hive小文件的问题弊端以及合并
小文件的弊端
1、HDFS中每个文件的元数据信息,包括位置大小分块信息等,都保存在NN内存中,在小文件数较多的情况下,会造成占用大量内存空间,导致NN性能下降;
2、在读取小文件多的目录时,MR会产生更多map数,造成GC频繁,浪费集群资源;
3、现在大数据平台文件总数超过30亿,单个NS文件数超过4亿的时候,读写性能会急剧下降,影响到所有读写该NS的任务性能;
4、如果队列限制最大map数是20000,任务读取的分区文件数超过20000,需要加参数进行读取时小文件合并,或否则任务map数超过限制数直接被查杀。
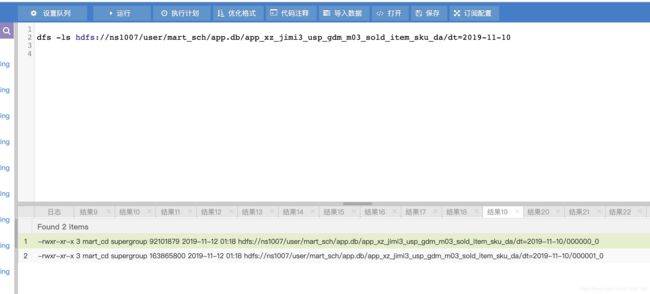
具体没有合并之前,查看一个分区的文件
在hive窗口下 dfs -ls hdfs://ns1007/user/mart_sch/app.db/app_xz_jimi3_usp_gdm_m03_sold_item_sku_da/dt=2019-11-10
(dfs -ls hive表的位置)
发现dt=2019-11-10分区下面有两个小文件(小文件一般是小于128M)
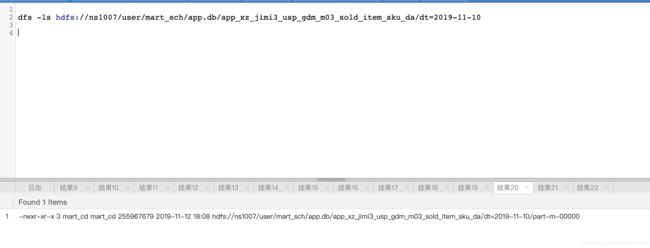
合并生成的hive表数据一个分区只有一个文件
具体合并生成小文件的示例脚本
所以在生成hive表数据的时候,可以用 merge_flag =True ,然后可以用 ,merge——type= 'mr' , merge_part_dir 指定需要合并的分区(也就是即将在sql中生成的partition)具体demo见下面的脚本
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import sys
import os
import datetime
sys.path.append(os.getenv('HIVE_TASK'))
from HiveTask import HiveTask
#now = datetime.datetime.strptime(sys.argv[1], "%Y%m%d%H%M%S");
now = datetime.datetime.now();
day_time_minus_2=now - datetime.timedelta(days=2);
day_str_minus_2=day_time_minus_2.strftime('%Y-%m-%d');
#前天 T-1
print (day_str_minus_2)
ht = HiveTask()
ht.calendar.setMonth(-1)
MonthFirst=ht.calendar.getMonthFirst()
sql_app_xz_jimi3_usp_gdm_m03_sold_item_sku_da= """
set mapred.output.compress=true;
set hive.exec.compress.output=true;
set hive.default.fileformat=Orc;
use app;
--跟新sku
INSERT OVERWRITE TABLE app.app_xz_jimi3_usp_gdm_m03_sold_item_sku_da PARTITION (dt='"""+ day_str_minus_2+ """')
SELECT item_sku_id, item_id, sku_name, brand_code, barndname_en
, barndname_cn, sku_valid_flag, item_valid_flag, item_first_cate_cd, item_first_cate_name
, item_second_cate_cd, item_second_cate_name, item_third_cate_cd, item_third_cate_name, major_supp_brevity_code
, pop_vender_id, shop_id
FROM (
SELECT item_sku_id, item_id, sku_name, brand_code, barndname_en
, barndname_cn, sku_valid_flag, item_valid_flag, item_first_cate_cd, item_first_cate_name
, item_second_cate_cd, item_second_cate_name, item_third_cate_cd, item_third_cate_name, major_supp_brevity_code
, pop_vender_id, b.shop_id
FROM
(
SELECT item_sku_id, item_id, sku_name, brand_code, barndname_en
, barndname_cn, sku_valid_flag, item_valid_flag, item_first_cate_cd, item_first_cate_name
, item_second_cate_cd, item_second_cate_name, item_third_cate_cd, item_third_cate_name, major_supp_brevity_code
, pop_vender_id, shop_id
FROM gdm.gdm_m03_sold_item_sku_da
WHERE (dt ='"""+ day_str_minus_2+ """'
AND sku_valid_flag = 1
AND sku_status_cd IN ('3001', '3002'))
) b JOIN
(SELECT vender_id, vender_type FROM app.app_xz_jimi3_usp_vender_mall_info_da_v2
WHERE dt='"""+ day_str_minus_2+ """') a
ON a.vender_id = b.pop_vender_id
AND a.vender_type = 1
;
"""
ht.exec_sql(schema_name = 'app', table_name = 'app_xz_jimi3_usp_gdm_m03_sold_item_sku_da', sql = sql_app_xz_jimi3_usp_gdm_m03_sold_item_sku_da, merge_flag = True, merge_part_dir =['dt='+ day_str_minus_2], merge_type='mr')