GreenPlum 数据倾斜排查
在MPP无共享环境中,查询的总响应时间取决于单个node执行最长的process。如果数据偏斜,则具有更多数据的node将花费更多时间来完成,因此每个node必须具有大约相等的行数并执行大约相同的处理量。如果一个node要处理的数据比其他node多得多,可能会导致性能差和内存不足的情况。
将大表连接在一起时,最佳分配至关重要。要执行联接,匹配的行必须一起位于同一node上。如果数据未分配在同一DSK列上,则表之一中所需的行将动态重新分配给其他node。在某些情况下,将执行广播动作,在该动作中,每个node将其各自的行发送到所有其他node,而不是进行重新分配动作,在该重新分配动作中,每个node都会对数据进行哈希处理,然后根据哈希键将行发送到适当的node。
在GPDB中的所有表都是分布的,这意味着它们的数据被分割到系统的所有节点上。如果数据分布的不平坦,查询的性能可能会受到影响。下面的视图可以帮助诊断一张表是否出现了数据不平坦分布。
- gp_skew_coefficients
- gp_skew_idle_fractions
gp_skew_coefficients
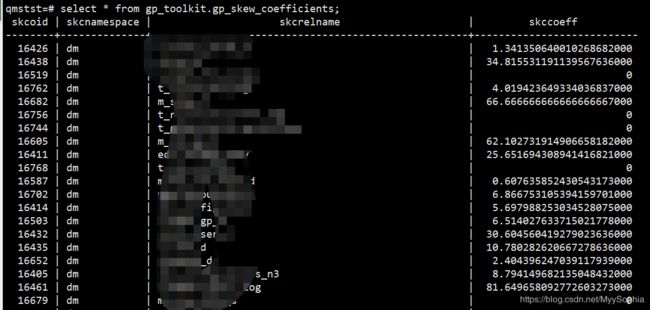
The gp_toolkit.gp_skew_coefficients view shows data distribution skew by calculating the coefficient of variation (CV) for the data stored on each segment. The skccoeff column shows the coefficient of variation (CV), which is calculated as the standard deviation divided by the average. It takes into account both the average and variability around the average of a data series. The lower the value, the better. Higher values indicate greater data skew.
此视图通过计算各实例之间的差异系数显示数据分布的倾斜。该视图对所有用户都可以访问,不过非超级用户只能查看到那些有访问权限的关系。
字段 描述
skcoid 表的对象标识符
skcnamespace表定义的名字空间
skcrelname 表的名字
skccoeff
差异系统是通过标准差除以平均值得到的。这样既考虑到了平均数也考虑到了差异性。值越小越好。越大的值表示数据倾斜越严重。
gp_skew_idle_fractions
The gp_toolkit.gp_skew_idle_fractions view shows data distribution skew by calculating the percentage of the system that is idle during a table scan, which is an indicator of computational skew. The siffraction column shows the percentage of the system that is idle during a table scan. This is an indicator of uneven data distribution or query processing skew. For example, a value of 0.1 indicates 10% skew, a value of 0.5 indicates 50% skew, and so on. Tables that have more than10% skew should have their distribution policies evaluated.
此视图通过计算表扫描期间的系统空闲百分比显示数据分布的倾斜,其作为数据处理倾斜的指标。该视图对所有用户都可以访问,不过非超级用户只能查看到那些有访问权限的关系。
字段 描述
sifoid 表的对象标识符
sifnamespace表定义的名字空间
sifname 表的名字
siffraction
表扫描期间的系统空闲百分比,其作为数据分布或者查询处理的倾斜指标。例如,0.1表示10%的倾斜,0.5表示50%的倾斜,等等。对于出现10%倾斜的表,应该对其分布策略进行评估。
以上两个view只能从静态去分析数据是否倾斜,事实上,在建立分布键的时候都有充分考虑,因此因为分布键设计不合理导致的数据倾斜很少。 后续可以继续逐步排查。
造成GP性能不好的真正的凶手应该是正在运行的某个sql产生了大量的数据motion。 这个对系统的I/O 网络 CPU的压力都是很大的。SQL中常见的join、order by、group by以及其他OLAP类型的sql,可能产生倾斜的时间并不久,但是这足以影响其他sql,影响数据库效能,如果大量的倾斜sql打到数据库上,这个是致命的。
因为process产生的倾斜是一瞬间,因此不容易catch到这些异常。
GP官方给出来一个步骤来分析process skew的例子。
1、先确定要排查的数据OID,这是为下一步要着手分析哪个数据库上有倾斜。
=# SELECT oid, datname FROM pg_database;
oid | datname
-------+-----------
1 | template1
12813 | template0
12816 | postgres
16384 | qmstst
64919 | gpperfmon
78257 | pgbench
78258 | results
(7 rows)
2、使用gpssh 从segment上统计出每个seg上data下pgsql_tmp目录的大小
目前该脚本我还在调试中
[gpadmin@mdw kend]$ gpssh -f ~/hosts -e \ "du -b /data[1-2]/primary/gpseg*/base/
Example output:
Segment node[sdw1] 2443370457 bytes (2.27557 GB)
Segment node[sdw2] 1766575328 bytes (1.64525 GB)
Segment node[sdw3] 1761686551 bytes (1.6407 GB)
Segment node[sdw4] 1780301617 bytes (1.65804 GB)
Segment node[sdw5] 1742543599 bytes (1.62287 GB)
Segment node[sdw6] 1830073754 bytes (1.70439 GB)
Segment node[sdw7] 1767310099 bytes (1.64594 GB)
Segment node[sdw8] 1765105802 bytes (1.64388 GB)
Total 14856967207 bytes (13.8366 GB)如果每个node的硬盘使用率差距比较大且持续了一段时间,应该怀疑是否为data skew导致的。脚本一次的查询并不能说明data skew,在数据查询时在GPCC界面看到某个seg的I/O 网络....较高。

3、如果出现明显且持续的偏斜,则下一个任务是识别有问题的查询。
上一步中的命令汇总了整个节点。这次,找到实际的node目录。您可以从主服务器执行此操作,也可以登录到上一步中确定的特定节点。以下是从主服务器运行的示例。
$ gpssh -f ~/hosts -e
"ls -l /data[1-2]/primary/gpseg*/base/19979/pgsql_tmp/*"
| grep -i sort | awk '{sub(/base.*tmp\//, ".../", $10); print $1,$6,$10}' | sort -k2 -nHere is output from this command:
[sdw1] 288718848
/data1/primary/gpseg2/.../pgsql_tmp_slice0_sort_17758_0001.0[sdw1] 291176448
/data2/primary/gpseg5/.../pgsql_tmp_slice0_sort_17764_0001.0[sdw8] 924581888
/data2/primary/gpseg45/.../pgsql_tmp_slice10_sort_15673_0010.9[sdw4] 980582400
/data1/primary/gpseg18/.../pgsql_tmp_slice10_sort_29425_0001.0[sdw6] 986447872
/data2/primary/gpseg35/.../pgsql_tmp_slice10_sort_29602_0001.0...[sdw5] 999620608
/data1/primary/gpseg26/.../pgsql_tmp_slice10_sort_28637_0001.0[sdw2] 999751680
/data2/primary/gpseg9/.../pgsql_tmp_slice10_sort_3969_0001.0[sdw3] 1000112128
/data1/primary/gpseg13/.../pgsql_tmp_slice10_sort_24723_0001.0[sdw5] 1000898560
/data2/primary/gpseg28/.../pgsql_tmp_slice10_sort_28641_0001.0...[sdw8] 1008009216
/data1/primary/gpseg44/.../pgsql_tmp_slice10_sort_15671_0001.0[sdw5] 1008566272
/data1/primary/gpseg24/.../pgsql_tmp_slice10_sort_28633_0001.0[sdw4] 1009451008
/data1/primary/gpseg19/.../pgsql_tmp_slice10_sort_29427_0001.0[sdw7] 1011187712
/data1/primary/gpseg37/.../pgsql_tmp_slice10_sort_18526_0001.0[sdw8] 1573741824
/data2/primary/gpseg45/.../pgsql_tmp_slice10_sort_15673_0001.0[sdw8] 1573741824
/data2/primary/gpseg45/.../pgsql_tmp_slice10_sort_15673_0002.1[sdw8] 1573741824
/data2/primary/gpseg45/.../pgsql_tmp_slice10_sort_15673_0003.2[sdw8] 1573741824
/data2/primary/gpseg45/.../pgsql_tmp_slice10_sort_15673_0004.3[sdw8] 1573741824
/data2/primary/gpseg45/.../pgsql_tmp_slice10_sort_15673_0005.4[sdw8] 1573741824
/data2/primary/gpseg45/.../pgsql_tmp_slice10_sort_15673_0006.5[sdw8] 1573741824
/data2/primary/gpseg45/.../pgsql_tmp_slice10_sort_15673_0007.6[sdw8] 1573741824
/data2/primary/gpseg45/.../pgsql_tmp_slice10_sort_15673_0008.7[sdw8] 1573741824
/data2/primary/gpseg45/.../pgsql_tmp_slice10_sort_15673_0009.8Scanning this output reveals that segment gpseg45 on host sdw8 is the culprit, as its sort files are larger than the others in the output.
4、
Log in to the offending node with ssh and become root. Use the lsof command to find the PID for the process that owns one of the sort files:
[root@sdw8 ~]# lsof /data2/primary/gpseg45/base/19979/pgsql_tmp/pgsql_tmp_slice10_sort_15673_0002.1
COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
postgres 15673 gpadmin 11u REG 8,48 1073741824 64424546751 /data2/primary/gpseg45/base/19979/pgsql_tmp/pgsql_tmp_slice10_sort_15673_0002.1The PID, 15673, is also part of the file name, but this may not always be the case.
5、
Use the ps command with the PID to identify the database and connection information:
[root@sdw8 ~]# ps -eaf | grep 15673
gpadmin 15673 27471 28 12:05 ? 00:12:59 postgres: port 40003, sbaskin bdw
172.28.12.250(21813) con699238 seg45 cmd32 slice10 MPPEXEC SELECT
root 29622 29566 0 12:50 pts/16 00:00:00 grep 15673On the master, check the pg_log log file for the user in the previous command (sbaskin), connection (con699238, and command (cmd32). The line in the log file with these three values should be the line that contains the query, but occasionally, the command number may differ slightly. For example, the ps output may show cmd32, but in the log file it is cmd34. If the query is still running, the last query for the user and connection is the offending query.
参考:
1、https://gpdb.docs.pivotal.io/43270/admin_guide/distribution.html