树链剖分详解【后期会不断更新】
知识准备
1.DFS;
2.线段树。
相信DFS大家都会,估计只有线段树了。
如果有不会的请点这里:线段树系列文章(未完)
何谓树链剖分?
就是将一棵树分成许多条链,使得树中所有节点都被包含在这些链里。
(换句话说:就是一种使你的代码瞬间增加1KB的算法。)
#怎么剖分?
1.随便剖分
随便找一个节点,将它作为链头向下剖分。
2.随机剖分
随便剖分+一点特判。
3.轻重链剖分
将重边(后面会讲)连成链。
哪种方法好?
显然,对于随机数据,三种方法没什么区别。
但是对于第一、二种方法,若使用刻意构造的数据去测试,则会被卡掉。
综上所述,为了保险起见,也为了算法稳定性,我们选择轻重链剖分。
轻重链剖分
Step1:乱七糟八的定义
-
重儿子:对于每个节点的儿子,若该儿子所在的子树的大小是所有儿子中最大的,则称该儿子为重儿子。每个节点有且只有一个重儿子。
-
轻儿子:除了重儿子的节点。
-
重边:连接重儿子与其父亲节点的边。
-
轻边:连接轻儿子与其父亲节点的边。
-
重链:由重边连接而成的链。注意链内有且只有重边。
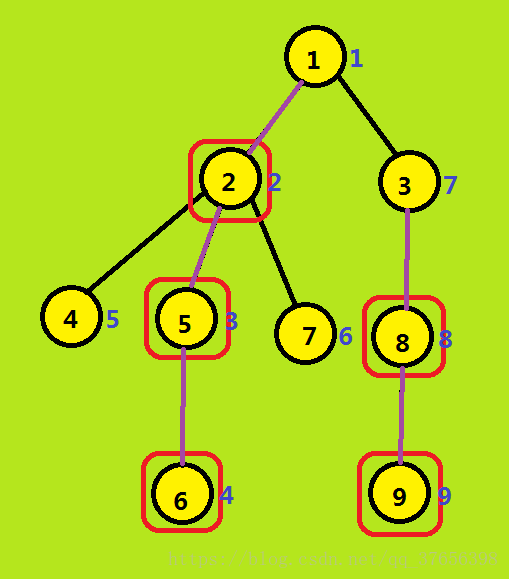
相信你也看不懂(hhh),举个例子吧:

如图,在这棵树中:红框框着的点就是重儿子,紫色边表示重边,黑色边表示轻边。可以看出两条重链:{1,2,5,6}和{3,8,9}。而且,我们发现,重链的起点都是轻儿子。
Step2:重标号?
然后,我们可以对所有节点进行重编号(优先重儿子),就会得到如下的结果:(蓝色点即为新标号)
我们发现:重链中,标号都是连续的。于是,我们可以想象一下:将所有重链按链首标号进行排序,并拉直平放起来;我们就得到了一个线性的序列。
并且:我们可以发现一些性质:
性质一:对于两个节点u,v,若v是u的轻儿子,则有:siz[v]<=siz[u]/2,若v是u的重儿子,则:siz[v]>siz[u]/2;
性质二:对于一个任意节点u,它到根节点的路径最多有 log 2 N \log_2 N log2N条轻边, log 2 N \log_2N log2N条重路径。
Step3:数据结构:线段树
接下来就很玄学了
由上一步可知,我们得到了一个序列,于是,我们就可以把这一堆东西扔给线段树了。
我们可以进行权值修改、路径查询等操作,而做到这一切,都只需要 O ( N log 2 N ) O(N\log_2N) O(Nlog2N)的时间复杂度。
实现
Step1:混乱的数组
先扔来一堆数组名字:
val[1...N]:记录每个节点的权值(读入时);siz[1...N]:记录以该节点为根的子树的大小;top[1...N]:记录每个节点所在重链的链首;son[1...N]:记录每个节点的重儿子;dep[1...N]:记录该节点在树中的深度;tid[1...N]:记录每个节点的新标号;rnk[1...N]:记录新标号所对应的节点,是tid的反函数;fa[1...N]:记录每个节点的父亲节点。
晕了对吧?别慌,其实都非常有用的,理解了就非常容易。
Step2:第一次DFS
这次DFS我们主要处理一些基础信息,即:siz、son、dep和fa四个数组。
这种事情应该不会很困难吧?直接粘代码了。
void DFS1(int u,int f,int d) {
dep[u]=d,fa[u]=f,siz[u]=1;
for(Tnode *p=G[u];p!=NULL;p=p->nxt) {
int v=p->v;
if(v==f)continue;
val[v]=p->w;
DFS1(v,u,d+1);
siz[u]+=siz[v];
if(son[u]==-1||siz[v]>siz[son[u]])
son[u]=v;
}
}
顺便粘上一份我使用的邻接表:
struct Tnode {
int v,w;
Tnode *nxt;
}e[2*Maxn+5];
Tnode *G[Maxn+5],*ecnt=&e[0];
void AddEdge(int u,int v,int w) {
Tnode *p=++ecnt;
p->v=v,p->w=w;
p->nxt=G[u],G[u]=p;
p=++ecnt;
p->v=u,p->w=w;
p->nxt=G[v],G[v]=p;
}
Step3:第二次DFS
这次DFS主要处理剩下的信息:top、tid和rnk三个数组。
我们在DFS传入一个参数tp,表示当前所在重链的链首,若遇到轻儿子则将tp设为该节点并继续往下传。
在处理tid,rnk时,我们开一个全局变量dcnt,每次进DFS时加一,就可以处理出这些信息了。代码如下:
void DFS2(int u,int tp) {
top[u]=tp,tid[u]=++dcnt,rnk[dcnt]=u;
if(son[u]==-1)
return;
DFS2(son[u],tp);
for(Tnode *p=G[u];p!=NULL;p=p->nxt) {
int v=p->v;
if(v==son[u]||v==fa[u])
continue;
DFS2(v,v);
}
}
做完这些后,我们就完成了整个树链剖分的实现。
剩下的就是各种数据结构的事情了。
例题选讲
例题1:SPOJ QTREE Query on a Tree