一文让你彻底搞懂最小二乘法(超详细推导)
要解决的问题
在工程应用中,我们经常会用一组观测数据去估计模型的参数,模型是我们根据先验知识定下的。比如我们有一组观测数据 ( x i , y i ) (x_i,y_i) (xi,yi)(一维),通过一些数据分析我们猜测 y y y和 x x x之间存在线性关系,那么我们的模型就可以定为: f ( x ) = k x + b f(x)=kx+b f(x)=kx+b
这个模型只有两个参数,所以理论上,我们只需要观测两组数据建立两个方程,即可解出两个未知数。类似的,假如模型有 n n n个参数,我们只需要观测 n n n组数据就可求出参数,换句话说,在这种情况下,模型的参数是唯一确定解。
但是在实际应用中,由于我们的观测会存在误差(偶然误差、系统误差等),所以我们总会做多余观测。比如在上述例子中,尽管只有两个参数,但是我们可能会观测 n n n组数据 ( x 1 , y 1 ) . . , ( x n , y n ) (x_1, y_1)..,(x_n, y_n) (x1,y1)..,(xn,yn),这会导致我们无法找到一条直线经过所有的点,也就是说,方程无确定解。
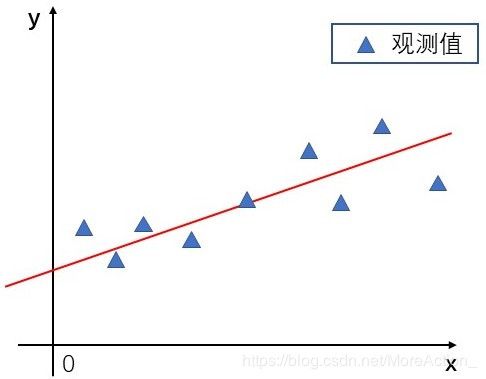
于是这就是我们要解决的问题:虽然没有确定解,但是我们能不能求出近似解,使得模型能在各个观测点上达到“最佳“拟合。那么“最佳”的准则是什么?可以是所有观测点到直线的距离和最小,也可以是所有观测点到直线的误差(真实值-理论值)绝对值和最小,也可以是其它,如果是你面临这个问题你会怎么做?
早在19世纪,勒让德就认为让“误差的平方和最小”估计出来的模型是最接近真实情形的。
为什么就是误差平方而不是其它的,这个问题连欧拉、拉普拉斯都未能成功回答,后来是高斯建立了一套误差分析理论,从而证明了确实是使误差平方和最小的情况下系统是最优的。理论的证明也并不难,如果你了解了会有更深刻的认识,限于篇幅我会写在另外一篇博客。
按照勒让德的最佳原则,于是就是求:
L = ∑ 1 n ( y i − f ( x ) ) 2 L=\sum_{1}^{n}\left(y_i-f(x)\right)^{2} L=1∑n(yi−f(x))2
这个目标函数取得最小值时的函数参数,这就是最小二乘法的思想,所谓“二乘”就是平方的意思。从这里我们可以看到,最小二乘法其实就是用来做函数拟合的一种思想。
至于怎么求出具体的参数那就是另外一个问题了,理论上可以用导数法、几何法,工程上可以用梯度下降法。下面以最常用的线性回归为例进行推导和理解。
线性回归
线性回归因为比较简单,可以直接推导出解析解,而且许多非线性的问题也可以转化为线性问题来解决,所以得到了广泛的应用。甚至许多人认为最小二乘法指的就是线性回归,其实并不是,最小二乘法就是一种思想,它可以拟合任意函数,线性回归只是其中一个比较简单而且也很常用的函数,所以讲最小二乘法基本都会以它为例。
下面我会先用矩阵法进行推导,然后再用几何法来帮助你理解最小二乘法的几何意义。
矩阵解法
线性回归定义为: h θ ( x 1 , x 2 , … x n − 1 ) = θ 0 + θ 1 x 1 + … + θ n x n − 1 h_{\theta}\left(x_{1}, x_{2}, \ldots x_{n-1}\right)=\theta_{0}+\theta_{1} x_{1}+\ldots+\theta_{n} x_{n-1} hθ(x1,x2,…xn−1)=θ0+θ1x1+…+θnxn−1( θ \theta θ为参数)假设现在有 m m m个样本,每个样本有 n − 1 n-1 n−1维特征,将所有样本点代入模型中得:
h 1 = θ 0 + θ 1 x 1 , 1 + θ 2 x 1 , 2 + … + θ n − 1 x 1 , n − 1 h 2 = θ 0 + θ 1 x 2 , 1 + θ 2 x 2 , 2 + … + θ n − 1 x 2 , n − 1 ⋮ h m = θ 0 + θ 1 x m , 1 + θ 2 x m , 2 + … + θ n − 1 x m , n − 1 \begin{array}{l} h_{1}=\theta_{0}+\theta_{1} x_{1,1}+\theta_{2} x_{1,2}+\ldots+\theta_{n-1} x_{1,n-1} \\ h_{2}=\theta_{0}+\theta_{1} x_{2,1}+\theta_{2} x_{2,2}+\ldots+\theta_{n-1} x_{2,n-1}\\ \vdots \\ h_{m}=\theta_{0}+\theta_{1} x_{m, 1}+\theta_{2} x_{m, 2}+\ldots+\theta_{n-1} x_{m, n-1} \end{array} h1=θ0+θ1x1,1+θ2x1,2+…+θn−1x1,n−1h2=θ0+θ1x2,1+θ2x2,2+…+θn−1x2,n−1⋮hm=θ0+θ1xm,1+θ2xm,2+…+θn−1xm,n−1为方便用矩阵表示,我们令 x 0 = 1 x_0=1 x0=1,于是上述方程可以用矩阵表示为:
h = X θ \mathbf{h}=\mathbf{X} \theta h=Xθ其中, h \mathbf{h} h为mx1的向量, 代表模型的理论值, θ \theta θ 为nx1的向量, X X X为mxn维的矩阵, m m m代表样本的个数, n n n代表样本的特征数,于是目标损失函数用矩阵表示为:
J ( θ ) = ∥ h − Y ∥ 2 = ∥ X θ − Y ∥ 2 = ( X θ − Y ) T ( X θ − Y ) J(\theta)=\|\mathbf{h}-\mathbf{Y}\|^2 =\|\mathbf{X}\theta-\mathbf{Y}\|^2= (\mathbf{X} \theta-\mathbf{Y})^{T}(\mathbf{X} \theta-\mathbf{Y}) J(θ)=∥h−Y∥2=∥Xθ−Y∥2=(Xθ−Y)T(Xθ−Y)其中 Y \mathbf{Y} Y是样本的输出向量, 维度为mx1。
根据高数知识我们知道函数取得极值就是导数为0的地方,所以我们只需要对损失函数求导令其等于0就可以解出 θ \theta θ。矩阵求导属于矩阵微积分的内容,我也是现学的(…,这里先介绍两个用到的公式:
∂ x T a ∂ x = ∂ a T x ∂ x = a \frac{\partial x^{T} a}{\partial x}=\frac{\partial a^{T} x}{\partial x}=a ∂x∂xTa=∂x∂aTx=a ∂ x T A x ∂ x = A x + A T x \frac{\partial x^{T} A x}{\partial x}=A x+A^{T} x ∂x∂xTAx=Ax+ATx如果矩阵A是对称的: A x + A T x = 2 A x A x+A^{T} x=2 A x Ax+ATx=2Ax对目标函数化简:
J ( θ ) = θ T X T X θ − θ T X T Y − Y T X θ + Y T Y J(\theta)=\theta^{T} X^{T} X \theta-\theta^{T} X^{T}Y-Y^{T} X\theta+Y^{T} Y J(θ)=θTXTXθ−θTXTY−YTXθ+YTY求导令其等于0: ∂ ∂ θ J ( θ ) = 2 X T X θ − 2 X T Y = 0 \frac{\partial}{\partial \theta} J(\theta)=2X^{T} X \theta-2X^TY=0 ∂θ∂J(θ)=2XTXθ−2XTY=0解得 θ = ( X T X ) − 1 X T Y \theta=\left(X^{T}X\right)^{-1} X^{T}Y θ=(XTX)−1XTY,经过推导我们得到了 θ \theta θ的解析解,现在只要给了数据,我们就可以带入解析解中直接算出 θ \theta θ。
几何意义
几何意义会直观的帮助你理解最小二乘法究竟在干什么。首先先来解释一下矩阵乘法的几何意义,对于一个方程组 A x Ax Ax,我们可以看做是 x x x对矩阵 A A A的列向量的线性组合,比如:
{ 1 × x 1 + x 2 = 3 − 1 × x 1 + x 2 = 1 ⇔ [ 1 1 − 1 1 ] [ x 1 x 2 ] = [ 3 1 ] ⇔ A × x = b \left\{\begin{array}{l} 1 \times x_{1}+x_{2}=3 \\ -1 \times x_{1}+x_{2}=1 \end{array} \Leftrightarrow\left[\begin{array}{ll} 1 & 1 \\ -1 & 1 \end{array}\right]\left[\begin{array}{l} x_{1} \\ x_{2} \end{array}\right]=\left[\begin{array}{l} 3 \\ 1 \end{array}\right] \Leftrightarrow A \times x=b\right. {1×x1+x2=3−1×x1+x2=1⇔[1−111][x1x2]=[31]⇔A×x=b
可以看作:
[ 1 − 1 ] × x 1 + [ 1 1 ] × x 2 = [ 3 1 ] ⇔ a 1 × x 1 + a 2 × x 2 = b \left[\begin{array}{c} 1 \\ -1 \end{array}\right] \times x_{1}+\left[\begin{array}{c} 1 \\ 1 \end{array}\right] \times x_{2}=\left[\begin{array}{l} 3 \\ 1 \end{array}\right] \Leftrightarrow a_{1} \times x_{1}+a_{2} \times x_{2}=b [1−1]×x1+[11]×x2=[31]⇔a1×x1+a2×x2=b
画在坐标轴上可以看到,向量 b \mathbf{b} b其实就是向量 a 1 \mathbf{a_1} a1与 a 2 \mathbf{a_2} a2的线性组合,因为他们都是在一个平面上,显然是有解的。

但是如文章开头所说,由于存在观测误差,我们往往会做多余观测,比如要拟合一次方程 y = k x + b y=k x+b y=kx+b,我们可能观测了三个点(0,2),(1,2),(2,3),写成矩阵形式如下(为表述方便,用x1代替k,x2代替b ):
{ 1 × x 1 + x 2 = 2 0 × x 1 + x 2 = 2 2 × x 1 + x 2 = 3 ⇔ [ 1 1 0 1 2 1 ] [ x 1 x 2 ] = [ 2 2 3 ] ⇔ A × x = b \left\{\begin{array}{l} 1 \times x_{1}+x_{2}=2 \\ 0 \times x_{1}+x_{2}=2 \\ 2 \times x_{1}+x_{2}=3 \end{array} \Leftrightarrow\left[\begin{array}{ll} 1 & 1 \\ 0 & 1 \\ 2 & 1 \end{array}\right]\left[\begin{array}{l} x_{1} \\ x_{2} \end{array}\right]=\left[\begin{array}{l} 2 \\ 2 \\ 3 \end{array}\right] \Leftrightarrow A \times x=b\right. ⎩⎨⎧1×x1+x2=20×x1+x2=22×x1+x2=3⇔⎣⎡102111⎦⎤[x1x2]=⎣⎡223⎦⎤⇔A×x=b
表示成线性组合的方式:
[ 1 0 2 ] × x 1 + [ 1 1 1 ] × x 2 = [ 2 2 3 ] ⇔ a 1 × x 1 + a 2 × x 2 = b \left[\begin{array}{l} 1 \\ 0 \\ 2 \end{array}\right] \times x_{1}+\left[\begin{array}{l} 1 \\ 1 \\ 1 \end{array}\right] \times x_{2}=\left[\begin{array}{l} 2 \\ 2 \\ 3 \end{array}\right] \Leftrightarrow a_{1} \times x_{1}+a_{2} \times x_{2}=b ⎣⎡102⎦⎤×x1+⎣⎡111⎦⎤×x2=⎣⎡223⎦⎤⇔a1×x1+a2×x2=b
画在图中如下:
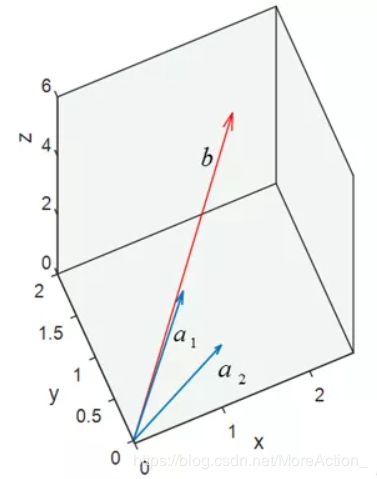
从图中我们可以看到,无论 a 1 \mathbf{a_1} a1 和 a 2 \mathbf{a_2} a2 怎么线性组合都不可能得到 b \mathbf{b} b,因为 a 1 \mathbf{a_1} a1 和 a 2 \mathbf{a_2} a2 的线性组合成的向量只能落在它们组成的子空间 S \mathbf{S} S 中。
退而求其次,虽然我们不可能得到 b \mathbf{b} b,但在 S \mathbf{S} S上找一个和 b \mathbf{b} b最接近的总可以吧。那么将 b \mathbf{b} b投影 在平面 S \mathbf{S} S上得到的向量 p \mathbf{p} p就是和 b \mathbf{b} b最接近的向量(把向量看作点,最接近的意思就是点到平面某点取得距离最短,自然就是投影所成的交点)。
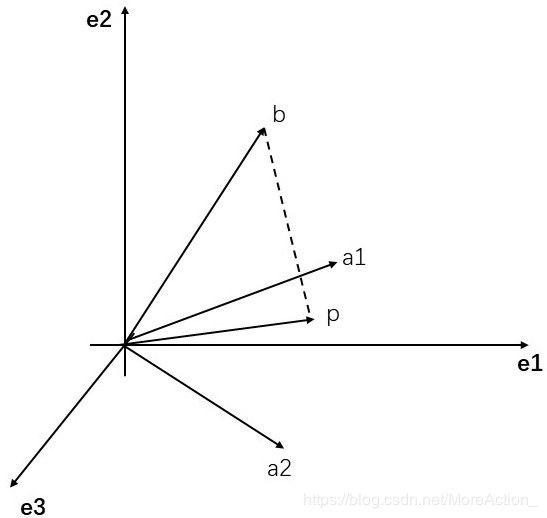
换句话说,方程组 A x = b Ax=b Ax=b虽然无解,也就是b不在A的列空间中,但是我们可以在 A A A的列空间中找到一个和 b b b最接近的向量 p p p, p p p就是 b b b在 A A A的列空间中的投影,通过求 A x = p Ax=p Ax=p的解,就是原方程的最小二乘解。
由几何意义可知垂线 e = b − p = b − A x e=b-p=b-Ax e=b−p=b−Ax正交于平面 S \mathbf{S} S,也就是 a 1 T e = 0 , a 2 T e = 0 a_{1}^{T} e=0, a_{2}^{T} e=0 a1Te=0,a2Te=0,写成矩阵形式:
A T e = A T ( b − A x ) = A T b − A T A x = 0 \begin{array}{c} A^{T} e=A^{T}(b-Ax)=A^{T} b-A^{T} Ax=0 \end{array} ATe=AT(b−Ax)=ATb−ATAx=0解得 x = ( A T A ) − 1 A T b x=\left(A^{T} A\right)^{-1} A^{T} b x=(ATA)−1ATb,可以看到推导结果和矩阵法一样。从上面可以看到,最小二乘法的几何意义就是求解 b b b 在 A A A的列向量空间中的投影。
到这里最小二乘法的推导已经完成了,但是我们忽略了一个问题,就是假如 A T A A^TA ATA不可逆怎么办?这个问题我会另写一篇博客进行介绍。
以上就是全部内容。
Reference
https://www.cnblogs.com/pinard/p/5976811.html
https://zhuanlan.zhihu.com/p/38128785
https://www.zhihu.com/question/304164814/answer/549972357
如果对你有帮助,请点个赞让我知道:-D