一、汇编语言基础
汇编语言有两种,AT&T汇编和Intel汇编,而linux采用的是AT&T汇编,因为不同的CPU寄存器大小不一样,相应的汇编指令也会有所区别,以mov指令为例,movb指8位,movw中的w是指16位,movl中的l是指32位,movq中的q是指64位。为了更好的理解汇编语言,在这一部分还穿插了不同种类的寻址,寄存器寻址,立即寻址,直接寻址,间接寻址等
二、计算机基础
从体系结构开始,因为要学习的是Linux操作系统分析,首先要对计算机体系结构有个整体的把握,老师从冯诺依曼体系结构开始,讲述了存储计算机工作原理,对计算机的内存,总线和硬盘做了一些基本的介绍。
三、深入理解系统调用
系统调用是一种特殊的中断,和函数的传参不同,因为系统调用是从用户态到内核态,所以采用寄存器传递参数,当然由于压栈的方式需要读写内存,函数调用速度较慢,64位结构下普通的函数调用和系统调用都是通过寄存器传递参数,系统调用一般通过int $0x80的方式进行,系统调用的初始化就是将系统调用处理入口地址告诉CPU,系统调用的执行就是压栈关键寄存器,保存现场,恢复现场,最后返回。
系统调⽤的意义是操作系统为⽤户态进程与硬件设备进⾏交互提供了组接⼝。系统调⽤具有以下功能和特性。
•
• 把⽤户从底层的硬件编程中解放出来。操作系统为我们管理硬件,⽤户态进
程不⽤直接与硬件设备打交道。
•
• 极⼤地提⾼系统的安全性。如果⽤户态进程直接与硬件设备打交道,会产⽣
安全隐患,可能引起系统崩溃。
•
• 使⽤户程序具有可移植性。⽤户程序与具体的硬件已经解耦合并⽤接⼝代替
了,不会有紧密的关系,便于在不同系统间移植。
四、进程的创建
进程的创建过程⼤致是⽗进程通过_do_fork fork系统调⽤进⼊内核_do_fork 总结 函数,如下图所示复制进程描述符及相关进程
资源(采⽤写时复制技术)、分配⼦进程的内核堆栈并对内核堆栈和thread等进程关键上下⽂进⾏初始化,最后将⼦进程
放⼊就绪队列,fork系统调⽤返回;⽽⼦进程则在被调度执⾏时根据设置的内核堆栈和thread等进程关键上下⽂开始执⾏。
五、linux系统的一般执行过程
(1)正在运⾏的⽤户态进程X。
(2)发⽣中断(包括异常、系统调⽤等),CPU完成load cs:rip(entry of a specifific ISR),即跳转到中断处理程序⼊⼝。
(3)中断上下⽂切换,具体包括如下⼏点:
• swapgs指令保存现场,可以理解CPU通过swapgs指令给当前CPU寄存器状态做了⼀个快照。
• rsp point to kernel stack,加载当前进程内核堆栈栈顶地址到RSP寄存器。快速系统调⽤是由系统调⽤⼊⼝处的汇编代码实现⽤户堆栈和内核堆栈的切换。
• save cs:rip/ss:rsp/rflflags:将当前CPU关键上下⽂压⼊进程X的内核堆栈,快速系统调⽤是由系统调⽤⼊⼝处的汇编代码实现的。
•此时完成了中断上下⽂切换,即从进程X的⽤户态到进程X的内核态。
(4)中断处理过程中或中断返回前调⽤了schedule函数,其中完成了进程调度算法选择next进程、进程地址空间切换、以及switch_to关键的进程上下⽂切换等。
(5)switch_to调⽤了__switch_to_asm汇编代码做了关键的进程上下⽂切换。将当前进程X的内核堆栈切换到进程调度算法选出来的next进程(本例假定为进程Y)的内核堆栈,并完成了进程上下⽂所需的指令指针寄存器状态切换。之后开始运⾏进程Y(这⾥进程Y曾经通过以上步骤被切换出去,因此可以从switch_to下⼀⾏代码继续执⾏)。
(6)中断上下⽂恢复,与(3)中断上下⽂切换相对应。注意这⾥是进程Y的中断处理过程中,⽽(3)中断上下⽂切换是在进程X的中断处理过程中,因为内核堆栈进程X切换到进程Y了。
(7)为了对应起⻅中断上下⽂恢复的最后⼀步单独拿出来(6的最后⼀步即是7)iret-pop cs:rip/ss:rsp/rflflags,从Y进程的内核堆栈中弹出(3)中对应的压栈内容。此时完成了中断上下⽂的切换,即从进程Y的内核态返回到进程Y的⽤户态。注意快速系统调⽤返回sysret与iret的处理略有不同。
(8)继续运⾏⽤户态进程Y。
六、文件系统
在LINUX系统中有一个重要的概念:一切都是文件。把一切资源都看作是文件,包括硬件设备。把每个硬件都看成是一个文件,通常称为设备文件,这样用户就可以用读写文件的方式实现对硬件的访问。VFS层有两个接口:一个是与用户的接口;一个是与特定文件系统的接口。VFS与用户的接口将所有对文件的操作定向到相应的特定文件系统函数上。VFS与特定文件系统的接口主要是通过vfs-operations来实现的。
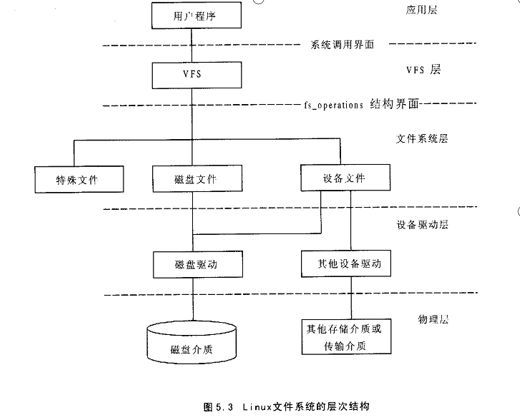
通过open()打开文件流程:
- 读文件之前要先通过open函数打开文件,open会创建一个系统打开文件表;
- 进程调用库函数向内核发起读文件请求;
- 内核通过检查进程的文件描述符定位到虚拟文件系统的已打开文件列表表项;
- 调用该文件可用的系统调用函数read()。read()函数通过文件表项链接到目录项模块,根据传入的文件路径,在目录项模块中检索,找到该文件的inode;
- 在inode中,通过文件内容偏移量计算出要读取的页;
- 通过inode找到文件对应的address_space;
- 在address_space中访问该文件的页缓存树,查找对应的页缓存结点:
- 如果页缓存命中,那么直接返回文件内容;
- 如果页缓存缺失,那么产生一个页缺失异常,创建一个页缓存页,同时通过inode找到文件该页的磁盘地址,读取相应的页填充该缓存页;重新进行第6步查找页缓存;
- 文件内容读取成功。
七、总结
通过这门操作系统的学习,对Linux的理解更加深入了,Linux由于其开源性,是的其不断发展和壮大。使得我对系统调用的过程,中断处理的过程,进程切换,进程调度,文件系统,以及Linux的一般执行流程理解更加深入,对Linux产生了浓厚的兴趣,也会使用Linux去解决一些项目中的问题,今后会不断探究Linux,学习Linux,使用Linux去解决问题。