线索故本文未做涉及,如果你想了解,可以从莱斯利·兰伯特博士(how old are you)的这篇论文开始:《Time, Clocks and the Ordering of Events in a Distributed System》。
如果你对在 Finality 和 Liveness 间寻找平衡感兴趣,可以去研究 Casper FFG 共识,它有 Liveness 的一部分,也有 Finality 的一部分。同时你也会发现 Casper FFG 的 PoS 与 Tendermint 的 PoS 的不同。
最后对本文做一个小结,它主要包含以下内容:
两个定理:FLP 不可能原理;CAP 不可能定理。
两种容错能力:宕机容错;拜占庭容错。
两种共识算法设计思路:Finality;Liveness。
两类共识算法:同步性假设;非确定性机制。
三个共识算法:Paxos、PBFT、中本聪共识。
文中会有因简化和类比带来的不准确以及不全面之处,还望理解,谢谢指正。
参考资料:
1.《How Does Distributed Consensus Work?》,Preethi Kasireddy;中文版本:《分布式共识的工作原理》,by EthFans,由 Ray、阿剑、IAN LIU、stormpang、安仔翻译
2.《WHAT WE TALK ABOUT WHEN WE TALK ABOUT DISTRIBUTED SYSTEMS》,Alvaro Videla
3.《Time, Clocks and the Ordering of Events in a Distributed System》,Leslie Lamport
4.《The Byzantine Generals Problem》,LESLIE LAMPORT、ROBERT SHOSTAK、MARSHALL PEASE
5.《Paxos Made Simple》,Leslie Lamport
6.《Bitcoin: A Peer-to-Peer Electronic Cash System》,Satoshi Nakamoto
专题 | 精选以太坊 DeFi 项目列表
专题详细内容请点击「阅读原文」查看

DeFi 即 Decentralized Finance,必定是 2019 年的最热词组。Block123 与链闻 ChainNews 精选了以太坊上最具代表性的 DeFi 创业项目、应用及资源列表。他们正积极地抱团、共建一套全新的「开放式金融」体系。


「精选以太坊 DeFi 项目列表 」