一:进程
1.1进程描述符结构:
在Linux内核中⽤⼀个数据结构struct task_struct来描述进程,struct task_struct的数据结构⾮常庞⼤,其中state是进程状态,stack是堆栈等,此外还有进程的状态信息、进程双向链表的管理,以及控制台tty、⽂件系统fs的描述、进程打开⽂件的⽂件描述符files、 内存管理的描述mm,还有进程间通信的信号signal的描述等。

值得注意的是task_struct数据结构的最后是保存进程上下⽂中CPU相关的⼀些状态信息的关键数据结构thread,这在进行进程切换时是非常重要的数据结构。其中最关键的是sp和ip。
1.2进程的状态:
进程有就绪 态、运⾏态、阻塞态这3种基本状态,其中阻塞态又分为TASK_INTERRUPTIBLE 和TASK_UNINTERRUPTIBLE两种状态。
TASK_INTERRUPTIBLE 和TASK_UNINTERRUPTIBLE 的区别:
TASK_INTERRUPTIBLE是可以被信号和wake_up()唤醒的,当信号到来时,进程会被设置为可运行。
而TASK_UNINTERRUPTIBLE只能被wake_up()唤醒。
1.3进程链表:
⽤于管理进程数据结构的双向链表struct list_head task把所有的进程⽤双向链表链起来,⽽且还会头尾相连把所有的 进程⽤双向循环链表链起来
进程的⽗⼦兄弟关系:

可见,进程的子进程和兄弟进程相关信息均用双向链表链接起来(struct list_head)
1.4Linux内核中进程的初始化
在start_kernel中含有对linux内核0号进程的初始化过程
1)init_task为第⼀个进程(0号进程)的进程描述符结构体变量,它的初始化是通过硬编码⽅式固定下来的。除此之外,所有其他进程的初始化都是通过do_fork复制⽗进程的⽅式初始化的
2)1号和2号进程的创建是start_kernel初始化到最后由rest_ init通过 kernel_thread(通过_do_fork创建)创建了两个内核线程:⼀个是kernel_init,最终把⽤户态的进程init给启动起来,它是所有⽤户进程的祖先;另⼀个是kthreadd内核线程,kthreadd内核线程是所有内核线程的祖先,负责管理所有内核线程。
1.5fork()系统调用过程:
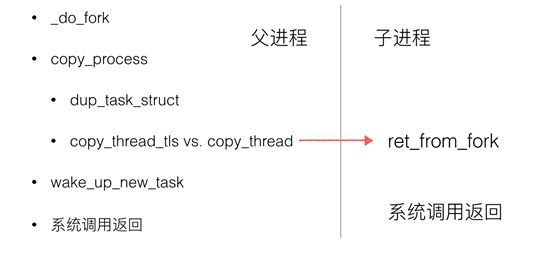
1) 父进程调用fork()系统调用,执行个int $0x80指令触发系统调用,跳转到相应系统调⽤⼊⼝的汇编代码。
2) 系统调⽤陷⼊内核态,从⽤户态堆栈转换到内核态堆栈,然后把相应的CPU关 键的现场栈顶寄存器、指令指针寄存器、标志寄存器等保存到内核堆栈,保存现场。
3) 通过系统调⽤号找到对应的中断处理程序入口地址,并传递到CS:IP,然后执⾏系统调⽤内核处理函数
4) 在fork()内核处理函数中调用_do_fork函数,_do_fork函数主要完成了调⽤copy_process()复制⽗进程、获得pid、然后再调用wake_up_new_task将⼦进程加⼊就绪队列等待调度执⾏等
5) copy_process()函数调用dup_task_struct复制当前进程(⽗进程)描述符task_struct、信息检查、初始化、把进程状态 设置为TASK_RUNNING(此时⼦进程置为就绪 态)、采⽤写时复制技术逐⼀复制所有其他进程资源,然后再调用调⽤copy_thread_tls初始化⼦进程内核栈、设置⼦进程pid等,并将内核堆栈中保存的ip指向 ret_from_fork,⼦进程从此处开始执⾏
6) 最后系统调用返回,父进程从内核态正常返回到用户态,执行下一条指令,而⼦进程则在被调度执⾏时根据设置的内核堆栈和thread等进程关键上下⽂开始执⾏(即从ret_from_form开始执行)。
1.6进程分类:
Linux内核中根据进程的优先级来区分普通进程与实时进程,Linux内核中进程优先级为0~139,数值越⾼,优先级越低,0为最⾼优先级。实时进程的优先级取值为0~99;⽽普通进程只具有nice值,nice值映射到优先级为100~139。⼦进程会继承⽗进程的优先级。
1.7进程调度策略:
实时进程:
SCHED_FIFO
1) 先进先出策略
2) 所有相同优先级的进程,最先进⼊就绪队列的进程优先调度,直到其主动放弃CPU。
SCHED_RR(Round Robin)
1)使用时间⽚来分配cpu资源
2)使得相同优先级的实时进程能够轮流获得调度,每次运⾏⼀个时间⽚。
普通进程:
SCHED_NORMAL
1) 按优先级占不同⽐例的cpu时间
2) 同⼀个进程在本身优先级不变的情况下分到的
CPU时间占⽐会根据系统负载变化⽽发⽣变化,即与时间⽚没有⼀个固定的对应关系。
1.8进程调度算法:
CFS:
1)CFS即为完全公平调度算法,其基本原理是基于权重的动态优先级调度算法。
2)每个进程使⽤CPU的顺序由进程已使⽤的CPU虚拟时间(vruntime)决定,已使⽤的虚拟时间越少,进程排序就越靠前,进程再次被调度执⾏的概率也就越⾼。
vruntime = 实际运行时间 * 1024 (nice为0的进程的权重) / 进程权重
3)每个进程每次占⽤CPU后能够执⾏的时间(ideal_runtime)由进程的权重决定,并且保证在某个时间周期内运⾏队列⾥的所有进程都能够⾄少被调度执⾏⼀次
分配给进程的运行时间 = 调度周期 * 进程权重 / 所有进程权重之和
4)Linux采⽤红⿊树(rb_tree)来存储就绪进程指针,当进程插⼊就绪队列时根据 vruntime排序,调度时只需选择最左的叶⼦节点即可
1.9进程调度的时机
总的来说,进程调度时机就是内核调⽤schedule函数的时机
1)⽤户进程上下⽂中主动调⽤特定的系统调⽤进⼊中断上下⽂,系统调⽤返回⽤户态之前, 中断处理程序主动调⽤schedule函数进⾏进程调度(检测need_resched标记)。
2)内核线程或可中断的中断处理程序,执⾏过程中发⽣中断进⼊中断上下⽂,在中断返回前, 中断处理程序主动调⽤ schedule函数进⾏进程调度。
3)内核线程主动调⽤schedule函数进⾏进程调度。
1.10进程切换
进程切换本质上是切换两个进程的内核堆栈和thread
发生进程切换时,原进程要保存一下内容,同时也是新进程要更新的内容:
1) CR3寄存器代表进程⻚⽬录表,即地址空间、数据。
2) 内核堆栈栈顶寄存器sp代表进程内核堆栈(保存函数调⽤历史),进程描述符(最后的成员thread是关键)和内核堆栈存储于连续存取区域中, 其中thread成员保存变量其中一部分CPU上下⽂,另外一部分保存在内核堆栈中。
3) 指令指针寄存器ip代表进程的CPU上下⽂
这些寄存器从⼀个进程的状态切换到另⼀个进程的状态,进程切换的关键上下⽂就算完成了。
具体在实现上,schedule()函数选择⼀个新的进程来运⾏,并调⽤context_switch进⾏上下⽂的切换。context_switch⾸先调⽤switch_mm切换CR3,然后调⽤宏switch_to来进⾏CPU上下⽂切换。
切换到next进程后,先返回到next进程上次切换让出CPU时的schedule()函数中,然后返回到调⽤schedule()的中断(系统调⽤)处理过程中。 系统调⽤是在⽤户空间通过int 0x80触发的,所以系统调用完成后通过iret将中断上下⽂返回到系统调⽤被触发的地⽅,接着继续执⾏⽤户空间的代码。这样就回到了next进程的⽤户空间代码了。
值得注意的是,进程上下文切换所需要保存的信息与中断上下文切换所需要保存的信息是不同的,中断上下文使用的是被中断进程的内核堆栈,本质上还是一个进程,但是进程上下文切换涉及到两个进程山下的,⼀般进程上下⽂切换是嵌 套到中断上下⽂切换中的。中断上下⽂中的get_current可获取⼀个指向当前进程描述符的指针,即指向被中断进程,相应的中断上下⽂切换的信息存储于该被中断进程的内核堆栈中。
中断上下⽂和进程上下⽂的⼀个关键区别是堆栈切换的⽅法。中断是由CPU实现的,所以中断上下⽂切换过程中最关键的栈顶寄存器sp和指令指针寄存器ip 是由CPU协助完成的;进程切换是由内核实现的,所以进程上下⽂切换过程中最关键的栈顶寄存器sp切换是通过进程描述符的thread.sp实现的,指令指针寄存器ip的切换是在内核堆栈切换的基础上巧妙利⽤call/ret指令实现的。
另外同样值得注意的是:在linux-3.18.6版本中ip信息是保存在struct thread_struct数据结构中而在linux-5.4.34版本中struct thread_struct数据结构中没有了ip,⽽是将ip通过内核堆栈来保存,⽐如fork创建的⼦进程内核堆栈 中会有⼀个ret_addr。
1.11Linux系统的⼀般执⾏过程
1) 正在运⾏的⽤户态进程X
2) 发⽣中断(包括异常、系统调⽤等),CPU完成load cs:rip(entry of a specific ISR),跳转到中断处理程序⼊⼝。
3) 中断上下⽂切换,首先保存现场,然后加载当前进程内核堆栈栈顶地址到RSP寄存器,最后将当前CPU关键上下⽂(包括之前保存的现场信息)压⼊进程X的内核堆栈(进程X的⽤户态—>进程X的内核态)
4) 中断处理过程中或中断返回前调⽤了schedule函数,其中完成了进程调度算法选择next进程、进程地址空间切换、以及switch_to关键的进程上下⽂切换等
5) switch_to调⽤了__switch_to_asm汇编代码做了关键的进程上下⽂切换。将当前进程X的内核堆栈切换到进程调度算法选出来的Y进程的内核堆栈,并完成了进程上下⽂所需的指令指针寄存器状态切换,之后开始运⾏进程Y.
6) 中断上下⽂恢复, 先返回到调⽤schedule()的中断(系统调⽤)处理过程,系统调用完成后通过iret将中断上下⽂返回到系统调⽤被触发的地⽅,接着继续执⾏⽤户空间的代码。
7) 继续运⾏⽤户态进程Y。
1.12地址
逻辑地址:逻辑地址⼀般时⽤段地址:段内偏移量来表示,
线性地址就是进程的地址空间⾥从 0 开始线性递增的地址空间范围⾥的地 址,是逻辑地址经过段地址转换之后的地址;
物理地址就是实际物理内存的地址,线性地址经过内存⻚转换之后就是物理地址。
EAX⽤于传递系统调⽤号 外,参数按顺序赋值给EBX、ECX、EDX、ESI、EDI、EBP,参数的个数不能超过6个
1.13系统调用过程(以time系统调用为例)
1) 应用程序调用time系统调用,触发⾏int $0x80指令执行
2) 通过EAX 寄存器传递系统调⽤号,通过EBX传递第一个参数
3) int $0x80指令保存中断发⽣时当前执⾏程序(用户态)的栈顶地址(ESP)、当时的状态字(EFlags)、当时的 CS:EIP 的值。同时会将当前进程内核态的栈顶地址、内核态的状态字放⼊ CPU 对应的寄存器,并且 CS:EIP/RIP 寄存器的值会指向中断处理程序的⼊⼝.
4) 执行中断处理程序(sys_time处理函数)
5) 中断处理程序结束后,检查need_resched标记判断是否需要调度,如果不需要,则执行iret指令从内核栈中恢复之前保存的现场
6) 返回到用户态,继续执行程序
二:中断
每个中断和异常由0-255之间的一个数来表示,INntel称为中断向量,其中非屏蔽中断的向量和异常的向量是固定的,而可屏蔽中断的向量可以通过对中断控制器的编程来改变。
2.1中断描述符表IDT
1)中断描述符表IDT是一个系统表,他与每一个中断或者异常向量相联系,每个中断或者异常向量在表中有相应的中断或者异常处理程序的入口地址,即CS和EIP,DDL(权限),每个描述符8字节,共256项,每一项称为中断描述符。内核在允许中断发生前,必须初始化IDT,内核初始化的时候,先申请一段内存,并将地址存放在idtr寄存器,CPU的idtr寄存器指向IDT表的物理基地址。可以通过Lidt指令来获得idtr寄存器内容。
2)对于中断描述符表的初始化,先汇编再C,两次初始化,汇编的初始化(start_kernel之前的初始化):表中每一项设置权限为0,中断类型设置为中断门,权限为0,cs设置为内核代码段,中断函数地址eip设置为ignore_init,即设置中断入口函数为ignore_init()(Linux中有中断门,特权级为0,陷阱门,特权级为3,系统门,特权级为0)
2.2全局描述符表GDT
GDT里面存储的是段地址的基地址,在从IDT表中找到对应的CS后,再根据CS从GDT表中找到对应中断向量的段地址的基地址,与EIP一起组成了中断程序入口的线性地址
2.3进入中断有两种可能
1)用户态进入内核态中断
2)从中断进入中断
判断方法:看权限,如果权限相等,是从中断进入中断
如果对应GDT表项中的DPL > CS寄存器中的CPL,则是用户态进入内核态中断
如果对应GDT表项中的DPL < CS寄存器中的CPL, 因为中断处理程序的特权不能低于当前进程的特权,不符合要求,会产生异常(保护异常)
2.4从用户态进入内核态时,因为栈指针指向进程的用户栈,所以要做三步:
1读取进程的内核栈指针
//读tr寄存器,访问运行进程的tss段
2将读取到的进程的内核栈指针装载CPU
3在进程的内核栈保存之前用户栈的指针ss,esp
2.5eip的值
根据异常时保存在内核堆栈中的EIP的值进一步可以分为:
故障fault:eip=引起故障的指令的地址
陷阱trap:eip=随后要执行的指令的地址
中止abort:eip=???
也就是说,如果发生的是故障,则需要先用引起故障的指令地址修改cs和eip寄存器的值,以使得这条指令在异常结束处理结束后能被再次执行
2.6发生中断时,被中断进程的内核堆栈所保存的数据
1)如果是由用户态进入到内核态,则被中断进程的内核堆栈依次(由高到低)保存ss,esp, eflags,cs,eip,硬件出错码(如果存在)
2)如果是由中断进入中断,因为之前的用户态堆栈信息已经保存在被中断进程的堆栈了,所以只需保存eflags,cs,eip,硬件出错码(如果存在)
另外,尽管内核在处理一个中断时可以接受一个新的中断,但在内核代码中还存在一些临界区,在临界区中,中断必须禁止。比如保存现场的时候。
2.7发生中断时的进程调度
发生中断嵌套的时候,会有一个中断计数器,每进入一个中断,中断计数器加1,在退出中断的时候,当中断计数器不为0的时候,不调用进程调度函数
2.8Iret指令
中断/异常处理完后,相应的处理程序会执行一条iret汇编指令,用来恢复现场
Iret汇编指令的操作是:
1)从被中断进程的内核栈中装载cs\eip和eflages寄存器,弹出错误码
2)检查是否需要从内核态转为用户态,这一点通过检查特权级来实现,若不需要iret终止执行,如需要则装载ss和esp
(一条指令恢复了5个寄存器)
课程心得
本课程使我对linux下的进程管理,中断处理,文件系统等的了解和认识进一步加深,通过阅读大量的源码,以及综合性非常强的课程实验,既锻炼了动手能力,也了解了linux实现的具体细节,收获颇丰。虽然因为疫情原因滞留在家里,不能在课堂上感受两位老师的魅力和风采,但是大家的学习热情丝毫没有因为疫情而衰减。
对于本课程的改进建议是希望ppt可以进一步完善一些,因为虽然在课堂是听懂了,但是在复习过程中按照ppt来复习有时候会有一些疑问,需要重新看视频来找到答案。
十分感谢孟宁老师和李春杰老师的精彩授课,祝老师和同学们前程似锦!