编译原理实验四:语法分析程序
(一)学习经典的语法分析器(1学时)
实验目的
学习已有编译器的经典语法分析源程序。
实验任务
阅读已有编译器的经典语法分析源程序,并测试语法分析器的输出。
实验内容
(1)选择一个编译器,如:TINY,其它编译器也可(需自备源代码)。
(2)阅读语法分析源程序,加上你自己的理解。尤其要求对相关函数与重要变量的作用与功能进行稍微详细的描述。若能加上学习心得则更好。TINY语言请参考《编译原理及实践》第3.7节。对TINY语言要特别注意抽象语法树的定义与应用。
(3)测试语法分析器。对TINY语言要求输出测试程序的字符形式的抽象语法树。(手工或编程)画出图形形式的抽象语法树。
TINY语言:
测试用例一:sample.tny。
(二)实现一门语言的语法分析器(3学时)
实验目的
通过本次实验,加深对语法分析的理解,学会编制语法分析器。
实验任务
用C或C++语言编写一门语言的语法分析器。
实验内容
(1)语言确定:C-语言,其定义在《编译原理及实践》附录A中。也可选择其它语言,不过要有该语言的详细定义(可仿照C-语言)。一旦选定,不能更改,因为要在以后继续实现编译器的其它部分。鼓励自己定义一门语言。也可选择TINY语言,但需要使用与TINY现有语法分析代码不同的分析算法实现,并在实验报告中写清原理。
(2)完成C-语言的BNF文法到EBNF文法的转换。通过这一转换,消除左递归,提取左公因子,将文法改写为LL(1)文法,以适用于自顶向下的语法分析。规划需要将哪些非终结符写成递归下降函数。
(3)为每一个将要写成递归下降函数的非终结符,如:变量声明、函数声明、语句序列、语句、表达式等,定义其抽象语法子树的形式结构,然后定义C-语言的语法树的数据结构。
(4)仿照前面学习的语法分析器,编写选定语言的语法分析器。可以自行选择使用递归下降、LL(0)、LR(0)、SLR、LR(1)中的任意一种方法实现。
(5)准备2~3个测试用例,测试并解释程序的运行结果。
实验通过测试后,按规定时间上交源代码、测试样例、输出文件(如有输出文件)和电子版实验报告。
环境问题说明
这份代码可能需要使用C++11标准编译,如果你用的是Dev C++,可以参照以下办法支持C++11标准:
https://www.cnblogs.com/decade-dnbc66/p/5351939.html
程序流程说明(C-的语法树构建图)
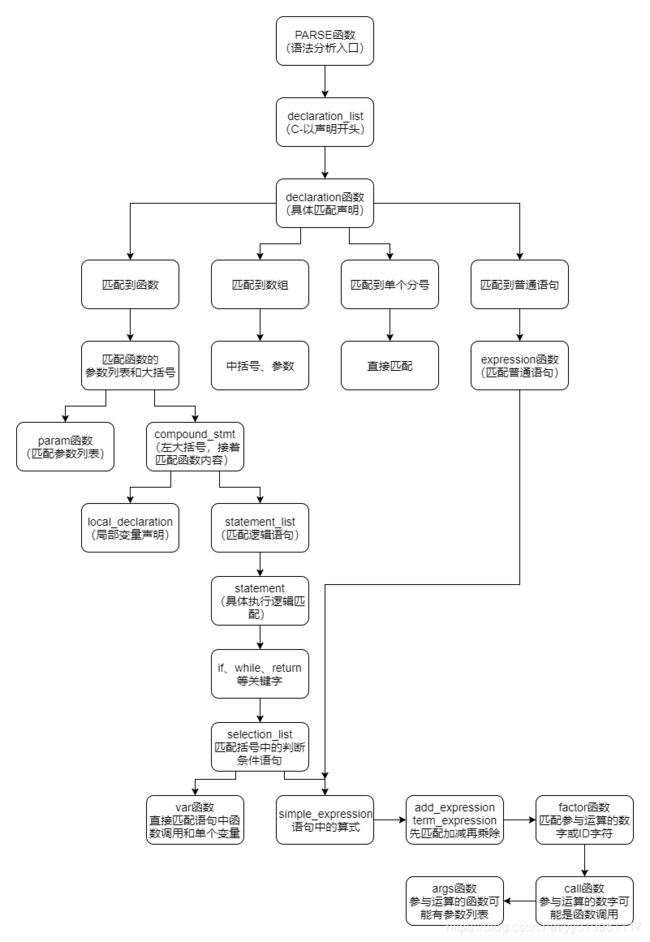
代码实现(自顶向下方法)
#include
#include
#include
#include
using namespace std;
#define BUFLEN 256
#define MAXLEN 256
#define MAXTOKENLEN 40
#define MAXCHILDREN 4
static int lineno;
static int linepos = 0;//读取的字符在lineBuf的位置
static int EOF_FLAG = false;
static int bufsize = 0;//lineBuf的长度
static char lineBuf[BUFLEN];
FILE * source;
char tokenString[MAXTOKENLEN + 1];
string output;//输出文件
int flag=0;
enum TokenType
{
ENDFILE, ERROR,
IF, ELSE, INT, RETURN, VOID, WHILE,
ID, NUM,
ASSIGN, EQ, LT, PLUS, MINUS, TIMES, OVER, LPAREN, RPAREN, SEMI, LBRACKET, RBRACKET, LBRACE, RBRACE, COMMA,
GT, GEQ, NEQ, LEQ
};
enum StateType
{
START, INASSIGN, INCOMMENT, INNUM, INID, DONE, PRECOMMENT, AFTERCOMMENT
};
struct
{
char* str;
TokenType tok;
}ReserverWords[6]
= { { "if",IF },{ "else",ELSE },{ "int",INT },{ "return",RETURN },{ "void",VOID },{ "while",WHILE } };
void UnGetNextChar()
{
if (!EOF_FLAG)
linepos--;
}
int GetNextChar()
{
if (!(linepos') || (c == '=') || (c == '!'))
{
state = INASSIGN;
assign += char(c);
}
else if ((c == ' ') || (c == '\t') || (c == '\n'))
save = false;
else if (c == '/')
{
save = false;
state = PRECOMMENT;
}
else
{
state = DONE;
switch (c)
{
case EOF:
save = false;
CurrentToken = ENDFILE;
break;
case '+':
CurrentToken = PLUS;
break;
case '-':
CurrentToken = MINUS;
break;
case '*':
CurrentToken = TIMES;
break;
case '(':
CurrentToken = LPAREN;
break;
case ')':
CurrentToken = RPAREN;
break;
case ';':
CurrentToken = SEMI;
break;
case '[':
CurrentToken = LBRACKET;
break;
case ']':
CurrentToken = RBRACKET;
break;
case '{':
CurrentToken = LBRACE;
break;
case '}':
CurrentToken = RBRACE;
break;
case ',':
CurrentToken = COMMA;
break;
default:
CurrentToken = ERROR;
break;
}
}
break;
case INCOMMENT:
save = false;
if (c == EOF)
{
state = DONE;
CurrentToken = ENDFILE;
}
else if (c == '*')
state = AFTERCOMMENT;
else
{
state = INCOMMENT;
}
break;
case INASSIGN:
if (c == '=')
{
CurrentToken = EQ;
state = DONE;
}
else if (assign == "!")
{
UnGetNextChar();
save = false;
CurrentToken = ERROR;
state = DONE;
}
else if (assign == "=")
{
UnGetNextChar();
save = false;
CurrentToken = ASSIGN;
state = DONE;
}
else if (assign == "<")
{
UnGetNextChar();
save = false;
CurrentToken = LT;
state = DONE;
}
else
{
UnGetNextChar();
save = false;
CurrentToken = GT;
state = DONE;
}
break;
case INNUM:
if (!isdigit(c))
{
UnGetNextChar();
save = false;
state = DONE;
CurrentToken = NUM;
}
break;
case INID:
if (!isalpha(c))
{
UnGetNextChar();
save = false;
state = DONE;
CurrentToken = ID;
}
break;
case PRECOMMENT:
if (c == '*')
{
state = INCOMMENT;
save = false;
}
else
{
UnGetNextChar();
CurrentToken = OVER;
state = DONE;
}
break;
case AFTERCOMMENT:
save = false;
if (c == '/')
{
state = START;
}
else if (c == '*')
{
state = AFTERCOMMENT;
}
else
{
state = INCOMMENT;
}
break;
case DONE:
default:
state = DONE;
CurrentToken = ERROR;
break;
}
if ((save) && (tokenStringIndex <= MAXTOKENLEN))
{
tokenString[tokenStringIndex++] = (char)c;
}
if (state == DONE)
{
tokenString[tokenStringIndex] = '\0';
if (CurrentToken == ID)
{
CurrentToken = ReservedLookUp(tokenString);
}
}
}
return CurrentToken;
}
enum NodeKind//节点类型
{
FuncK, IntK, IdK, ParamsK, ParamK, CompK, ConstK, CallK, ArgsK, VoidK, Var_DeclK, Arry_DeclK, Arry_ElemK, AssignK/*,WhileK*/, OpK,
Selection_StmtK, Iteration_StmtK, Return_StmtK
};
struct//节点类型和字符串关系
{
string str;
NodeKind nk;
}nodekind[18]
= { { "Funck",FuncK },{ "IntK",IntK },{ "IdK",IdK },{ "ParamsK",ParamsK },{ "ParamK",ParamK },{ "CompK",CompK },{ "ConstK",ConstK },{ "CallK",CallK },
{ "ArgsK",ArgsK },{ "VoidK",VoidK },{ "Var_DeclK",Var_DeclK },{ "Arry_DeclK",Arry_DeclK },{ "Arry_ElemK",Arry_ElemK },{ "AssignK",AssignK },
/*{"WhileK",WhileK},*/{ "OpK",OpK },{ "Selection_StmtK",Selection_StmtK },{ "Iteration_StmtK",Iteration_StmtK },{ "Return_StmtK",Return_StmtK } };
struct//符号与字符串关系
{
string str;
TokenType tk;
}Ope[11]
= { { "=",ASSIGN },{ "==",EQ },{ "<",LT },{ "+",PLUS },{ "-",MINUS },{ "*",TIMES },{ "/",OVER },
{ ">",GT },{ ">=",GEQ },{ "!=",NEQ },{ "<=",LEQ } };
string OpeLookUp(TokenType tk)//操作符转换为字符串
{
int i;
for (i = 0; i<11; i++)
{
if (tk == Ope[i].tk)
{
return Ope[i].str;
}
}
}
string Change(NodeKind nk)//节点类型转换为字符串
{
int i;
for (i = 0; i<19; i++)
{
if (nk == nodekind[i].nk)
{
return nodekind[i].str;
break;
}
}
}
TokenType token;
struct TreeNode
{
struct TreeNode * child[4];
struct TreeNode * sibling;
int lineno;
NodeKind nodekind;
union { TokenType op; int val; const char * name; } attr;
};
TreeNode * declaration_list(void);
TreeNode * declaration(void);
TreeNode * params(void);
TreeNode * param_list(TreeNode *p);
TreeNode * param(TreeNode *p);
TreeNode * compound_stmt(void);
TreeNode * local_declaration(void);
TreeNode * statement_list(void);
TreeNode * statement(void);
TreeNode * expression_stmt(void);
TreeNode * selection_stmt(void);
TreeNode * iteration_stmt(void);
TreeNode * return_stmt(void);
TreeNode * expression(void);
TreeNode * var(void);
TreeNode * simple_expression(TreeNode * p);
TreeNode * additive_expression(TreeNode * p);
TreeNode * term(TreeNode * p);
TreeNode * factor(TreeNode * p);
TreeNode * call(TreeNode * p);
TreeNode * args(void);
char * copyString(char *s)
{
int n;
char * t;
if (s == NULL)
{
return NULL;
}
n = strlen(s) + 1;
t = (char*)malloc(n);
if (t == NULL) {
}
else
{
strcpy(t, s);
}
return t;
}
void match(TokenType expected)
{
if (token == expected)
token = GetToken();
else
{
if(flag==0)
flag=1;
else
cout << "unexpected token" << endl;
}
}
TreeNode * newNode(NodeKind kind)
{
TreeNode * t = (TreeNode *)malloc(sizeof(TreeNode));
int i;
if (t == NULL)
{
;
}
else {
for (i = 0; i<4; i++)
{
t->child[i] = NULL;
}
t->sibling = NULL;
t->nodekind = kind;
t->lineno = lineno;
if (kind == OpK || kind == IntK || kind == IdK)
{
if (kind == IdK)
t->attr.name = "";
}
if (kind == ConstK)
t->attr.val = 0;
}
return t;
}
TreeNode * declaration_list(void) //declaration_list->declaration_list declaration | declaration
{
TreeNode * t = declaration(); //入口一定是声明,即所有的语句都是以声明开始的,那么这里就要判断是哪种声明
TreeNode * p = t;
while ((token != INT) && (token != VOID) && (token != ENDFILE))
{
token = GetToken();
if (token == ENDFILE)
break;
}
while (token == INT || token == VOID) //待上一次递归下降返回后,处理下一条语句或下一个函数
{
TreeNode * q;
q = declaration();
if (q != NULL)
{
if (t == NULL)
{
t = p = q;
}
else
{
p->sibling = q;
p = q;
}
}
}
match(ENDFILE); //递归结束
return t;
}
TreeNode * declaration(void)
{
TreeNode * t = NULL;
TreeNode * p = NULL;
TreeNode * q = NULL;
TreeNode * s = NULL;
TreeNode * a = NULL;
if (token == INT)
{
p = newNode(IntK);
match(INT);
}
else//(token==VOID)
{
p = newNode(VoidK);
match(VOID);
} //C-的关键字直接声明只有int和void两种
if (p != NULL&&token == ID) //当然,除了直接声明以外,还可能对于变量赋值这样的声明,因此给一个结点,因为声明也可能以变量名开头(变量声明过)
{
q = newNode(IdK);
q->attr.name = copyString(tokenString); //声明的结点需要给名字
match(ID);
if (token==LPAREN) //如果下一个是左括号,那么就是一个函数,包含参数列表
{
t = newNode(FuncK); //那么创建一个函数名称的结点,之前的函数声明和函数名称都是其子结点
t->child[0] = p;
t->child[1] = q;
match(LPAREN);
t->child[2] = params(); //其子结点需要有参数列表
match(RPAREN);
t->child[3] = compound_stmt(); //子结点还需要有大括号,此时进入匹配大括号的模式
}
else if (token == LBRACKET) //如果ID后面接着一个左中括号,那么就匹配到声明数组情况
{
t = newNode(Var_DeclK);
a = newNode(Arry_DeclK); //创建数组结点
t->child[0] = p; //数组的名称是它的子结点
t->child[1] = a;
match(LBRACKET);
s = newNode(ConstK);
s->attr.val = atoi(tokenString); //结点的名称是它的字符串的值
match(NUM);
a->child[0] = q;
a->child[1] = s;
match(RBRACKET);
match(SEMI);
}
else if (token == SEMI)
{
t = newNode(Var_DeclK);
t->child[0] = p;
t->child[1] = q;
match(SEMI);
}
else
{
;
}
}
else
{
;
}
return t;
}
TreeNode * params(void) //params_list | void
{
TreeNode * t = newNode(ParamsK); //创建一个参数列表结点
TreeNode * p = NULL;
if (token == VOID) //如果函数括号里面参数列表是VOID,那么匹配到VOID
{
p = newNode(VoidK);
match(VOID);
if (token == RPAREN)
{
if (t != NULL)
t->child[0] = p;
}
else //如果不为空,那么参数列表为(void id,[……])
{
t->child[0] = param_list(p);
}
}
else //括号里面的(token==INT)
{
t->child[0] = param_list(p);
}
return t;
}
TreeNode * param_list(TreeNode * k) //params_list->params_list,param | param
{
TreeNode * t = param(k);
TreeNode * p = t;
k = NULL; //没有要传给param的VoidK,所以将k设为NULL
while (token == COMMA) //参数之间需要以逗号连接,那么需要当前字符需要匹配逗号
{
TreeNode * q = NULL;
match(COMMA);
q = param(k); //匹配完逗号之后需要匹配(类型和参数)
if (q != NULL)
{
if (t==NULL)
{
t=p=q;
}
else
{
p->sibling = q;
p = q;
}
}
}
return t;
}
TreeNode * param(TreeNode * k) //para m →type - specifier ID | type - specifier ID[]
{
TreeNode * t = newNode(ParamK); //创建一个参数结点
TreeNode * p = NULL;
TreeNode * q = NULL;
if (k == NULL&&token == VOID) //参数可能以VOID开头
{
p = newNode(VoidK);
match(VOID);
}
else if (k == NULL&&token == INT) //参数可以int开头,因为int是唯一的数据类型
{
p = newNode(IntK); //新创建一个int结点,匹配int
match(INT);
}
else if (k != NULL)
{
p = k;
}
if (p != NULL) //下面匹配参数,如果参数是ID,那么新建ID结点,作为数据类型结点的子结点
{
t->child[0] = p;
if (token == ID)
{
q = newNode(IdK);
q->attr.name = copyString(tokenString);
t->child[1] = q;
match(ID);
}
if (token == LBRACKET && (t->child[1] != NULL)) //如果参数匹配到了左中括号,那么参数形为:int name[],此时,接连匹配左右中括号即可
{
match(LBRACKET);
t->child[2] = newNode(IdK);
match(RBRACKET);
}
else
{
return t;
}
}
else
{
;
}
return t;
}
TreeNode * compound_stmt(void)
{
TreeNode * t = newNode(CompK); //创建一个大括号结点
match(LBRACE);
t->child[0] = local_declaration(); //读取局部变量声明
t->child[1] = statement_list(); //接下来的地方是各种语句的声明,递归下降到下一层
match(RBRACE); //直到函数结束的时候,匹配一个右大括号
return t;
}
TreeNode * local_declaration(void)
{
TreeNode * t = NULL;
TreeNode * q = NULL;
TreeNode * p = NULL;
while (token == INT || token == VOID)
{
p = newNode(Var_DeclK);
if (token == INT)
{
TreeNode * q1 = newNode(IntK);
p->child[0] = q1;
match(INT);
}
else if (token == VOID)
{
TreeNode * q1 = newNode(VoidK);
p->child[0] = q1;
match(INT);
}
if ((p != NULL) && (token == ID))
{
TreeNode * q2 = newNode(IdK);
q2->attr.name = copyString(tokenString);
p->child[1] = q2;
match(ID);
if (token == LBRACKET)
{
TreeNode * q3 = newNode(Var_DeclK);
p->child[3] = q3;
match(LBRACKET);
match(RBRACKET);
match(SEMI);
}
else if (token == SEMI)
{
match(SEMI);
}
else
{
match(SEMI);
}
}
if (p != NULL)
{
if (t == NULL)
t = q = p;
else
{
q->sibling = p;
q = p;
}
}
}
return t;
}
TreeNode * statement_list(void) //函数中的表达式语句
{
TreeNode * t = statement(); //首先确定这是一个什么语句,递归下降
TreeNode * p = t;
while (IF == token || LBRACKET == token || ID == token || WHILE == token || RETURN == token || SEMI == token || LPAREN == token || NUM == token) //待上一次递归完成之后,进行下一次递归
{
TreeNode * q;
q = statement();
if (q != NULL)
{
if (t == NULL)
{
t = p = q;
}
else
{
p->sibling = q;
p = q;
}
}
}
return t;
}
TreeNode * statement(void)
{
TreeNode * t = NULL;
switch (token)
{
case IF:
t = selection_stmt(); //为每一种语句创建一棵语法树,这里是判断语句
break;
case WHILE:
t = iteration_stmt(); //循环语句
break;
case RETURN:
t = return_stmt(); //返回语句
break;
case LBRACE:
t = compound_stmt(); //匹配到了又一个大括号,那么再重复一遍
break;
case ID: case SEMI: case LPAREN: case NUM:
t = expression_stmt(); //如果匹配到了ID、分号、左括号、数字,一律以语句处理
break;
default:
token = GetToken();
break;
}
return t;
}
TreeNode * selection_stmt(void)
{
TreeNode * t = newNode(Selection_StmtK);
match(IF); //if( 开头
match(LPAREN);
if (t != NULL)
{
t->child[0] = expression(); //其子结点是一个语句,代表判断条件
}
match(RPAREN);
t->child[1] = statement(); //条件判断语句结束以反括号结尾,也需要同样考虑ELSE的情况
if (token == ELSE)
{
match(ELSE);
if (t != NULL)
{
t->child[2] = statement();
}
}
return t;
}
TreeNode * iteration_stmt(void)
{
TreeNode * t = newNode(Iteration_StmtK);
match(WHILE);
match(LPAREN); //创建一个循环WHILE结点,匹配到左括号,条件判断语句,右括号
if (t != NULL)
{
t->child[0] = expression();
}
match(RPAREN);
if (t != NULL)
{
t->child[1] = statement();
}
return t;
}
TreeNode * return_stmt(void)
{
TreeNode * t = newNode(Return_StmtK);
match(RETURN); //匹配到return和一个语句,代表返回的东西,最后有一个分号
if (token == SEMI)
{
match(SEMI);
return t;
}
else
{
if (t != NULL)
{
t->child[0] = expression();
}
}
match(SEMI);
return t;
}
TreeNode * expression_stmt(void) //匹配一些标识符
{
TreeNode * t = NULL;
if (token == SEMI)
{
match(SEMI);
return t;
}
else
{
t = expression();
match(SEMI);
}
return t;
}
TreeNode * expression(void)
{
TreeNode * t = var();
if (t == NULL) //不是以ID开头,只能是simple_expression情况
{
t = simple_expression(t);
}
else //以ID开头,可能是赋值语句,或simple_expression中的var和call类型的情况
{
TreeNode * p = NULL;
if (token == ASSIGN)//赋值语句
{
p = newNode(AssignK);
match(ASSIGN);
p->child[0] = t;
p->child[1] = expression();
return p;
}
else //simple_expression中的var和call类型的情况
{
t = simple_expression(t);
}
}
return t;
}
TreeNode * var(void)
{
TreeNode * t = NULL;
TreeNode * p = NULL;
TreeNode * q = NULL;
if (token == ID)
{
p = newNode(IdK);
p->attr.name = copyString(tokenString);
match(ID);
if (token == LBRACKET)
{
match(LBRACKET);
q = expression();
match(RBRACKET);
t = newNode(Arry_ElemK);
t->child[0] = p;
t->child[1] = q;
}
else
{
t = p;
}
}
return t;
}
TreeNode * simple_expression(TreeNode * k)
{
TreeNode * t = additive_expression(k); //先匹配加减法运算,因为先计算乘除再加减,而方法为自顶向下,因此加减法先被匹配,乘除法后匹配先计算
k = NULL;
if (EQ == token || GT == token || GEQ == token || LT == token || LEQ == token || NEQ == token) //匹配一些简单表达式,比如等于、大于、小于这些
{
TreeNode * q = newNode(OpK);
q->attr.op = token;
q->child[0] = t;
t = q;
match(token); //匹配两个运算式子,作为符号的子结点
t->child[1] = additive_expression(k); //匹配乘除法
return t;
}
return t;
}
TreeNode * additive_expression(TreeNode * k)
{
TreeNode * t = term(k);
k = NULL;
while ((token == PLUS) || (token == MINUS)) //匹配乘除法,并将两边的参与运算的数字作为符号的子结点
{
TreeNode * q = newNode(OpK);
q->attr.op = token;
q->child[0] = t;
match(token);
q->child[1] = term(k);
t = q;
}
return t;
}
TreeNode * term(TreeNode * k) //最后,匹配数字或参数
{
TreeNode * t = factor(k);
k = NULL;
while ((token == TIMES) || (token == OVER)) //乘除法
{
TreeNode * q = newNode(OpK);
q->attr.op = token;
q->child[0] = t;
t = q;
match(token);
q->child[1] = factor(k); //匹配数字的值或变量
}
return t;
}
TreeNode * factor(TreeNode * k)
{
TreeNode * t = NULL;
if (k != NULL) //k为上面传下来的已经解析出来的以ID开头的var,可能为call或var
{
if (token == LPAREN && k->nodekind != Arry_ElemK) //call
{
t = call(k); //如果表达式里面出现了括号,那么肯定是函数的调用
}
else
{
t = k;
}
}
else //没有从上面传下来的var
{
switch (token)
{
case LPAREN:
match(LPAREN);
t = expression();
match(RPAREN);
break;
case ID:
k = var();
if (LPAREN == token && k->nodekind != Arry_ElemK)
{
t = call(k);
}
else //如果是连续计算,进入这一步
{
t = k;
}
break;
case NUM:
t = newNode(ConstK);
if ((t != NULL) && (token == NUM))
{
t->attr.val = atoi(tokenString);
}
match(NUM);
break;
default:
token = GetToken();
break;
}
}
return t;
}
TreeNode * call(TreeNode * k)
{
TreeNode * t = newNode(CallK); //创建一个call函数的结点,匹配左右括号和参数
if (k != NULL)
t->child[0] = k;
match(LPAREN);
if (token == RPAREN)
{
match(RPAREN);
return t;
}
else if (k != NULL)
{
t->child[1] = args(); //如果存在参数,还需要匹配参数
match(RPAREN);
}
return t;
}
TreeNode * args(void)
{
TreeNode * t = newNode(ArgsK);
TreeNode * s = NULL;
TreeNode * p = NULL;
if (token != RPAREN)
{
s = expression();
p = s;
while (token == COMMA)
{
TreeNode * q;
match(COMMA);
q = expression();
if (q != NULL)
{
if (s == NULL)
{
s = p = q;
}
else
{
p->sibling = q;
p = q;
}
}
}
}
if (s != NULL)
{
t->child[0] = s;
}
return t;
}
int blank_number = 0;
void PreOrder(TreeNode* t)
{
string blank = " ";
int i;
for (i = 0; inodekind == OpK)
{
cout << blank << "Op: " << OpeLookUp(t->attr.op) << endl;
output += blank + "Op: " + OpeLookUp(t->attr.op) + "\n";
}
else if (t->nodekind == IdK)
{
cout << blank << Change(t->nodekind) << ": " << t->attr.name << endl;
output += blank + Change(t->nodekind) + ": " + t->attr.name + "\n";
}
else if (t->nodekind == ConstK)
{
cout << blank << Change(t->nodekind) << ": " << t->attr.val << endl;
int n = t->attr.val;
strstream ss;
string s;
ss << n;
ss >> s;
output += blank + Change(t->nodekind) + ": " + s + "\n";
}
else if (t->nodekind == AssignK)
{
cout << blank << "Assign" << endl;
output += blank + "Assign" + "\n";
}
else if (t->nodekind == Selection_StmtK)
{
cout << blank << "If" << endl;
output += blank + "If" + "\n";
}
else if (t->nodekind == Iteration_StmtK)
{
cout << blank << "While" << endl;
output += blank + "While" + "\n";
}
else if (t->nodekind == Return_StmtK)
{
cout << blank << "Return" << endl;
output += blank + "Return" + "\n";
}
else
{
cout << blank << Change(t->nodekind) << endl;
output += blank + Change(t->nodekind) + "\n";
}
}
for (i = 0; ichild[i] != NULL)
{
blank_number += 2;
PreOrder(t->child[i]);
blank_number -= 2;
}
}
if (t->sibling != NULL)
{
PreOrder(t->sibling);
}
}
void parse(void)
{
TreeNode *t; //t是一个根结点
cout<<"Syntax tree:"<