PRML之线性回归(Linear Models for Regression)
啰嗦两句,PRML这本书是基于贝叶斯思想进行相关机器学习算法的推导和讲解。书上有详细的公司推导,故LZ不做公式方面的读书笔记记录,来讲讲算法递进的逻辑关系。
在开始记录线性回归模型学习之前,容我们闭目独立思考两个问题:①什么是机器学习?②机器学习的本质问题是什么?这两个问题是伴随着我们机器学习生涯常常出现,There are a thousand Hamlets in a thousand people's eyes,我可以“冒昧”的说一句一千个人眼中就有一千种对机器学习的理解吧。
在我看来机器学习(machine learning)重点在learning上,简单来说,机器学习就是让计算机(machine)从大量的数据中学习到相关的规律和逻辑(learning),然后利用学习来的规律来预测以后的未知事物。而机器学习的本质问题是什么呢?就是学习,如何学习,如何有效学习。通过数据集学习未知的最佳逼近函数,学习的 收敛性\界 等等都是描述这个学习到的函数性能到底如何。我们知道这样的函数是多种多样的,它可以是线性或非线性,连续或阶跃....,甚至它们还能相互组合,那么本质问题就是如何学习找到满足条件的最佳逼近函数。
有了对机器学习的思考之后,我们开始探索一下基于贝叶斯理论的线性回归。
一.线性基函数模型
①回归模型最简单的模型是输入变量的线性组合:
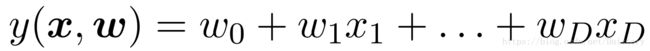
但是这样的形式w是线性的,同时x也是线性的。所以,存在极大的局限性,这样拟合出来的目标函数y只能是一个线性函数,在日常生活中不能很好的满足数据体现出来的多样性,所以有时不能很好的拟合数据展示的真实规律。为了扩展模型,将输入利用非线性转换,再进行线性组合,即w是线性的,x进行非线性转换。形式如下:
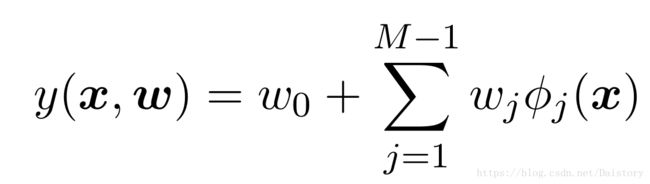
常见的基函数选择有①幂指数基函数,②高斯基函数,③sigmoid基函数
二.模型求解
1.最大似然和最小二乘
误差平方和可以定义为:
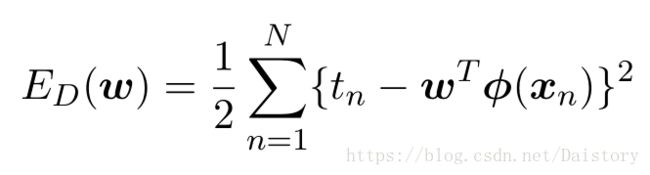
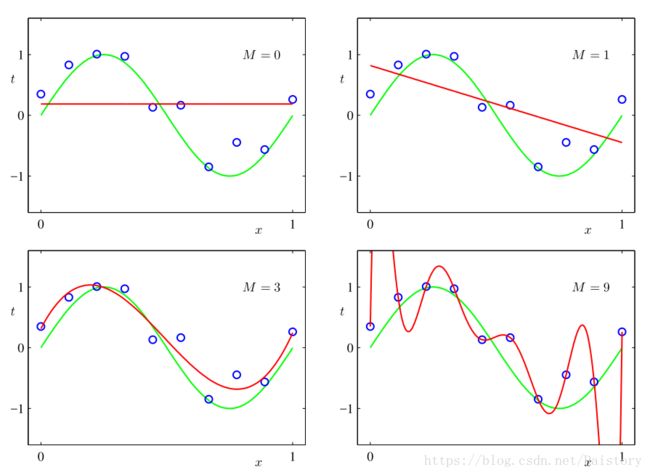
这里t对应真实值,利用求驻点的方式求出W参数的值,得到W参数的值就得到了模型,可以做预测。但是这样有有一个巨大的缺陷就是不能防止过拟合。随着模型复杂度的不断增高,误差平方和会越来越小,但是模型的泛化能力并不能得到有效保障。如下图(红色是拟合曲线,绿色是真实曲线,点是带噪声的真实数据点)
最大似然法其本质和最小二乘法是一样的。
假定目标变量t是由函数y(x,w)给出,同时附加了高斯噪声:

其中ϵ 是⼀个零均值的⾼斯随机变量,精度(⽅差的倒数)为 β 。因此,我们能得到一个关于t的高斯分布,而t关于x的条件均期望就是t的预测值。
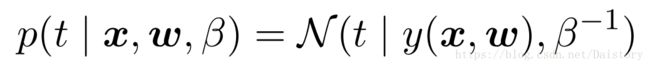
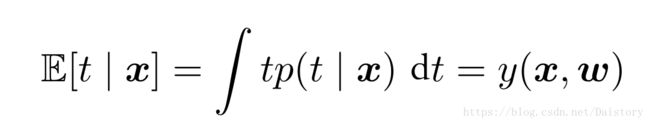
似然函数可以表示为:

利用最大似然方法求解w:
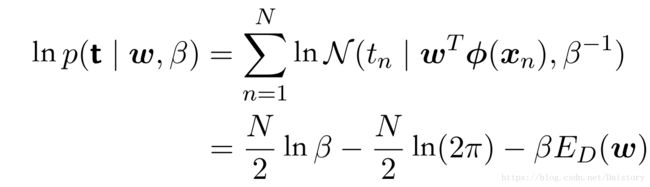
我们可以看出,最大化似然就是最小化 ED (w)和最小二乘法本质上是一致的。
2.损失函数加入正则化惩罚项
为解决过拟合的问题,统计机器学习常常做的事情是在平方和误差损失函数中加入正则化项,此正则化项通过对模型复杂度进行控制(越复杂收到的惩罚越大)。形式如下:
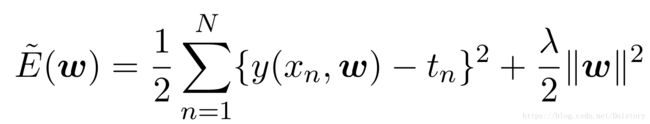
这样固然是能取到一定的效果,但是惩罚力度 λ是一个超参数,λ的设置影响到了模型的准确率。λ过小,不能有效防止过拟合;λ过大,会惩罚过重导致模型欠拟合。故,λ选择又成了一个令人头痛的问题。
为解决λ的选择问题,提出了在训练的时候单独使用一部分数据验证确定λ,但是这样做在时间上就有了新的开销。
3.贝叶斯线性回归
LZ理解的贝叶斯思想就是利用贝叶斯公式可以推导出后验概率正比于先验概率x似然函数。根据似然函数确定先验概率形式(共轭),然后给定一个基于人工经验的先验概率分布,这样的先验概率能一定程度上指导训练得到真实的数据分布(如果没有这样的先验概率。数据分布是全部由训练数据指导的,故容易出现过拟合 )
根据似然函数得到先验概率分布是高斯分布,形式是:
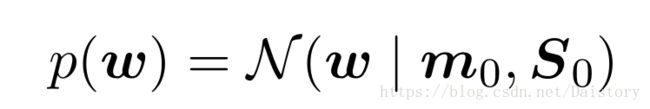
推导得到后验概率分布形式:
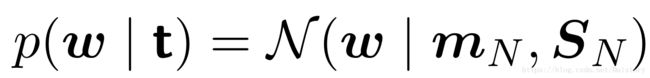
其中, Φ是设计矩阵,

因为后验概率是高斯分布,所以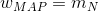 。如果我们考虑⼀个⽆限宽的先验
。如果我们考虑⼀个⽆限宽的先验 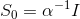 ,其中 α → 0 ,那么后验概率分
,其中 α → 0 ,那么后验概率分
布的均值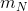 就变成了的最⼤似然值 。类似地,如果 N = 0 ,那么后验概率分布就变成了先验分布。这里我们考虑一个先验概率分布为:
就变成了的最⼤似然值 。类似地,如果 N = 0 ,那么后验概率分布就变成了先验分布。这里我们考虑一个先验概率分布为:
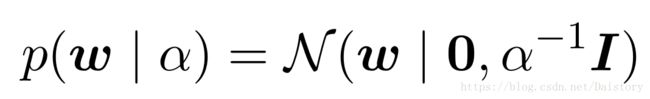
同样,后验概率依旧是高斯高斯分布,其中:
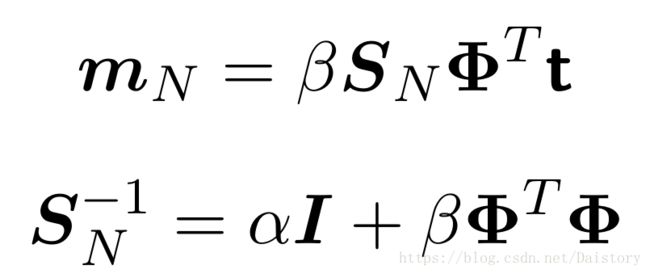
可以轻松推导出:
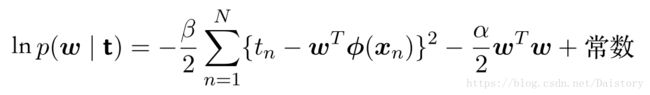
ln的功能是变乘为加,将似然函数乘先验分布变成了加和形式。这个时候形成三个部分,似然函数关于最小二乘的部分,先验分布关于w参数约束部分,以及两个部分留下和w无关的常数项。这里我们可以看出,将公式转换一下最大后验相当于最小化 :
这里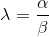 。所以,贝叶斯方法能够有效的包含正则化部分,正则化的惩罚因子
。所以,贝叶斯方法能够有效的包含正则化部分,正则化的惩罚因子 也不需要人工设置,它是由超参
也不需要人工设置,它是由超参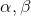 确定的。但是,这里任然存在一个令人头痛问题的超参是根据经验设置的,要是设置的不合理,一样会影响模型的准确性。
确定的。但是,这里任然存在一个令人头痛问题的超参是根据经验设置的,要是设置的不合理,一样会影响模型的准确性。
4.证据近似
既然我们是做机器学习的,我们就希望这种超参也能通过数据来确定,不同的数据出现时候,自适应的选择合适的超参数。贝叶斯不是经典的使用先验概率来调节后验概率吗?那么,就对超参数进行先验估计。这里,引入超先验分布。
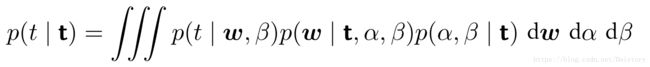
因为 最可能的取值就是它们对应的后验概率的尖峰位置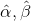 ,所以满足下面关系:
,所以满足下面关系:
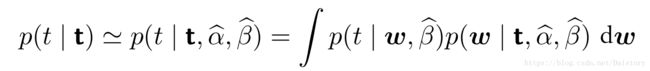
根据贝叶斯定理可以得到 的后验概率:

这个公式就充分说明了我们需要达到的目的,用数据说话。当先验分布是利用无信息先验时候(很平),那么后验概率就由似然函数确定,而似然函数和数据之间有充分联系。进行一系列的证明推导(PRML书上已经非常详细),最后得到证据函数表达式:
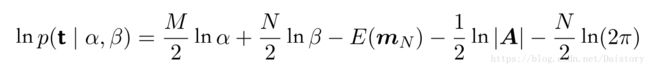
其中:
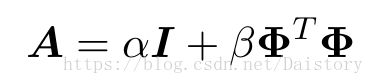
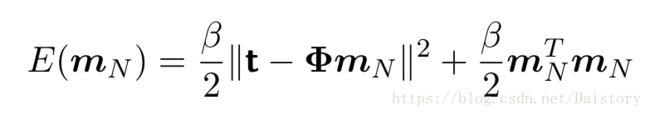

最大化证据函数求得 。
二.本章其他重要的相关知识
这里,LZ简单概括的提及一下其他相关知识。主要包括偏置-方差分解和顺序学习。
1.偏置-方差分解
通过一些简单的推理证明,我们发现期望损失可以分解成三部分:
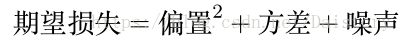
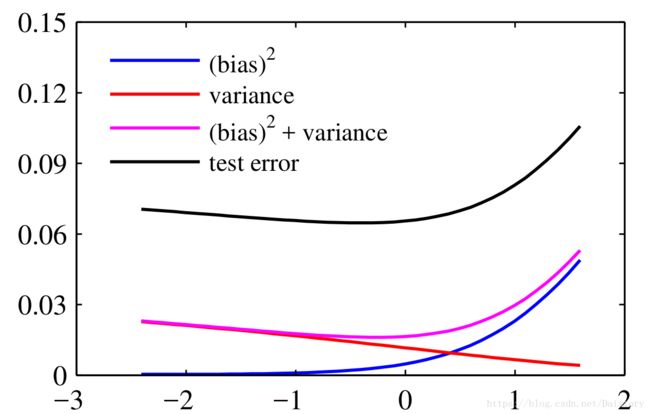
其中,噪声是数据本身存在的是,是不能通过模型优化进行降低的一个固定值。所以,我们在模型学习的过程中主要进行的是偏置和方差降低。偏置方差之间存在一种明显的“对抗关系”,一个灵活的模型偏置较小,方差较大;一个固定模型偏置较大,方差较小。所以,最小化期望损失,是要折中偏置和方差。他们之间的关系可以用下面这个图进行生动的展示。
2.顺序学习
在模型训练时候,通常是利用这个训练集直接得到参数。但这样的方式显然是有明显局限性的。①面对大规模数据时候,内存消耗巨大甚至无法计算;②面对在线流数据时候,每当新数据更新都需要使用所有数据进行训练队参数进行有效更新,这显然是不合理的,不能有效进行在线学习。为了解决这样的问题,提出顺序学习。
顺序学习的核心就是在每观测到一个新的数据点就进行相应的更新。例如,在贝叶斯模型中,当观测到一部分数据就能计算出新的后验概率,然后将后验概率作为新的先验概率吗,再观测到新的数据时候就能在得到新的后验概率。