批量归一化与残差网络、凸优化、梯度下降法
批量归一化
对于浅层模型:
对输入进行标准化处理,使得各个特征的分布相近,任意一个特征在数据集中所有样本上的均值为0、标准差为1
对于深度模型:
提出批量归一化,利用小批量的均值和标准差,不断调整网络中间输出,使得网络各层的输出数值更稳定
1. 对全连接层做BatchNormalization:
x = W u + b o u t p u t = ϕ ( x ) \boldsymbol{x} = \boldsymbol{W\boldsymbol{u} + \boldsymbol{b}} \\ output =\phi(\boldsymbol{x}) x=Wu+boutput=ϕ(x)
输入u的大小是batch size 乘以 输入神经元的个数,输出x的大小是batch size 乘以 输出神经元的个数,经过激活函数之后output的size是与x相同. 而我们要做的批量归一化就是在两个式子中间,即全连接层中的仿射变换和激活函数之间。就是对x做标准化
o u t p u t = ϕ ( BN ( x ) ) output=\phi(\text{BN}(\boldsymbol{x})) output=ϕ(BN(x))
y ( i ) = BN ( x ( i ) ) \boldsymbol{y}^{(i)} = \text{BN}(\boldsymbol{x}^{(i)}) y(i)=BN(x(i))
μ B ← 1 m ∑ i = 1 m x ( i ) , \boldsymbol{\mu}_\mathcal{B} \leftarrow \frac{1}{m}\sum_{i = 1}^{m} \boldsymbol{x}^{(i)}, μB←m1i=1∑mx(i),
σ B 2 ← 1 m ∑ i = 1 m ( x ( i ) − μ B ) 2 , \boldsymbol{\sigma}_\mathcal{B}^2 \leftarrow \frac{1}{m} \sum_{i=1}^{m}(\boldsymbol{x}^{(i)} - \boldsymbol{\mu}_\mathcal{B})^2, σB2←m1i=1∑m(x(i)−μB)2,
x ^ ( i ) ← x ( i ) − μ B σ B 2 + ϵ , \hat{\boldsymbol{x}}^{(i)} \leftarrow \frac{\boldsymbol{x}^{(i)} - \boldsymbol{\mu}_\mathcal{B}}{\sqrt{\boldsymbol{\sigma}_\mathcal{B}^2 + \epsilon}}, x^(i)←σB2+ϵx(i)−μB,
首先求出对应的每个 x ( i ) x^(i) x(i)的均值 μ \mu μ,m是batch size,而方差是 σ 2 \sigma^2 σ2,最后使用标准化公式更新出 x ^ ( i ) \hat{\boldsymbol{x}}^{(i)} x^(i). 这是Z-score Normalization公式,不过这里加多了一个 ϵ \epsilon ϵ,是个很小的常数,保证分母大于0.
y ( i ) ← γ ⊙ x ^ ( i ) + β . {\boldsymbol{y}}^{(i)} \leftarrow \boldsymbol{\gamma} \odot \hat{\boldsymbol{x}}^{(i)} + \boldsymbol{\beta}. y(i)←γ⊙x^(i)+β.
我们还引入了两个新的学习参数,拉伸参数γ和偏移参数β。在训练中,这两个参数会进行学习,若 γ = σ B 2 + ϵ \boldsymbol{\gamma} = \sqrt{\boldsymbol{\sigma}_\mathcal{B}^2 + \epsilon} γ=σB2+ϵ和 β = μ B \boldsymbol{\beta} = \boldsymbol{\mu}_\mathcal{B} β=μB,批量归一化无效。
它们的作用是,如果批量归一化之后反而效果不好,可以通过学习的这两个参数进行归一化的无效化
2. 对卷积层做批量归一化
位置:卷积计算之后、应用激活函数之前。
卷积层输出的维度:样本数x通道数x卷积后的高x卷积后的宽 = mxcxpxq
如果卷积计算输出多个通道,我们需要对这些通道的输出分别做批量归一化,且每个通道都拥有独立的拉伸和偏移参数。
计算:对单通道,batchsize=m,卷积计算输出=pxq
对该通道中m×p×q个元素同时做批量归一化,使用相同的均值和方差。
3. 预测时的批量归一化
训练:以batch为单位,对每个batch计算均值和方差。
预测:用移动平均估算整个训练数据集的样本均值和方差。
因为预测的时候是没有均值和方差做参考的,只能使用移动平均法来估算
-
使用传入的移动平均:
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)
代码实现:
import time
import torch
from torch import nn, optim
import torch.nn.functional as F
import torchvision
import sys
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#用于做归一化
def batch_norm(is_training, X, gamma, beta, moving_mean, moving_var, eps, momentum):
# 判断当前模式是训练模式还是预测模式
if not is_training:
# 如果是在预测模式下,直接使用传入的移动平均所得的均值和方差
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)
else:
assert len(X.shape) in (2, 4)
if len(X.shape) == 2:
# 使用全连接层的情况,计算特征维上的均值和方差
mean = X.mean(dim=0)
var = ((X - mean) ** 2).mean(dim=0)
else:
# 使用二维卷积层的情况,计算通道维上(axis=1)的均值和方差。这里我们需要保持
# X的形状以便后面可以做广播运算
mean = X.mean(dim=0, keepdim=True).mean(dim=2, keepdim=True).mean(dim=3, keepdim=True)
var = ((X - mean) ** 2).mean(dim=0, keepdim=True).mean(dim=2, keepdim=True).mean(dim=3, keepdim=True)
# 训练模式下用当前的均值和方差做标准化
X_hat = (X - mean) / torch.sqrt(var + eps)
# 更新移动平均的均值和方差
moving_mean = momentum * moving_mean + (1.0 - momentum) * mean
moving_var = momentum * moving_var + (1.0 - momentum) * var
Y = gamma * X_hat + beta # 拉伸和偏移
return Y, moving_mean, moving_var
#做参数的初始化
class BatchNorm(nn.Module):
def __init__(self, num_features, num_dims):
super(BatchNorm, self).__init__()
if num_dims == 2:
shape = (1, num_features) #全连接层输出神经元
else:
shape = (1, num_features, 1, 1) #通道数
# 参与求梯度和迭代的拉伸和偏移参数,分别初始化成0和1
self.gamma = nn.Parameter(torch.ones(shape))
self.beta = nn.Parameter(torch.zeros(shape))
# 不参与求梯度和迭代的变量,全在内存上初始化成0
self.moving_mean = torch.zeros(shape)
self.moving_var = torch.zeros(shape)
#参数的更新,直接调用了上面的batch_norm函数一起使用
def forward(self, X):
# 如果X不在内存上,将moving_mean和moving_var复制到X所在显存上
if self.moving_mean.device != X.device:
self.moving_mean = self.moving_mean.to(X.device)
self.moving_var = self.moving_var.to(X.device)
# 保存更新过的moving_mean和moving_var, Module实例的traning属性默认为true, 调用.eval()后设成false
Y, self.moving_mean, self.moving_var = batch_norm(self.training,
X, self.gamma, self.beta, self.moving_mean,
self.moving_var, eps=1e-5, momentum=0.9)
return Y
应用到LeNet
net = nn.Sequential(
nn.Conv2d(1, 6, 5), # in_channels, out_channels, kernel_size
BatchNorm(6, num_dims=4),
nn.Sigmoid(),
nn.MaxPool2d(2, 2), # kernel_size, stride
nn.Conv2d(6, 16, 5),
BatchNorm(16, num_dims=4),
nn.Sigmoid(),
nn.MaxPool2d(2, 2),
d2l.FlattenLayer(),
nn.Linear(16*4*4, 120),
BatchNorm(120, num_dims=2),
nn.Sigmoid(),
nn.Linear(120, 84),
BatchNorm(84, num_dims=2),
nn.Sigmoid(),
nn.Linear(84, 10)
)
print(net)
Pytorch版本直接实现:
不需要自己去写函数,BatchNorm2d代表输入维度是4,BatchNorm1d代表输入维度是2
net = nn.Sequential(
nn.Conv2d(1, 6, 5), # in_channels, out_channels, kernel_size
nn.BatchNorm2d(6),
nn.Sigmoid(),
nn.MaxPool2d(2, 2), # kernel_size, stride
nn.Conv2d(6, 16, 5),
nn.BatchNorm2d(16),
nn.Sigmoid(),
nn.MaxPool2d(2, 2),
d2l.FlattenLayer(),
nn.Linear(16*4*4, 120),
nn.BatchNorm1d(120),
nn.Sigmoid(),
nn.Linear(120, 84),
nn.BatchNorm1d(84),
nn.Sigmoid(),
nn.Linear(84, 10)
)
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
d2l.train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs)
残差网络ResNet
深度学习把层数加深不是万能的,即使我们已经加入了BN方法,让数据更加稳定一点,但是层数一直加深,带来的不是性能变强,反而会招致网络收敛变得更慢,准确率也变得更差。
网络退化现象degradation
假设存在一个最优化的网络结构,例如10层,但是我们并不知道具体到哪个层次的网络才是最优的,如果我们设计了一个18层的结构,那么后面的8层都是冗余的,我们希望模型可以在训练中把多出来的层数进行恒等映射,即经过这层时的输入与输出完全相同. 但是模型是很难把多出来的8层的恒等变换参数学习正确,导致模型退化,不过这个不是过拟合产生的,训练的loss是增加的,所以这是因为网络冗余无法正确学习恒等映射参数而导致的.
从信息论的角度讲,由于DPI(数据处理不等式)的存在,在前向传输的过程中,随着层数的加深,Feature Map包含的图像信息会逐层减少,而ResNet的直接映射的加入,保证了 l + 1 l+1 l+1层的网络一定比 l l l层包含更多的图像信息。

虚线框里面的就是残差块,里面放上什么网络都可以,例如全连接网络、CNN等,因为ResNet是在ImageNet比赛中获得成功的,所以我们多用于处理图像,所以通常也是放CNN进去. 加权运算就是对卷积核的运算。 这幅图可能让人理解还不够深刻,结合下面的解释可能会理解更深:
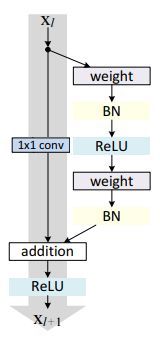
一个残差块可以用这个公式表示: x l + 1 = x l + F ( x l , W l ) x_{l+1}=x_l + F(x_l,W_l) xl+1=xl+F(xl,Wl)
左边一条直线下来的,是直接映射部分, h ( x l ) h(x_l) h(xl);右边是 F ( x l , W l ) F(x_l,W_l) F(xl,Wl)残差部分,一般由2至3个卷积操作组成
weight指的是卷积操作,addition指单位加操作.
因为卷积网络中,可能 x l x_l xl和 x l + 1 x_{l+1} xl+1的feature map数量不同,这时候需要1x1的卷积操作来进行维度的变化:
x l + 1 = h ( x l ) + F ( x l , W l ) h ( x l ) = W l x ( W l 为 1 x 1 卷 积 操 作 ) x_{l+1}=h(x_l) + F(x_l,W_l) \\ h(x_l) = W_l x (W_l为1x1卷积操作) xl+1=h(xl)+F(xl,Wl)h(xl)=Wlx(Wl为1x1卷积操作)
网络结构上去分析
普通网络结构:

残差网络结构:
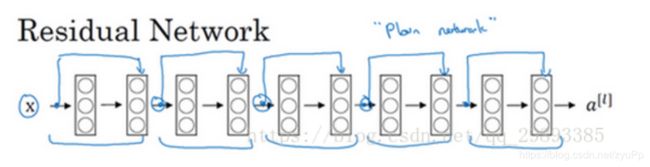
把普通网络变成ResNet的方法是加上所有跳跃连接,每两层增加一个shortcut,构成一个残差块。如图所示,5个残差块连接在一起构成一个残差网络
代码实现就不放了,不过可以说一下设计思路:
- 设计残差块,其实就是我们平时使用的网络层,堆积两个卷积层,最后加上一个forward层计算输入x和残差F的和
- 设计残差网络,先设计输入层,卷积+正则化+激活函数+maxpooling,判断是否第一个模块,第一个模块的输入和输出是相同的,判断是不是第一个残差块,需要修改残差块增加做1x1卷积来通道变换,后面就是调用残差块
- 累加残差块形成残差网络
残差块的定义
在统计学中,残差和误差是非常容易混淆的两个概念。误差是衡量观测值和真实值之间的差距,残差是指预测值和观测值之间的差距。对于残差网络的命名原因,作者给出的解释是,网络的一层通常可以看做 y = H ( x ) y=H(x) y=H(x) , 而残差网络的一个残差块可以表示为 H ( x ) = F ( x ) + x H(x)=F(x)+x H(x)=F(x)+x,也就是 [公式] ,在单位映射中, F ( x ) = H ( x ) − x F(x)=H(x)-x F(x)=H(x)−x 便是观测值,而 y = x y=x y=x 是预测值,所以 H ( x ) H(x) H(x) 便对应着残差,因此叫做残差网络。
残差网络解决的问题
-
如何解决梯度消失?
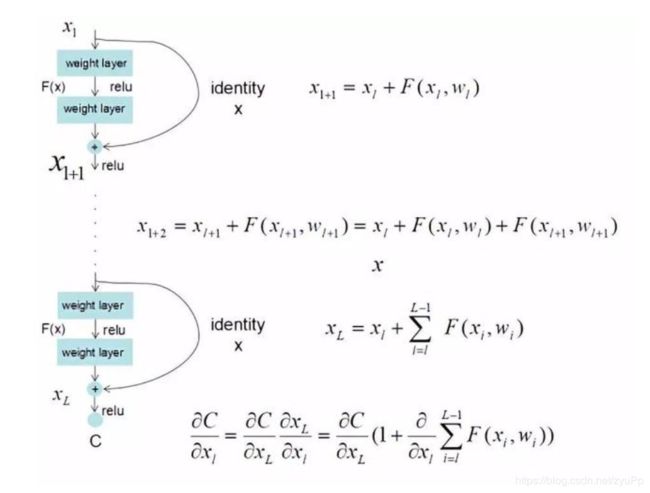
上面这样图完美解释了为什么可以保证该节点不会出现梯度消失或爆炸,因为做完链式求导之后,无论对 x l x_l xl求导有多小,旁边都有1加上,并且将原来的链式求导中的连乘变成了连加状态 -
解决网络退化问题
我们知道比起学习h(x)=x,我们令h(x)=F(x)+x,然后学习F(x)=0会更加简单,F(x)是残差项,因为一般每层网络中的参数初始化偏向于0,这样在相比于更新该网络层的参数来学习h(x)=x,该冗余层学习F(x)=0的更新参数能够更快收敛.
留一点问题给自己:
F(x)也算是经过网络学习出来的一种参数,我们目的是为了恒等映射,所以想让它变成0,但是如果放在网络的前面,不会造成什么都没学习到吗?只是变成输入的直接映射?网络是如何去分辨是否到了冗余层?有很多没懂的地方~
参考文章:
https://zhuanlan.zhihu.com/p/42706477
https://www.cnblogs.com/gczr/p/10127723.html
稠密连接网络DenseNet
 主要构建模块:
主要构建模块:
稠密块(dense block): 定义了输入和输出是如何连结的。
过渡层(transition layer):用来控制通道数,使之不过大。
区别:使用了concat通道数的方式,不需要A和B的输入输出维度相同
稠密块:
def conv_block(in_channels, out_channels):
blk = nn.Sequential(nn.BatchNorm2d(in_channels),
nn.ReLU(),
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
return blk
class DenseBlock(nn.Module):
def __init__(self, num_convs, in_channels, out_channels):
super(DenseBlock, self).__init__()
net = []
for i in range(num_convs):
in_c = in_channels + i * out_channels
net.append(conv_block(in_c, out_channels))
self.net = nn.ModuleList(net)
self.out_channels = in_channels + num_convs * out_channels # 计算输出通道数
def forward(self, X):
for blk in self.net:
Y = blk(X)
X = torch.cat((X, Y), dim=1) # 在通道维上将输入和输出连结
return X
过渡块:
1 × 1 1\times1 1×1卷积层:来减小通道数
步幅为2的平均池化层:减半高和宽
def transition_block(in_channels, out_channels):
blk = nn.Sequential(
nn.BatchNorm2d(in_channels),
nn.ReLU(),
nn.Conv2d(in_channels, out_channels, kernel_size=1),
nn.AvgPool2d(kernel_size=2, stride=2))
return blk
DenseNet模型
net = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
num_channels, growth_rate = 64, 32 # num_channels为当前的通道数
num_convs_in_dense_blocks = [4, 4, 4, 4] #每个dense层有4层的卷积
for i, num_convs in enumerate(num_convs_in_dense_blocks):
DB = DenseBlock(num_convs, num_channels, growth_rate)
net.add_module("DenseBlosk_%d" % i, DB)
# 上一个稠密块的输出通道数
num_channels = DB.out_channels
# 在稠密块之间加入通道数减半的过渡层
if i != len(num_convs_in_dense_blocks) - 1:
net.add_module("transition_block_%d" % i, transition_block(num_channels, num_channels // 2))
num_channels = num_channels // 2
net.add_module("BN", nn.BatchNorm2d(num_channels))
net.add_module("relu", nn.ReLU())
net.add_module("global_avg_pool", d2l.GlobalAvgPool2d()) # GlobalAvgPool2d的输出: (Batch, num_channels, 1, 1)
net.add_module("fc", nn.Sequential(d2l.FlattenLayer(), nn.Linear(num_channels, 10)))
看看模型结构:
X = torch.rand((1, 1, 96, 96))
for name, layer in net.named_children():
X = layer(X)
print(name, ' output shape:\t', X.shape)
上面这段代码是一共有4个稠密层,每个稠密层之间有一个过渡层,最后加上一个全局平均池化和全连接输出
凸优化
经过了一连串的学习,大概都了解什么是优化函数,我们经常用的SGD就是其中的一个,不过优化方法的目标与深度学习目标是不同的。优化方法目标是训练集损失函数值,而深度学习目标是测试集损失函数值(泛化性)
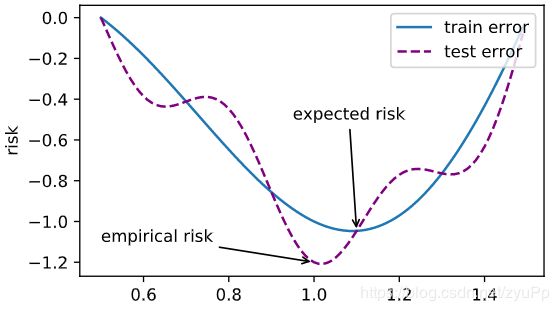
优化方法在深度学习遇到的问题
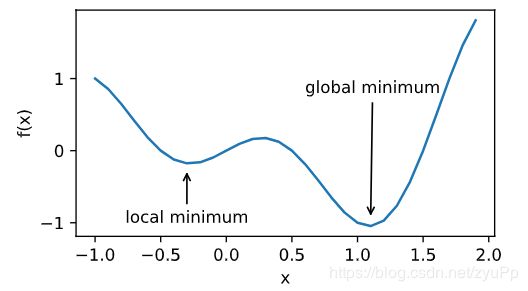
局部最小值
梯度下降方法遇到的一个问题,会停留在局部最小值。
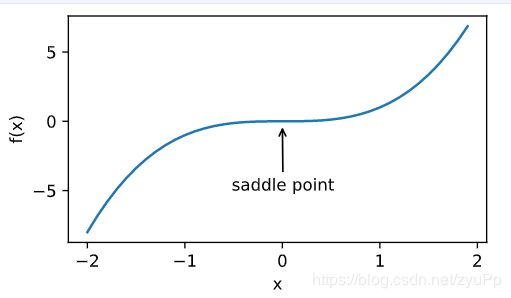
鞍点
在做梯度优化时,走到saddle point,梯度为0,无法继续优化
鞍点是对所有自变量一阶偏导数都为0,且Hessian矩阵特征值有正有负的点
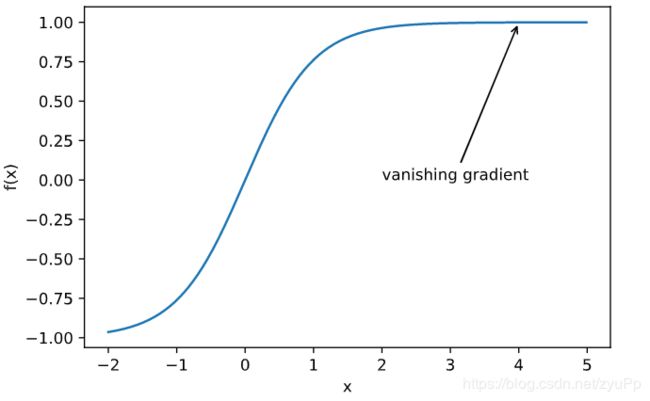
梯度消失
梯度太小,导致算法优化非常慢
凸性 (Convexity)
λ f ( x ) + ( 1 − λ ) f ( x ′ ) ≥ f ( λ x + ( 1 − λ ) x ′ ) \lambda f(x)+(1-\lambda) f\left(x^{\prime}\right) \geq f\left(\lambda x+(1-\lambda) x^{\prime}\right) λf(x)+(1−λ)f(x′)≥f(λx+(1−λ)x′)
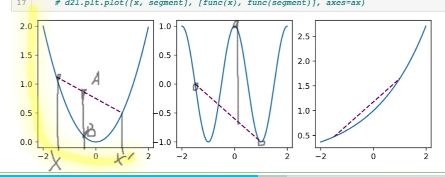
结合公式和图片来看,图一A点就是大于B点,所以是convex的
而图二虚线上的点事小于蓝色线上的点,所以是非凸的
图三也是凸的
对于凸函数有一个Jensen 不等式
∑ i α i f ( x i ) ≥ f ( ∑ i α i x i ) and E x [ f ( x ) ] ≥ f ( E x [ x ] ) \sum_{i} \alpha_{i} f\left(x_{i}\right) \geq f\left(\sum_{i} \alpha_{i} x_{i}\right) \text { and } E_{x}[f(x)] \geq f\left(E_{x}[x]\right) i∑αif(xi)≥f(i∑αixi) and Ex[f(x)]≥f(Ex[x])
理解就是: 函数的期望值要大于等于期望的函数值
凸函数的性质
- 无局部极小值
- 与凸集的关系
- 二阶条件
无局部极小值
使用反证法证明,即存在局部极小值:
假设存在 x ∈ X x \in X x∈X 是局部最小值,则存在全局最小值 x ′ ∈ X x' \in X x′∈X, 使得 f ( x ) > f ( x ′ ) f(x) > f(x') f(x)>f(x′), 则对 λ ∈ ( 0 , 1 ] \lambda \in(0,1] λ∈(0,1]:
f ( x ) > λ f ( x ) + ( 1 − λ ) f ( x ′ ) ≥ f ( λ x + ( 1 − λ ) x ′ ) f(x)>\lambda f(x)+(1-\lambda) f(x^{\prime}) \geq f(\lambda x+(1-\lambda) x^{\prime}) f(x)>λf(x)+(1−λ)f(x′)≥f(λx+(1−λ)x′)
首先看 f ( x ) > λ f ( x ) + ( 1 − λ ) f ( x ′ ) f(x)>\lambda f(x)+(1-\lambda) f(x^{\prime}) f(x)>λf(x)+(1−λ)f(x′),我们知道 f ( x ) = λ f ( x ) + ( 1 − λ ) f ( x ) f(x)=\lambda f(x)+(1-\lambda) f(x) f(x)=λf(x)+(1−λ)f(x)的,把后面的 x x x换成 x ′ x^{\prime} x′就变成了大于号,因为 f ( x ) > f ( x ′ ) f(x) > f(x') f(x)>f(x′)。
然后看后面的式子: λ f ( x ) + ( 1 − λ ) f ( x ′ ) ≥ f ( λ x + ( 1 − λ ) x ′ ) \lambda f(x)+(1-\lambda) f(x^{\prime}) \geq f(\lambda x+(1-\lambda) x^{\prime}) λf(x)+(1−λ)f(x′)≥f(λx+(1−λ)x′),这个就是我们上面提到的jessen不等式性质,而 f ( λ x + ( 1 − λ ) x ′ ) f(\lambda x+(1-\lambda) x^{\prime}) f(λx+(1−λ)x′)代表的是X的任意领域上的点的函数值
所以反过来想,f(x)是大于X的领域,所以f(x)是局部极小值是矛盾的
与凸集的关系
对于凸函数 f ( x ) f(x) f(x),定义集合 S b : = { x ∣ x ∈ X and f ( x ) ≤ b } S_{b}:=\{x | x \in X \text { and } f(x) \leq b\} Sb:={x∣x∈X and f(x)≤b},则集合 S b S_b Sb 为凸集
证明:对于点 x , x ′ ∈ S b x,x' \in S_b x,x′∈Sb, 有 f ( λ x + ( 1 − λ ) x ′ ) ≤ λ f ( x ) + ( 1 − λ ) f ( x ′ ) ≤ b f\left(\lambda x+(1-\lambda) x^{\prime}\right) \leq \lambda f(x)+(1-\lambda) f\left(x^{\prime}\right) \leq b f(λx+(1−λ)x′)≤λf(x)+(1−λ)f(x′)≤b, 故 λ x + ( 1 − λ ) x ′ ∈ S b \lambda x+(1-\lambda) x^{\prime} \in S_{b} λx+(1−λ)x′∈Sb
凸函数与二阶导数
f ′ ′ ( x ) ≥ 0 ⟺ f ( x ) f^{''}(x) \ge 0 \Longleftrightarrow f(x) f′′(x)≥0⟺f(x) 是凸函数
必要性 ( ⇐ \Leftarrow ⇐):
对于凸函数:
1 2 f ( x + ϵ ) + 1 2 f ( x − ϵ ) ≥ f ( x + ϵ 2 + x − ϵ 2 ) = f ( x ) \frac{1}{2} f(x+\epsilon)+\frac{1}{2} f(x-\epsilon) \geq f\left(\frac{x+\epsilon}{2}+\frac{x-\epsilon}{2}\right)=f(x) 21f(x+ϵ)+21f(x−ϵ)≥f(2x+ϵ+2x−ϵ)=f(x)
故:
f ′ ′ ( x ) = lim ε → 0 f ( x + ϵ ) − f ( x ) ϵ − f ( x ) − f ( x − ϵ ) ϵ ϵ f^{\prime \prime}(x)=\lim _{\varepsilon \rightarrow 0} \frac{\frac{f(x+\epsilon) - f(x)}{\epsilon}-\frac{f(x) - f(x-\epsilon)}{\epsilon}}{\epsilon} f′′(x)=ε→0limϵϵf(x+ϵ)−f(x)−ϵf(x)−f(x−ϵ)
f ′ ′ ( x ) = lim ε → 0 f ( x + ϵ ) + f ( x − ϵ ) − 2 f ( x ) ϵ 2 ≥ 0 f^{\prime \prime}(x)=\lim _{\varepsilon \rightarrow 0} \frac{f(x+\epsilon)+f(x-\epsilon)-2 f(x)}{\epsilon^{2}} \geq 0 f′′(x)=ε→0limϵ2f(x+ϵ)+f(x−ϵ)−2f(x)≥0
充分性 ( ⇒ \Rightarrow ⇒):
令 a < x < b a < x < b a<x<b 为 f ( x ) f(x) f(x) 上的三个点,由拉格朗日中值定理:
f ( x ) − f ( a ) = ( x − a ) f ′ ( α ) for some α ∈ [ a , x ] and f ( b ) − f ( x ) = ( b − x ) f ′ ( β ) for some β ∈ [ x , b ] \begin{array}{l}{f(x)-f(a)=(x-a) f^{\prime}(\alpha) \text { for some } \alpha \in[a, x] \text { and }} \\ {f(b)-f(x)=(b-x) f^{\prime}(\beta) \text { for some } \beta \in[x, b]}\end{array} f(x)−f(a)=(x−a)f′(α) for some α∈[a,x] and f(b)−f(x)=(b−x)f′(β) for some β∈[x,b]
根据单调性,有 f ′ ( β ) ≥ f ′ ( α ) f^{\prime}(\beta) \geq f^{\prime}(\alpha) f′(β)≥f′(α), 故:
f ( b ) − f ( a ) = f ( b ) − f ( x ) + f ( x ) − f ( a ) = ( b − x ) f ′ ( β ) + ( x − a ) f ′ ( α ) ≥ ( b − a ) f ′ ( α ) \begin{aligned} f(b)-f(a) &=f(b)-f(x)+f(x)-f(a) \\ &=(b-x) f^{\prime}(\beta)+(x-a) f^{\prime}(\alpha) \\ & \geq(b-a) f^{\prime}(\alpha) \end{aligned} f(b)−f(a)=f(b)−f(x)+f(x)−f(a)=(b−x)f′(β)+(x−a)f′(α)≥(b−a)f′(α)
带有限制条件的函数是怎么做优化的?
假设我们有f(x),第二个是限制条件
minimize x f ( x ) subject to c i ( x ) ≤ 0 for all i ∈ { 1 , … , N } \begin{array}{l}{\underset{\mathbf{x}}{\operatorname{minimize}} f(\mathbf{x})} \\ {\text { subject to } c_{i}(\mathbf{x}) \leq 0 \text { for all } i \in\{1, \ldots, N\}}\end{array} xminimizef(x) subject to ci(x)≤0 for all i∈{1,…,N}
对于这个问题,我们有几个方法:
- 拉格朗日乘子法
L ( x , α ) = f ( x ) + ∑ i α i c i ( x ) where α i ≥ 0 L(\mathbf{x}, \alpha)=f(\mathbf{x})+\sum_{i} \alpha_{i} c_{i}(\mathbf{x}) \text { where } \alpha_{i} \geq 0 L(x,α)=f(x)+i∑αici(x) where αi≥0
具体资料自己去查:
查资料
-
惩罚项
欲使 c i ( x ) ≤ 0 c_i(x) \leq 0 ci(x)≤0, 将项 α i c i ( x ) \alpha_ic_i(x) αici(x) 加入目标函数,如多层感知机章节中的 λ 2 ∣ ∣ w ∣ ∣ 2 \frac{\lambda}{2} ||w||^2 2λ∣∣w∣∣2 -
投影
Proj X ( x ) = argmin x ′ ∈ X ∥ x − x ′ ∥ 2 \operatorname{Proj}_{X}(\mathbf{x})=\underset{\mathbf{x}^{\prime} \in X}{\operatorname{argmin}}\left\|\mathbf{x}-\mathbf{x}^{\prime}\right\|_{2} ProjX(x)=x′∈Xargmin∥x−x′∥2

我是没看懂的,只是把相关知识点放上来,数学真难~~~
梯度下降法
证明:沿梯度反方向移动自变量可以减小函数值
泰勒展开:
f ( x + ϵ ) = f ( x ) + ϵ f ′ ( x ) + O ( ϵ 2 ) f(x+\epsilon)=f(x)+\epsilon f^{\prime}(x)+\mathcal{O}\left(\epsilon^{2}\right) f(x+ϵ)=f(x)+ϵf′(x)+O(ϵ2)
代入沿梯度方向的移动量 η f ′ ( x ) \eta f^{\prime}(x) ηf′(x)。 η \eta η是学习率:
f ( x − η f ′ ( x ) ) = f ( x ) − η f ′ 2 ( x ) + O ( η 2 f ′ 2 ( x ) ) f\left(x-\eta f^{\prime}(x)\right)=f(x)-\eta f^{\prime 2}(x)+\mathcal{O}\left(\eta^{2} f^{\prime 2}(x)\right) f(x−ηf′(x))=f(x)−ηf′2(x)+O(η2f′2(x))
看f(x)减去一个正数, η \eta η足够小,得到
f ( x − η f ′ ( x ) ) ≲ f ( x ) f\left(x-\eta f^{\prime}(x)\right) \lesssim f(x) f(x−ηf′(x))≲f(x)
x ← x − η f ′ ( x ) x \leftarrow x-\eta f^{\prime}(x) x←x−ηf′(x)
下面是 f ( x ) = x 2 f(x)=x^2 f(x)=x2的举例证明代码:
def f(x):
return x**2 # Objective function
def gradf(x):
return 2 * x # Its derivative
def gd(eta):
x = 10
results = [x]
for i in range(10):
x -= eta * gradf(x)
results.append(x)
print('epoch 10, x:', x)
return results
res = gd(0.2)
def show_trace(res):
n = max(abs(min(res)), abs(max(res)))
f_line = np.arange(-n, n, 0.01)
d2l.set_figsize((3.5, 2.5))
d2l.plt.plot(f_line, [f(x) for x in f_line],'-')
d2l.plt.plot(res, [f(x) for x in res],'-o')
d2l.plt.xlabel('x')
d2l.plt.ylabel('f(x)')
show_trace(res)
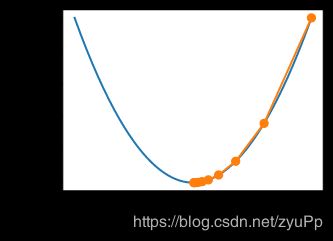
学习率
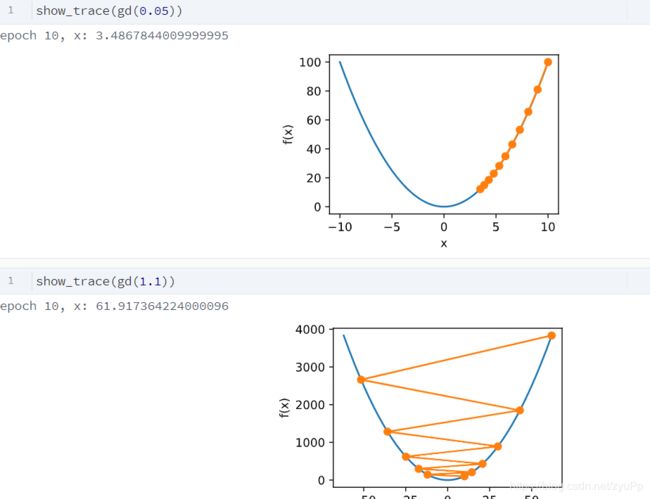
下面是分别学习率过小和过大的情况,过小的时候,会学习得特别慢,经过10个epoch还没到最优点,而过大的情况,会导致二阶项更大,反而导致梯度上升了
局部极小值
以下是因为学习率过大导致的局部极小值
f ( x ) = x cos c x f(x) = x\cos cx f(x)=xcoscx
c = 0.15 * np.pi
def f(x):
return x * np.cos(c * x)
def gradf(x):
return np.cos(c * x) - c * x * np.sin(c * x)
show_trace(gd(2))
这里的学习率为2,初始值是10,如果学习率小一点是可以学习到全局最优的,但是跳了出去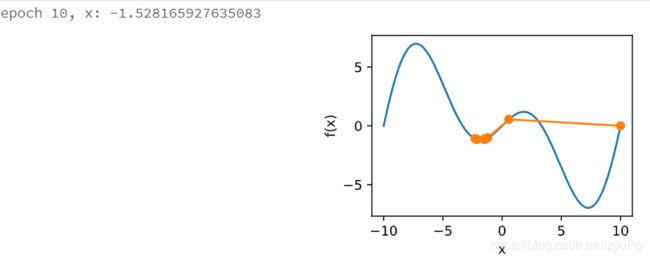
多维度梯度下降
上面我们都是使用标量的式子,通常模型复杂了,就有多个维度,例如 f ( x ) = x 1 2 + 2 x 2 2 f(x) = x_1^2 + 2x_2^2 f(x)=x12+2x22
而我们的多维度梯度下降的方法,就是按照每个维度来求梯度下降
∇ f ( x ) = [ ∂ f ( x ) ∂ x 1 , ∂ f ( x ) ∂ x 2 , … , ∂ f ( x ) ∂ x d ] ⊤ \nabla f(\mathbf{x})=\left[\frac{\partial f(\mathbf{x})}{\partial x_{1}}, \frac{\partial f(\mathbf{x})}{\partial x_{2}}, \dots, \frac{\partial f(\mathbf{x})}{\partial x_{d}}\right]^{\top} ∇f(x)=[∂x1∂f(x),∂x2∂f(x),…,∂xd∂f(x)]⊤
f ( x + ϵ ) = f ( x ) + ϵ ⊤ ∇ f ( x ) + O ( ∥ ϵ ∥ 2 ) f(\mathbf{x}+\epsilon)=f(\mathbf{x})+\epsilon^{\top} \nabla f(\mathbf{x})+\mathcal{O}\left(\|\epsilon\|^{2}\right) f(x+ϵ)=f(x)+ϵ⊤∇f(x)+O(∥ϵ∥2)
x ← x − η ∇ f ( x ) \mathbf{x} \leftarrow \mathbf{x}-\eta \nabla f(\mathbf{x}) x←x−η∇f(x)
下面是代码示例:
def train_2d(trainer, steps=20):
x1, x2 = -5, -2
results = [(x1, x2)]
for i in range(steps):
x1, x2 = trainer(x1, x2)
results.append((x1, x2))
print('epoch %d, x1 %f, x2 %f' % (i + 1, x1, x2))
return results
def show_trace_2d(f, results):
d2l.plt.plot(*zip(*results), '-o', color='#ff7f0e')
x1, x2 = np.meshgrid(np.arange(-5.5, 1.0, 0.1), np.arange(-3.0, 1.0, 0.1))
d2l.plt.contour(x1, x2, f(x1, x2), colors='#1f77b4')
d2l.plt.xlabel('x1')
d2l.plt.ylabel('x2')
eta = 0.1
def f_2d(x1, x2): # 目标函数
return x1 ** 2 + 2 * x2 ** 2
def gd_2d(x1, x2):
return (x1 - eta * 2 * x1, x2 - eta * 4 * x2)
show_trace_2d(f_2d, train_2d(gd_2d))
可以看到沿着梯度垂直方向,不断求导,得到最优

自适应法
设置的学习率非常影响学习效果,自适应法可以帮助我们学习到二阶的求导,让学习率自己调整,不过其实这些方法多数不会用于实战,因为计算量比较大,不过有一定启发作用~
牛顿法
在 x + ϵ x + \epsilon x+ϵ 处泰勒展开:
f ( x + ϵ ) = f ( x ) + ϵ ⊤ ∇ f ( x ) + 1 2 ϵ ⊤ ∇ ∇ ⊤ f ( x ) ϵ + O ( ∥ ϵ ∥ 3 ) f(\mathbf{x}+\epsilon)=f(\mathbf{x})+\epsilon^{\top} \nabla f(\mathbf{x})+\frac{1}{2} \epsilon^{\top} \nabla \nabla^{\top} f(\mathbf{x}) \epsilon+\mathcal{O}\left(\|\epsilon\|^{3}\right) f(x+ϵ)=f(x)+ϵ⊤∇f(x)+21ϵ⊤∇∇⊤f(x)ϵ+O(∥ϵ∥3)
最小值点处满足: ∇ f ( x ) = 0 \nabla f(\mathbf{x})=0 ∇f(x)=0, 即我们希望 ∇ f ( x + ϵ ) = 0 \nabla f(\mathbf{x} + \epsilon)=0 ∇f(x+ϵ)=0, 对上式关于 ϵ \epsilon ϵ 求导,忽略高阶无穷小,有:
∇ f ( x ) + H f ϵ = 0 and hence ϵ = − H f − 1 ∇ f ( x ) \nabla f(\mathbf{x})+\boldsymbol{H}_{f} \boldsymbol{\epsilon}=0 \text { and hence } \epsilon=-\boldsymbol{H}_{f}^{-1} \nabla f(\mathbf{x}) ∇f(x)+Hfϵ=0 and hence ϵ=−Hf−1∇f(x)
c = 0.5
def f(x):
return np.cosh(c * x) # Objective
def gradf(x):
return c * np.sinh(c * x) # Derivative
def hessf(x):
return c**2 * np.cosh(c * x) # Hessian
# Hide learning rate for now
def newton(eta=1):
x = 10
results = [x]
for i in range(10):
x -= eta * gradf(x) / hessf(x)
results.append(x)
print('epoch 10, x:', x)
return results
show_trace(newton())
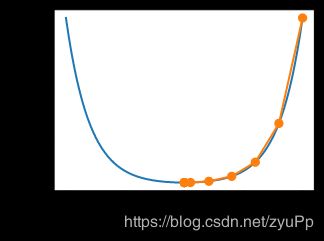
随机梯度下降
对于有 n n n 个样本对训练数据集,设 f i ( x ) f_i(x) fi(x) 是第 i i i 个样本的损失函数, 则目标函数为:
f ( x ) = 1 n ∑ i = 1 n f i ( x ) f(\mathbf{x})=\frac{1}{n} \sum_{i=1}^{n} f_{i}(\mathbf{x}) f(x)=n1i=1∑nfi(x)
其梯度为:
∇ f ( x ) = 1 n ∑ i = 1 n ∇ f i ( x ) \nabla f(\mathbf{x})=\frac{1}{n} \sum_{i=1}^{n} \nabla f_{i}(\mathbf{x}) ∇f(x)=n1i=1∑n∇fi(x)
使用该梯度的一次更新的时间复杂度为 O ( n ) \mathcal{O}(n) O(n)
随机梯度下降更新公式 O ( 1 ) \mathcal{O}(1) O(1):
x ← x − η ∇ f i ( x ) \mathbf{x} \leftarrow \mathbf{x}-\eta \nabla f_{i}(\mathbf{x}) x←x−η∇fi(x)
且有:
E i ∇ f i ( x ) = 1 n ∑ i = 1 n ∇ f i ( x ) = ∇ f ( x ) \mathbb{E}_{i} \nabla f_{i}(\mathbf{x})=\frac{1}{n} \sum_{i=1}^{n} \nabla f_{i}(\mathbf{x})=\nabla f(\mathbf{x}) Ei∇fi(x)=n1i=1∑n∇fi(x)=∇f(x)
下面将会按照 f ( x 1 , x 2 ) = x 1 2 + 2 x 2 2 f(x_1, x_2) = x_1^2 + 2 x_2^2 f(x1,x2)=x12+2x22这个式子,做一次SGD
def f(x1, x2):
return x1 ** 2 + 2 * x2 ** 2 # Objective
def gradf(x1, x2):
return (2 * x1, 4 * x2) # Gradient
def sgd(x1, x2): # Simulate noisy gradient
global lr # Learning rate scheduler
(g1, g2) = gradf(x1, x2) # Compute gradient
(g1, g2) = (g1 + np.random.normal(0.1), g2 + np.random.normal(0.1)) #添加一些噪声,看上去更真实
eta_t = eta * lr() # Learning rate at time t
return (x1 - eta_t * g1, x2 - eta_t * g2) # Update variables
eta = 0.1
lr = (lambda: 1) # Constant learning rate
show_trace_2d(f, train_2d(sgd, steps=50))
可以看到在最优点附近,出现了抖动,因为每个样本都是不一样的,所以还会持续做一点梯度的更新,那么我们应该怎么去修改这种情况呢?看下面~
动态学习率
η ( t ) = η i if t i ≤ t ≤ t i + 1 piecewise constant η ( t ) = η 0 ⋅ e − λ t exponential η ( t ) = η 0 ⋅ ( β t + 1 ) − α polynomial \begin{array}{ll}{\eta(t)=\eta_{i} \text { if } t_{i} \leq t \leq t_{i+1}} & {\text { piecewise constant }} \\ {\eta(t)=\eta_{0} \cdot e^{-\lambda t}} & {\text { exponential }} \\ {\eta(t)=\eta_{0} \cdot(\beta t+1)^{-\alpha}} & {\text { polynomial }}\end{array} η(t)=ηi if ti≤t≤ti+1η(t)=η0⋅e−λtη(t)=η0⋅(βt+1)−α piecewise constant exponential polynomial
第一种是通过硬性规定不同时间段的学习率赋值
第二种是指数,代码和实际情况,ctr代表:迭代次数
def exponential():
global ctr
ctr += 1
return math.exp(-0.1 * ctr)
ctr = 1
lr = exponential # Set up learning rate
show_trace_2d(f, train_2d(sgd, steps=1000))

第三种是多项式
def polynomial():
global ctr
ctr += 1
return (1 + 0.1 * ctr)**(-0.5)
ctr = 1
lr = polynomial # Set up learning rate
show_trace_2d(f, train_2d(sgd, steps=50))
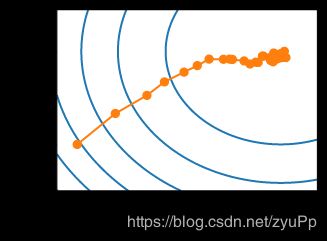
小批量随机梯度下降
之前已经说过关于mini-batch的sgd,这里做一次实现来看看效果~
- 获取数据
def get_data_ch7(): # 本函数已保存在d2lzh_pytorch包中方便以后使用
data = np.genfromtxt('input/airfoil4755/airfoil_self_noise.dat', delimiter='\t')
data = (data - data.mean(axis=0)) / data.std(axis=0) # 标准化
return torch.tensor(data[:1500, :-1], dtype=torch.float32), \
torch.tensor(data[:1500, -1], dtype=torch.float32) # 前1500个样本(每个样本5个特征)
features, labels = get_data_ch7()
features.shape
查看数据特征:
import pandas as pd
df = pd.read_csv('/input/airfoil4755/airfoil_self_noise.dat', delimiter='\t', header=None)
df.head(10)
SGD:
def sgd(params, states, hyperparams): #params模型参数,hyperparams这里是学习率
for p in params:
p.data -= hyperparams['lr'] * p.grad.data
训练函数:
# 本函数已保存在d2lzh_pytorch包中方便以后使用
def train_ch7(optimizer_fn, states, hyperparams, features, labels,
batch_size=10, num_epochs=2): #对于整个训练集做两次
# 初始化模型
net, loss = d2l.linreg, d2l.squared_loss #线性模型和平方误差
w = torch.nn.Parameter(torch.tensor(np.random.normal(0, 0.01, size=(features.shape[1], 1)), dtype=torch.float32),
requires_grad=True)
b = torch.nn.Parameter(torch.zeros(1, dtype=torch.float32), requires_grad=True)
def eval_loss():
return loss(net(features, w, b), labels).mean().item()
ls = [eval_loss()]
data_iter = torch.utils.data.DataLoader( #数据迭代器,每次生成一个batch
torch.utils.data.TensorDataset(features, labels), batch_size, shuffle=True)
for _ in range(num_epochs):
start = time.time()
for batch_i, (X, y) in enumerate(data_iter):
l = loss(net(X, w, b), y).mean() # 使用平均损失
# 梯度清零
if w.grad is not None:
w.grad.data.zero_()
b.grad.data.zero_()
l.backward()
optimizer_fn([w, b], states, hyperparams) # 迭代模型参数
if (batch_i + 1) * batch_size % 100 == 0:
ls.append(eval_loss()) # 每100个样本记录下当前训练误差
# 打印结果和作图
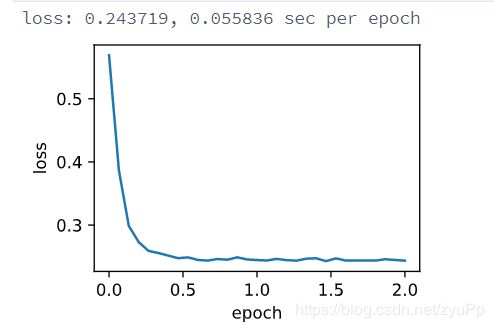
print('loss: %f, %f sec per epoch' % (ls[-1], time.time() - start))
d2l.set_figsize()
d2l.plt.plot(np.linspace(0, num_epochs, len(ls)), ls)
d2l.plt.xlabel('epoch')
d2l.plt.ylabel('loss')
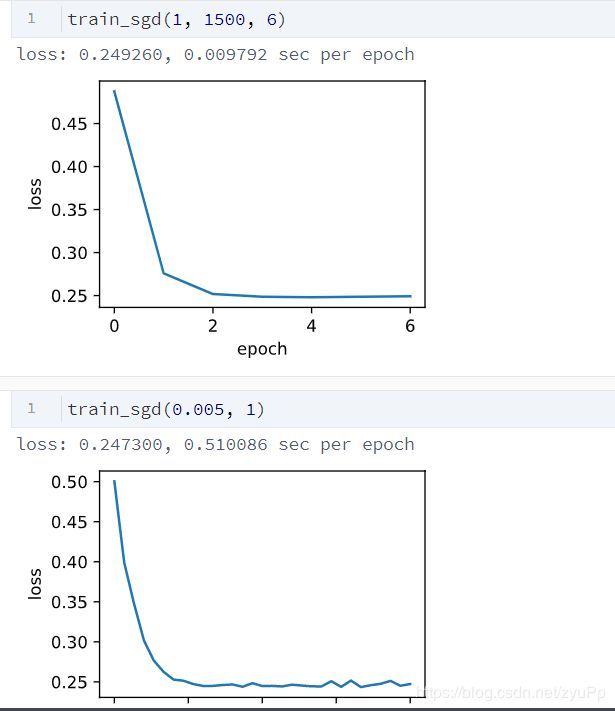
看看上面结果,大批量的一个是学习率为1,batchsizew为1500;另一个是学习率0.005,batchsize为1,为1的话就是纯的SGD了。可以看到时间上差了几十倍,这就是用batchsize的好处,利用了并行计算和线程的优势.
结合两个的优点,就是小批量的随机梯度下降:使用epoch少了,速度也相当快
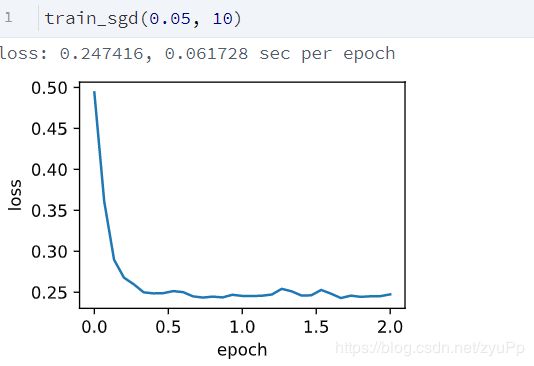
Pytorch版本的简介实现:
# 本函数与原书不同的是这里第一个参数优化器函数而不是优化器的名字
# 例如: optimizer_fn=torch.optim.SGD, optimizer_hyperparams={"lr": 0.05}
def train_pytorch_ch7(optimizer_fn, optimizer_hyperparams, features, labels,
batch_size=10, num_epochs=2):
# 初始化模型
net = nn.Sequential(
nn.Linear(features.shape[-1], 1)
)
loss = nn.MSELoss()
optimizer = optimizer_fn(net.parameters(), **optimizer_hyperparams)
def eval_loss():
return loss(net(features).view(-1), labels).item() / 2
ls = [eval_loss()]
data_iter = torch.utils.data.DataLoader(
torch.utils.data.TensorDataset(features, labels), batch_size, shuffle=True)
for _ in range(num_epochs):
start = time.time()
for batch_i, (X, y) in enumerate(data_iter):
# 除以2是为了和train_ch7保持一致, 因为squared_loss中除了2
l = loss(net(X).view(-1), y) / 2
optimizer.zero_grad()
l.backward()
optimizer.step()
if (batch_i + 1) * batch_size % 100 == 0:
ls.append(eval_loss())
# 打印结果和作图
print('loss: %f, %f sec per epoch' % (ls[-1], time.time() - start))
d2l.set_figsize()
d2l.plt.plot(np.linspace(0, num_epochs, len(ls)), ls)
d2l.plt.xlabel('epoch')
d2l.plt.ylabel('loss')
train_pytorch_ch7(optim.SGD, {"lr": 0.05}, features, labels, 10)