关于逻辑回归的思考
文章目录
- 关于逻辑回归的思考
- 1.问题的引出
- 2.sigmod函数
- 例1
- 例2
- 对比发现
- 逻辑回归是如何做到分类的?
- 1.模型
- 2.策略
- 损失函数
- 3.算法
- 采用梯度下降算法求解参数 Θ \Theta Θ
- 总结:
关于逻辑回归的思考
1.问题的引出
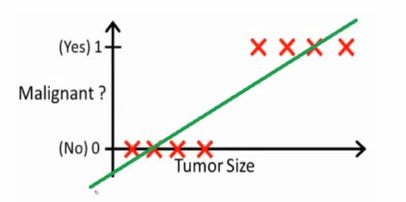
问题是:

- 如果出现
断崖式的变化,线性拟合的效果就不是很好。 - 可能需要一个会产生
阶跃且连续的函数来进行拟合
2.sigmod函数
g ( z ) = 1 1 + e − z = e z 1 + e z g(z)=\frac{1}{1+e^{-z}}=\frac{e^{z}}{1+e^{z}} g(z)=1+e−z1=1+ezez

- 自变量 z z z的范围是 ( − ∞ , + ∞ ) (-\infty,+\infty) (−∞,+∞),值域的范围 g g g是 ( 0 , 1 ) (0,1) (0,1)
- 一个很自然的想法就是,以某一个函数 z z z作为 g g g的输入,再将 g g g对应的输出作为
概率输出,通过设定阈值,将结果进行分类(二分类,(0-1))。 - 那么关于数据 x \mathbf{x} x(或 X \mathbf{X} X),先构造什么样的 z z z呢?答案是任意,只要是能够符合数据的就是合理的。所以 z z z的选取不是固定的!
例1

-
这个分类自然想到
线性模型-
令 z = θ 0 + θ 1 ∗ x 1 + θ 2 ∗ x 2 z=\theta_0+\theta_1*x_1 + \theta_2 * x_2 z=θ0+θ1∗x1+θ2∗x2
-
当 z = 0 z=0 z=0时,即 θ 0 + θ 1 ∗ x 1 + θ 2 ∗ x 2 = 0 \theta_0+\theta_1*x_1 + \theta_2 * x_2=0 θ0+θ1∗x1+θ2∗x2=0时,恰好对应一条直线

-
对于要分类的点,均在直线两侧,那么将他们的坐标带入 z z z中的结果是 z > 0 z>0 z>0或 z < 0 z<0 z<0(二者区其一)。
-
问题是 s i g m o d 函 数 sigmod函数 sigmod函数如何对其起作用呢?答案是通过将点带入 z z z中,对于此时 z z z的输出( > 0 >0 >0或 < 0 <0 <0)进行设定阈值。根据 s i g m o d 函 数 sigmod函数 sigmod函数的特性,自然可以想到将 0.5 0.5 0.5作为阈值。
- 当 x x x在 z z z的作用下输出结果 r e s u l t > 0 result>0 result>0, r e s u l t result result再在 s i g m o d 函 数 sigmod函数 sigmod函数作用下,输出结果 > 0.5 >0.5 >0.5,此时判定为类别1
- 当 x x x在 z z z的作用下输出结果 r e s u l t < 0 result<0 result<0, r e s u l t result result再在 s i g m o d 函 数 sigmod函数 sigmod函数作用下,输出结果 < 0.5 <0.5 <0.5,此时判定为类别0
-
-
-
大致的设计思路:
- z = θ 0 + θ 1 ∗ x 1 + θ 2 ∗ x 2 z=\theta_0+\theta_1*x_1 + \theta_2 * x_2 z=θ0+θ1∗x1+θ2∗x2
- g ( z ) = 1 1 + e − z g(z)=\frac{1}{1+e^{-z}} g(z)=1+e−z1
- 通过 g g g的输出和设定的阈值进行比较,得出分类结果。
- 上述未知的量时参数 Θ \Theta Θ,这个才怎么求呢?下面再说。
例2

- 这个自然想到一个分类边界是圆(
分非线性模型) 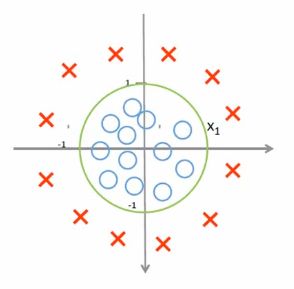
- 令 z = θ 0 + θ 1 ∗ x 1 + θ 2 ∗ x 2 + θ 3 ∗ x 1 2 + θ 4 ∗ x 4 2 z=\theta_0 + \theta_1*x_1 +\theta_2*x_2 + \theta_3 * x_1^{2} + \theta_4 * x_4^{2} z=θ0+θ1∗x1+θ2∗x2+θ3∗x12+θ4∗x42。(这里不需要 x 1 ∗ x 2 x_1*x_2 x1∗x2的交叉项)
- 令 z = 0 z=0 z=0,此时正是圆的边界。对于要分类的点带入 z z z中,输出结果 > 0 >0 >0或 < 0 <0 <0(二者取其一)
- 以后的分析和上述例1相同。( s i g m o d 函 数 sigmod函数 sigmod函数的作用,阈值的选取等,均一致)
- 令 z = θ 0 + θ 1 ∗ x 1 + θ 2 ∗ x 2 + θ 3 ∗ x 1 2 + θ 4 ∗ x 4 2 z=\theta_0 + \theta_1*x_1 +\theta_2*x_2 + \theta_3 * x_1^{2} + \theta_4 * x_4^{2} z=θ0+θ1∗x1+θ2∗x2+θ3∗x12+θ4∗x42。(这里不需要 x 1 ∗ x 2 x_1*x_2 x1∗x2的交叉项)
- 大致的设计思路:
- z = θ 0 + θ 1 ∗ x 1 + θ 2 ∗ x 2 + θ 3 ∗ x 1 2 + θ 4 ∗ x 4 2 z=\theta_0 + \theta_1*x_1 +\theta_2*x_2 + \theta_3 * x_1^{2} + \theta_4 * x_4^{2} z=θ0+θ1∗x1+θ2∗x2+θ3∗x12+θ4∗x42
- g ( z ) = 1 1 + e − z g(z)=\frac{1}{1+e^{-z}} g(z)=1+e−z1
- 通过 g g g的输出和设定的阈值进行比较,得出分类结果。
- 上述未知的量时参数 Θ \Theta Θ,这个才怎么求呢?下面再说。
对比发现
- 对于上述例1和例2的比较,逻辑回归的整体设计思路大致相同。要解决的两个问题是:
- 如何确定一开始的 z z z?,从结果上看,线性模型和非线性模型均可。并没有定法,这个 z z z的选取得结合具体的 X X X分布进行选择。
- 注: X X X的分布在高维的时候判定本身就是一个难题,所以 z z z的确定也不是一件容易的事情。
- 假定已经确定了 z z z的函数表达(但其中的参数 Θ \Theta Θ未知),该如何求参数 Θ \Theta Θ?
- 求参数的方法,基本上会针对目标函数(损失含糊)采用迭代法(解析解太困难了,有时候甚至不可行)
- ==问题又变成了:针对$sigmod函数 $找一个什么样的目标函数(损失函数)?==这就是下面要说的事了!
- 如何确定一开始的 z z z?,从结果上看,线性模型和非线性模型均可。并没有定法,这个 z z z的选取得结合具体的 X X X分布进行选择。
逻辑回归是如何做到分类的?
- 针对逻辑回归,其中的 s i g m o d 函 数 sigmod函数 sigmod函数和对应的损失函数的确定,是该方法的精髓。
1.模型
假定已知 函 数 z θ ( x ) 函数z_{\theta}(x) 函数zθ(x),那么将其作为 g i d m o d 函 数 gidmod函数 gidmod函数的输入, g ( z ) g(z) g(z)。那么有一个假设空间 h θ ( x ) h_{\theta}(x) hθ(x)。
已 知 z θ ( x ) ; g ( z ) = 1 1 + e − z 已知z_{\theta}(x);g(z)=\frac{1}{1+e^{-z}} 已知zθ(x);g(z)=1+e−z1
h θ ( x ) = g ( z θ ( x ) ) = 1 1 + e z θ ( x ) h_{\theta}(x)=g(z_{\theta}(x))=\frac{1}{1+e^{z_{\theta}(x)}} hθ(x)=g(zθ(x))=1+ezθ(x)1
其中: h θ ( x ) ∈ ( 0 , 1 ) h_{\theta}(x) \in (0,1) hθ(x)∈(0,1)。这个是设计损失函数的关键。
2.策略
损失函数
-
对于一个样本损失
c o s t ( h θ ( x ) , y ) = { − l o g ( h θ ( x ) ) , y = 1 − l o g ( 1 − h θ ( x ) ) , y = 0 cost(h_{\theta(x)},y)=\begin{cases}-log(h_{\theta}(x)),y=1\\-log(1-h_{\theta}(x)),y=0\end{cases} cost(hθ(x),y)={−log(hθ(x)),y=1−log(1−hθ(x)),y=0- 解释:
- 在已知分类信息 y = 1 y=1 y=1时,希望 h θ ( x ) h_{\theta}(x) hθ(x)的值越接近1最好,这样损失才更小。假设,在 y = 1 y=1 y=1时,但是分类错了,即 h θ ( x ) h_{\theta}(x) hθ(x)的值相对来说可能更接近于0(从右侧趋近于0),此时 − l o g ( h θ ( x ) ) -log(h_{\theta}(x)) −log(hθ(x))的值会变大,意味着损失增大,而目标就是来最小化这个损失。所有此时针对一个样本在 y = 1 y=1 y=1时设计的损失函数是合理的。
- 在已知分类信息 y = 0 y=0 y=0时,希望 h θ ( x ) h_{\theta}(x) hθ(x)的值越接近0最好,这样损失 − l o g ( 1 − h θ ( x ) ) -log(1-h_{\theta}(x)) −log(1−hθ(x))才更小。假设,在 y = 0 y=0 y=0时,但是分类错了,即 h θ ( x ) h_{\theta}(x) hθ(x)的值相对来说可能更接近于1(从左侧趋近1),此时 − l o g ( 1 − h θ ( x ) ) -log(1-h_{\theta}(x)) −log(1−hθ(x))的值会变大,意味着损失增大,而目标就是来最小化这个损失。所有此时针对一个样本在 y = 0 y=0 y=0时设计的损失函数是合理的。
- 但是上述的算是有一个问题,那就它是分段函数,不利于优化,所以有了下面的合并。
- 解释:
-
技巧上的合并(背后有最大熵理论模型,对数最大似然估计)
c o s t ( h θ ( x ( i ) , y ( i ) ) = − ( y ( i ) ∗ l o g ( h θ ( x ( i ) ) + ( 1 − j ( i ) ) ∗ l o g ( 1 − h θ x ( i ) ) cost(h_{\theta}(x^{(i)},y^{(i)})=-(y^{(i)}*log(h_{\theta}^{(x^{(i)})}+(1-j^{(i)})*log(1-h_{\theta}^{x^{(i)}}) cost(hθ(x(i),y(i))=−(y(i)∗log(hθ(x(i))+(1−j(i))∗log(1−hθx(i)) -
损失函数:
-
经验风险
J ( θ ) = − 1 m ∑ i = 1 m ( y ( i ) ∗ l o g ( h θ ( x ( i ) ) + ( 1 − j ( i ) ) ∗ l o g ( 1 − h θ x ( i ) ) J(\theta)=-\frac{1}{m} \sum_{i=1}^{m}(y^{(i)}*log(h_{\theta}^{(x^{(i)})}+(1-j^{(i)})*log(1-h_{\theta}^{x^{(i)}}) J(θ)=−m1i=1∑m(y(i)∗log(hθ(x(i))+(1−j(i))∗log(1−hθx(i)) -
结构风险
J ( θ ) = − 1 m ∑ i = 1 m ( y ( i ) ∗ l o g ( h θ ( x ( i ) ) + ( 1 − j ( i ) ) ∗ l o g ( 1 − h θ x ( i ) ) + λ ∑ j = 0 n θ j 2 J(\theta)=-\frac{1}{m} \sum_{i=1}^{m}(y^{(i)}*log(h_{\theta}^{(x^{(i)})}+(1-j^{(i)})*log(1-h_{\theta}^{x^{(i)}}) + \lambda \sum_{j=0}^{n}{\theta_{j}^{2}} J(θ)=−m1i=1∑m(y(i)∗log(hθ(x(i))+(1−j(i))∗log(1−hθx(i))+λj=0∑nθj2
-
3.算法
对于 g ( z ) = 1 1 + e − z g(z) =\frac{1}{1+e^{-z}} g(z)=1+e−z1的求导,
d ( g ( z ) ) d z = − ( 1 + e − z ) − 2 ∗ e − z ∗ ( − 1 ) = 1 1 + e − z ∗ e − z 1 + e − z = 1 1 + e − z ∗ ( 1 − 1 1 + e − z ) = g ( z ) ∗ ( 1 − g ( z ) ) \frac{d(g(z))}{dz}=-(1+e^{-z})^{-2}*e^{-z}*(-1)\\=\frac{1}{1+e^{-z}}*\frac{e^{-z}}{1+e^{-z}}\\=\frac{1}{1+e^{-z}}*(1-\frac{1}{1+e^{-z}})\\=g(z)*(1-g(z)) dzd(g(z))=−(1+e−z)−2∗e−z∗(−1)=1+e−z1∗1+e−ze−z=1+e−z1∗(1−1+e−z1)=g(z)∗(1−g(z))
所以
∂ g ∂ θ j = ∂ g ∂ z ∂ z ∂ θ j = g ( z ) ∗ ( 1 − g ( z ) ) ∗ ∂ z ∂ θ j \frac{\partial g}{\partial \theta_j}=\frac{\partial g}{\partial z}\frac{\partial z}{\partial \theta_j}\\=g(z)*(1-g(z))*\frac{\partial z}{\partial \theta_j} ∂θj∂g=∂z∂g∂θj∂z=g(z)∗(1−g(z))∗∂θj∂z
特别地,当 z θ ( x ( i ) = θ T x ( i ) z_\theta(x^{(i)}=\theta^{T}x^{(i)} zθ(x(i)=θTx(i),得到 ∂ z θ j = x j ( i ) \frac{\partial z}{\theta_j}=x_j^{(i)} θj∂z=xj(i)。
此时,
∂ g ∂ θ j = g ( z ) ∗ ( 1 − g ( z ) ) ∗ ∂ z ∂ θ j = g ( z ) ∗ ( 1 − g ( z ) ) ∗ x j ( i ) \frac{\partial g}{\partial \theta_j}=g(z)*(1-g(z))*\frac{\partial z}{\partial \theta_j}=g(z)*(1-g(z))*x_{j}^{(i)} ∂θj∂g=g(z)∗(1−g(z))∗∂θj∂z=g(z)∗(1−g(z))∗xj(i)
采用梯度下降算法求解参数 Θ \Theta Θ
θ j : = θ j − α ∂ ∂ θ j J ( θ ) , ( j = 0 ⋯ n ) \theta_j := \theta_j - \alpha\frac{\partial}{\partial \theta_j}J(\theta),(j=0 \cdots n) θj:=θj−α∂θj∂J(θ),(j=0⋯n)
∂ ∂ θ j J ( θ ) = ∂ ∂ θ j ( − 1 m ∑ i = 1 m ( y ( i ) ∗ l o g ( h θ ( x ( i ) ) + ( 1 − j ( i ) ) ∗ l o g ( 1 − h θ x ( i ) ) ) ⋯ ⋯ = − 1 m ∑ i = 1 m ( y ( i ) − g ( θ T x ( i ) ) ) ∗ x j ( i ) \frac{\partial}{\partial \theta_j} J(\theta)=\frac{\partial}{\partial \theta_j}(-\frac{1}{m} \sum_{i=1}^{m}(y^{(i)}*log(h_{\theta}^{(x^{(i)})}+(1-j^{(i)})*log(1-h_{\theta}^{x^{(i)}}))\\\cdots\\\cdots\\=-\frac{1}{m}\sum_{i=1}^{m}(y^{(i)}-g(\theta^{T}x^{(i)}))*x_{j}^{(i)} ∂θj∂J(θ)=∂θj∂(−m1i=1∑m(y(i)∗log(hθ(x(i))+(1−j(i))∗log(1−hθx(i)))⋯⋯=−m1i=1∑m(y(i)−g(θTx(i)))∗xj(i)
说明:
-
上述的计算并没有什么难度,有难度的地方主要有两点:
-
关于逻辑回归中的 s i g m o d 函 数 sigmod函数 sigmod函数的使用和一个样本的损失函数的设计和最终的损失函数的设计(对数最大似然)。
-
采用标量进行求导或者求偏导,问题着实不大。转化成用矢量计算,会比标量下计算要难一点。
-
总结:
- 逻辑回归可以将
连续值通过 s i g m o d 函 数 + 阈 值 限 定 sigmod函数+阈值限定 sigmod函数+阈值限定转为离散值问题(二分类问题) - s i g m o d 函 数 sigmod函数 sigmod函数的使用
- 对数最大似然函数
- 矢量下求导
参见:
统计学习方法
机器学习实战
https://blog.csdn.net/qq_38923076/article/details/82925183